In questo post sarà fornito un esempio di come realizzare, attraverso l’utilizzo combinato di Confluence e Jira, una buona gestione delle risorse riusabili in uso presso una azienda. Si rimanda al seguente post blog, dove viene fornita una prima indicazione di come sia possibile utilizzare Jira e Team Calendar.
Per risorse riusabili si intende:
- automezzi aziendali (macchine/furgoni);
- pc notebook
- borse di attrezzi
- sale riunioni
- carte di credito aziendali
- etc
Nel post sarà mostrato un esempio di utilizzo di Confluence e Jira, al fine di realizzare la gestione di sale riunioni. Il concetto può essere tranquillamente esteso anche ad altre risorse.
Prerequisiti
Per realizzare quanto indicato, si deve disporre di:
Il primo sarà utilizzato prevalentemente per la visualizzazione, su apposite pagine della allocazione delle risorse riusabili.
Il secondo sarà utilizzato prevalentemente per gestire tutte le richieste, il Workflow di avanzamento delle stesse e l’indicazione dei vari dati.
Passo 1 – Configurazione
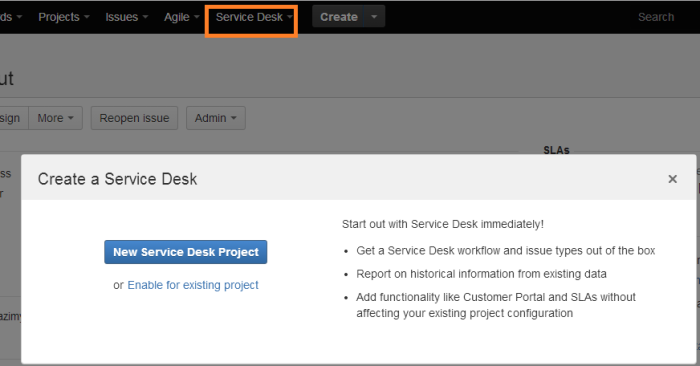
Il primo passo è configurare i due applicativi affinché possano comunicare. Questo link fornisce le indicazioni. Il secondo passo è quello di creare un Service Desk su Jira. Questo lo si ottiene attivando la relativa autocomposizione dal menù Service Desk , come mostrato nella figura sottostante.
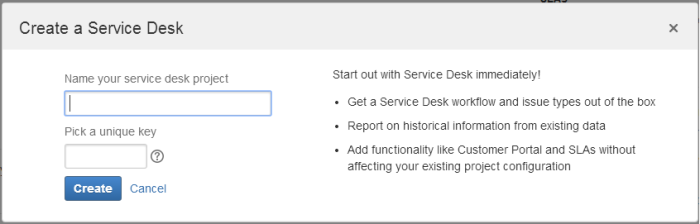
Selezionare New Service Desk Project, quindi specificare i parametri del progetto (nome progetto e chiave).
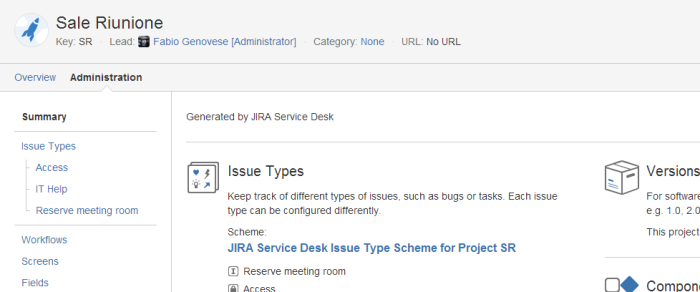
Il Service Desk sarà quindi generato.
