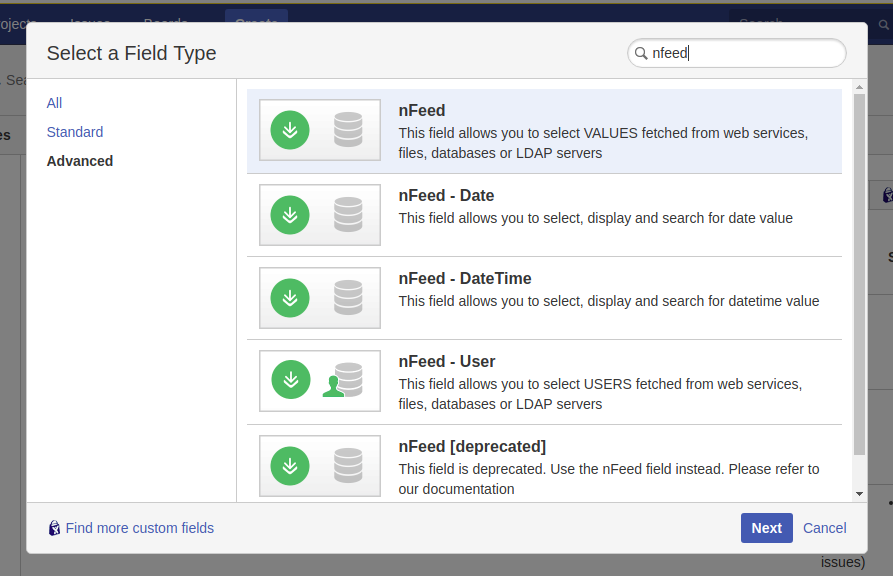
JQL & Worklog
In questo post andremo ad esaminare come possiamo sfruttare il JQL per ottenere informazioni sul Worklog delle issue Jira.
Cosa offre il JQL standard
Partiamo come sempre dallo standard e cerchiamo di descrivere nel dettaglio quello che abbiamo a disposizione sul Worklog.
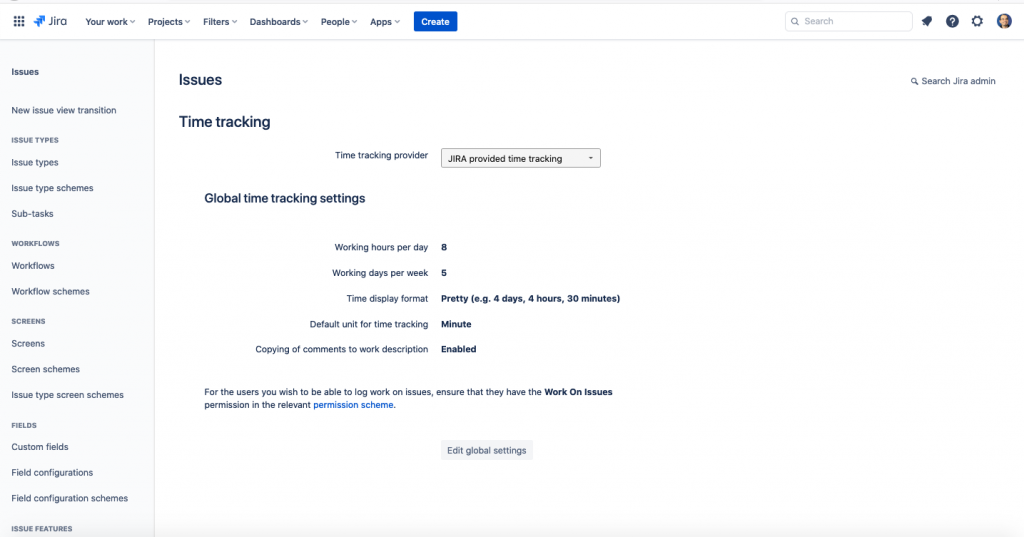
L’opzione deve essere attiva
Jira memorizza il Worklog nativamente. L’opzione deve naturalmente essere attivata (di default la abbiamo già abilitata) e questa possibilità la abbiamo a disposizione nella sezione di amministrazione della nostra instanza Jira (menù Issue).
I campi che referenziamo
Le informazioni che Jira memorizza sono le seguenti:
Original estimate
Si tratta della stima che andiamo a impostare nelle nostre issue. Il formato è :
1w 2d 3h 4m (1 settimana, 2 giorni, 3 ore, 4 minuti)
Remaining estimate
Nel caso di ore caricate, il campo ci indica quanta stima abbiamo ancora a disposizione. Il formato è:
1w 2d 3h 4m (1 settimana, 2 giorni, 3 ore, 4 minuti)
Time spent
Tempo speso dall’operatore nel task. Il formato è:
1w 2d 3h 4m (1 settimana, 2 giorni, 3 ore, 4 minuti)
Worklog comment
Commento che è stato inserito dall’operatore per specificare il dettaglio delle operazioni eseguite. Si tratta di una stringa.
Worklog date
Data in cui è stata svolta l’attività. Si tratta di una data.
Work ratio
Percentuale di lavoro svolta (in %)
workRatio = timeSpent / originalEstimate) x 100
Si tratta di un numerico.
Che operazioni possiamo fare?