Fondamentalmente, questo crea un progetto sotto Jira, impostandolo in maniera opportuna affinché possa essere utilizzato per gestire delle richieste. L’unica differenza, in questo caso, è che queste richieste dovranno:
- presentare un periodo temporale (data/ora inizio e data/ora termine);
- presentare degli attributi, che danno la possibilità di poter identificare la risorsa riusabile. Nel nostro esempio, si tratta del numero della sala riunione ;
Fatto ciò, arriva la parte più difficile: Eventuale configurazione del Workflow, qualora siano necessarie ulteriori stati aggiuntivi nella sequenza di approvazione, oltre che aggiungere dei campi alle segnalazioni, affinché diano la possibilità di poter impostare le informazioni aggiuntive che sono necessarie per la gestione della risorsa riusabile. In questo esempio sarà utilizzato un Workflow standard, generato dalle procedure di autocomposizione, fornendo i dati i riferimenti alla manualistica Atlassian per poter eseguire le modifiche.
L’aggiunta dei nuovi campi non è particolarmente problematica. Basta semplicemente andare in configurazione del progetto, associato al Jira Service Desk precedentemente creato (nel nostro esempio progetto Sale riunioni, chiave SR).
Selezionare la sezione di amministrazione:
quindi modificare il tipo di Issue Type per il Service Desk, creando un tipo opportuno di Issue. L’autocomposizione imposta alcuni tipi di issue. Dal Menù Action , in alto a destra, selezionare Edit Issue e procedere con la generazione del nuovo tipo: Reserve Meeting Room . Selezionare Add Issue Type . Questo attiverà la funzione che genera il nuovo tipo:
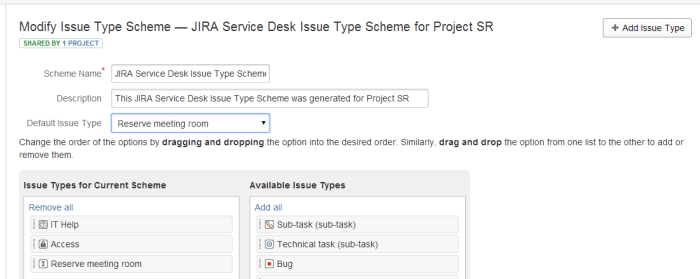 mostrado l’autocomposizione:
mostrado l’autocomposizione:
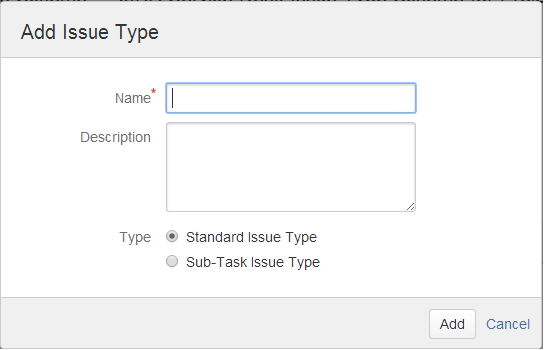
Deve trattarsi di un Standard Issue Type. Fatto ciò, lo selezioniamo come il tipo di default di Issue da generare.
Fatto ciò, da qui in avanti possiamo impostiare il workflow.
Sempre dalla schermata delle Issue Type attivare, come mostrato in figura:
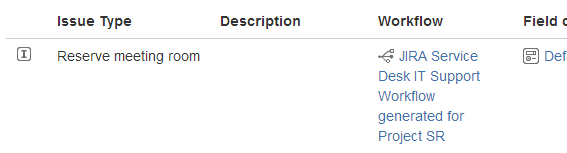
dove si accede alla pagina di gestione del workflow. Selezionare il tasto EDIT per eseguire l’editing del workflow

Si segnala il seguente link, per avere maggiori informazioni su come lavorare con il workflow di Jira.
A questo punto, inseriamo dei campi custom, nella issue, in modo da poter gestire le informazioni che ci identificano, in maniera univoca, le risorse riusabili. Nel nostro caso si tratta del nome delle sale riunioni, della data/ora di inizio della riunione e data/ora termine della stessa.
Selezionare la sezione Fields quindi editare i campi della Issue selezionando Actions –> Edit fields .
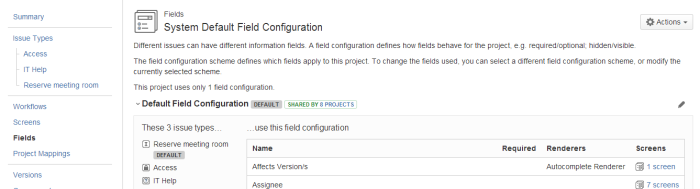
Selezionare la sezione Custom Fields, quindi procedere con l’aggiunta dei seguenti campi:
- Sale Riunioni
- Inizio Riunione
- Termine Riunione
Mentre gli ultimi due campi devono essere configurati come DateTime, il primo campo deve essere configurato affinché fornisca i dati da una lista ben definita:
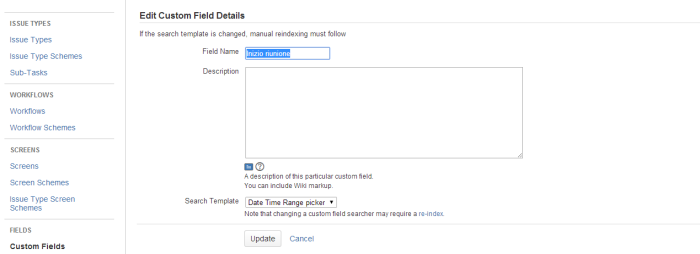
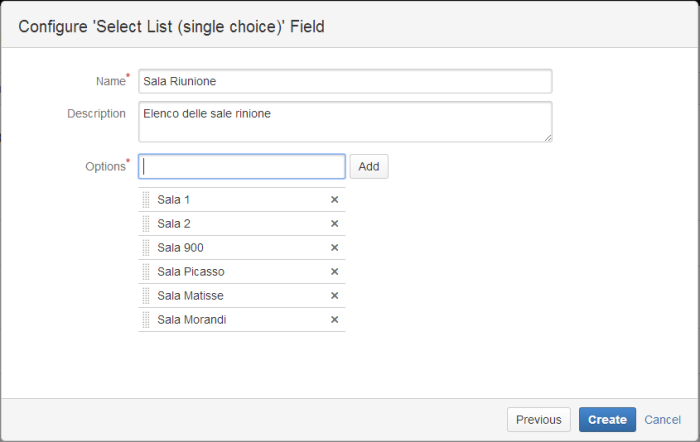
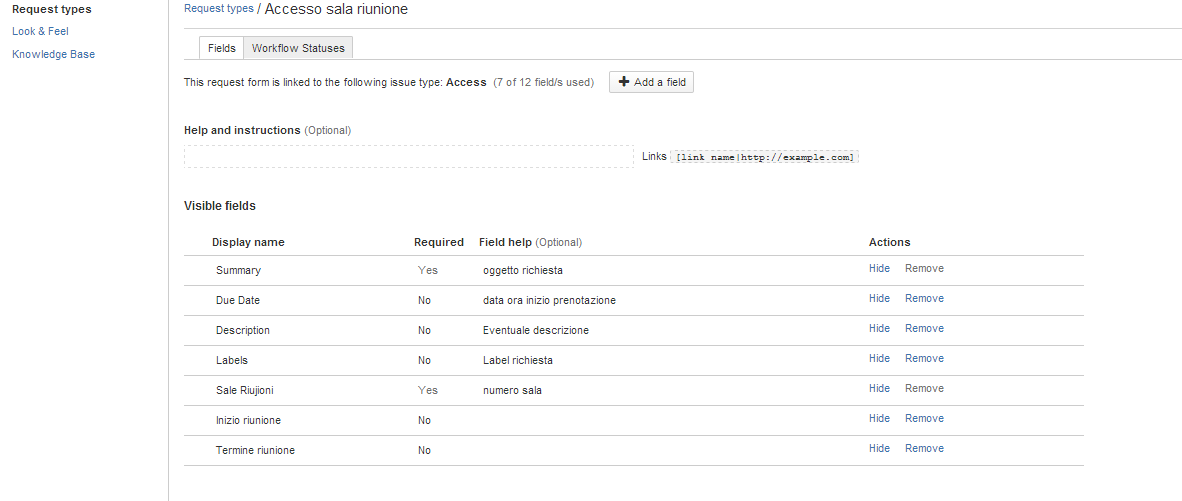
Come ultimo passo, occorre indicare quali campi deve compilare l’utente in fase di richiesta. Questo viene eseguito attraverso la configurazione del portale del Service Desk. Dal menù Service Desk –> Sale Riunione accedere alla pagina di gestione delle varie richieste.