Con i primi tre campi che ho indicato, possiamo verificare quali issue presentano :
- Original estimate – Verificare quali issue presentano un particolare valore di stima impostata (valore esatto oppure maggiore o inferiore ad un valore)
- Remaining estimate – Verificare quali issue presentano una stima rimanente pari ad un valore esatto o maggiore o inferiore ad un valore
- Time spent – Verificare quali issue presentano un worklog caricato pari ad un valore esatto o maggiore o inferiore ad un valore;
In questo caso possiamo eseguire delle interrogazioni JQL del tipo:
<CAMPO> = <Valore> | <CAMPO> > <Valore> | <CAMPO> < <Valore>
<CAMPO> != <Valore> | <CAMPO> >= <Valore> | <CAMPO> <= <Valore>
esempi di alcuni possibili interrogazioni
Alcuni esempi
Riporto alcuni esempi di interrogazioni JQL per capire che cosa possiamo arrivare ad ottenere.
Capire quali issue per cui non abbiamo un worklog caricato
project = <KEY> and timespent is EMPTY
Capire quali issue presentano un worklog maggiore di un determinato limite (8 ore)
project = <KEY> and timespent > 8h
Capire quali issue presentano una stima superiore al tempo usato
project = <KEY> and timespent > 0 and remainingEstimate > 0
Cosa non possiamo fare
Non possiamo confrontare questi campi tra di loro. Se ad esempio impostiamo un JQL come nella seguente immagine:
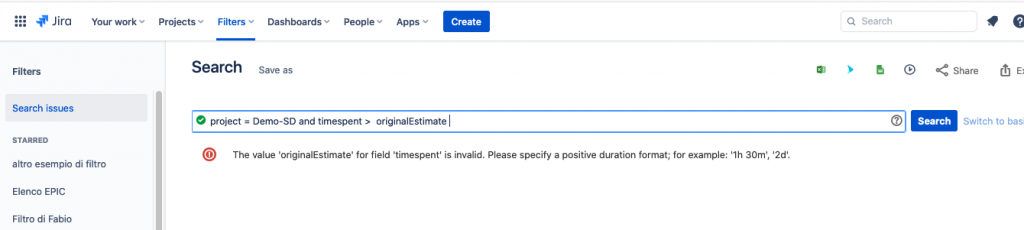
lo standard purtroppo non ci supporta e ci restituisce un errore.
Per i restanti campi ….
…. possiamo eseguire delle operazioni di diverso tipo. Andiamo nel dettaglio.
Worklog Comment
Quando inseriamo un worklog, abbiamo la possibilità di poter inserire una stringa per descrivere il tipo di attività. Le operazioni che possiamo eseguire possono essere quelle di verificare la presenza di determinate stringhe usando l’operatore ~
worklogComment ~ "<qui inseriamo il nostro testo>"Esempio di utilizzo
Quando vogliamo accertarci che esista un worklogrelativo ad un lavoro svolto ad una determinata data, allora andiamo a referenziare questo campo, sfruttando tutte le funzioni relative alle date.
worklogDate = "<Inserisci_qui_la_data>"Il formato della data è: yyyy-mm-dd
Esempio di utilizzo
Worklog Date
Work ratio
Il campo esprime la percentuale di lavoro svolto rispetto alla stima impostata. In questo caso è particolarmente utile per capire la % di lavoro svolto dall’operatore.
workratio < <valore_numerico>
Esempio di utilizzo
Nella seguente immagine vediamo un utilizzo interessante:
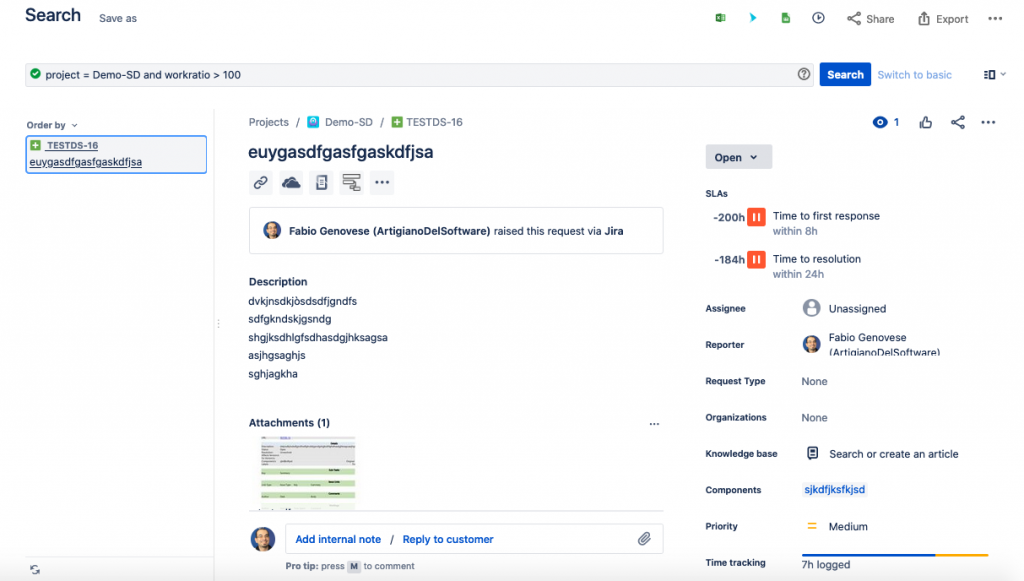
In questo caso vediamo una issue in cui abbiamo stimato 5 ore ma abbiamo speso 7 ore con un surplus di 2 ore rispetto alla stima. In questo caso, abbiamo visto un esempio di come rintracciare le issue che sono risultate sottostimate.
Conclusione
Abbiamo visto alcuni esempi di utilizzo dello standard di JQ, dedicati al worklog. Se volete avere maggiori ragguagli, vi suggerisco di acquistare il mio libro su JQL:
Reference
Altre informazioni sono reperibili alla seguente pagina.






































/GettyImages-468837861-56c5c0c93df78c763fa5d925.jpg)