Selezionare Customer Portal , in modo da impostare quali richieste può generare un utente. Quindi impostare le possibili richieste, accertandosi di specificare, nell’ambito della richiesta, i campi che devono essere valorizzati:
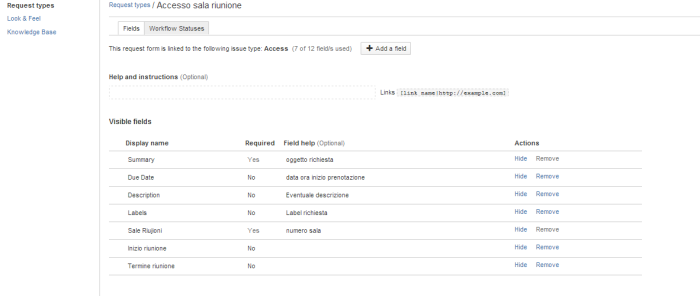
A questo punto possiamo iniziare a mettere a disposizione degli utenti la possibilità di poter richiedere l’utilizzo delle sale riunioni.
Passo 2 – Utilizziamo il tutto
Iniziamo ad usare il sistema per riservare le sale riunioni.
Dal menù Service Desk –> Nuova richiesta si entra nella pagina di selezione:

dove troviamo il link alla funzione per creare la richiesta. Doppio click su Accesso sala riunione per impostare i campi della richiesta, come mostrato nella seguente figura:
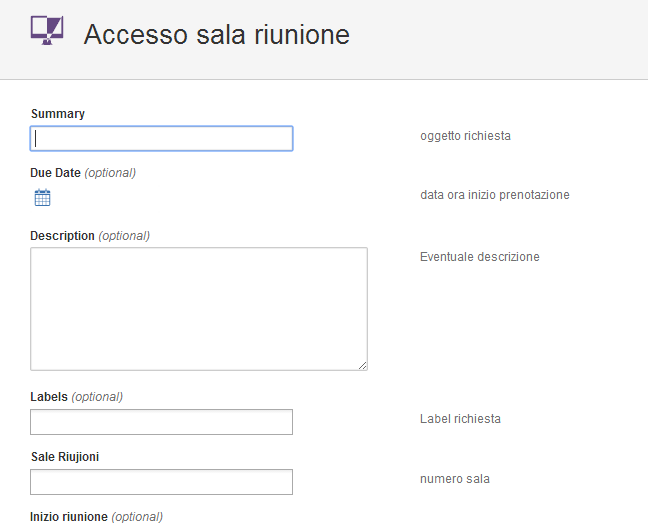
Confermando il tutto, la richiesta inizia il suo iter. Da Jira possibile esaminare tutte le varie fasi, come se si trattasse di normali issue Jira. Dal portale di gestione Service Desk, il responsabile del progetto accetterà o meno la richiesta. Il sistema di gestione delle mail si occuperà di avvisare gli utenti dell’accettazione o meno della richiesta stessa.
Come rendiamo visibile agli utenti il tutto??
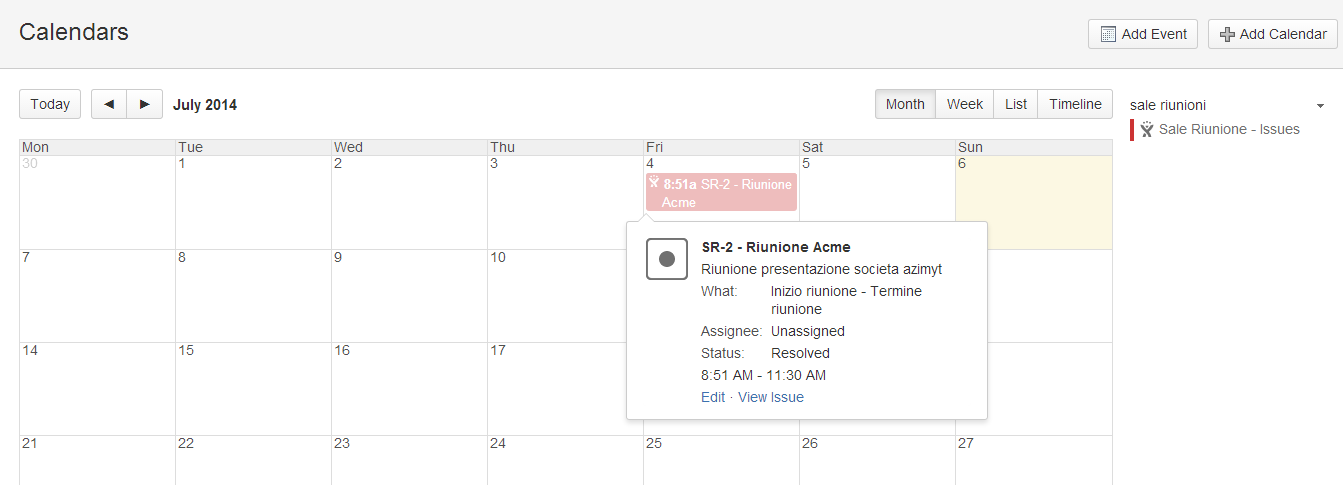
Adesso, possiamo pubblicare, su di una pagina di apposito space o sullo space pubblico, una macro che pubblica su di un Calendar, dedicato a questo scopo, queste informazioni. Nel post blog pubblicato in passato, è possibile vedere come poter collegare Team Calendar a Jira. Seguendo le semplici istruzioni, questo è il risultato che otteniamo:
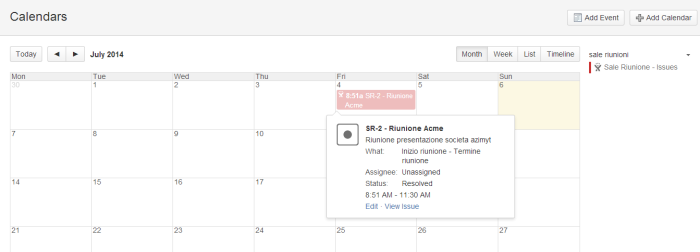
Conclusioni
Ecco un buon esempio di come poter utilizzare Confluence e Jira per poter gestire delle risorse riusabili. Tuttavia, proprio dall’ultima immagine, notiamo un piccolo difetto: Non possiamo visualizzare tutti i nuovi campi aggiunti. Infatti non riusciamo a vedere di che sala riunioni si tratta: occorre entrare nel dettaglio della Issue per poterla vedere. Tuttavia è un buon inizio per arrivare ad avere una prima gestione, centralizzata, delle risorse riusabili.
La configurazione non è proprio agevole, ma una volta impostata, gli utenti possono usare lo strumento senza nessuna difficoltà, in maniera semplice con pochi click.
Rimaniamo in attesa di ulteriori sviluppi sui vari componenti indicati. Sono sicuro che la Atlassian saprà sicuramente stupire. Fino a qualche anno fa, Jira non conosceva neanche il concetto di risorsa, mentre con l’introduzione del Jira Service Desk, ha finalmente introdotto un concetto indispensabile nelle aziende.
Referenze e letture varie
Si suggerisce la lettura dei seguenti link come ulteriore approfondimento:
- Gestione delle ferie – Link
- Uso combinato Team Calendar – Jira – Link