Gestire dei supporti con Monte Ore
Esempio di utilizzo
In questo post vedremo un esempio di come poter gestire un lavoro basato su un monte ore. Questo è un esempio di come realizzare il tutto sfruttando i prodotti della Atlassian.

Di cosa abbiamo bisogno?
- JIRA, per tracciare le attività e i tempi di esecuzione;
- CONFLUENCE, per dettagliare le attività svolte, documentare il tutto e e fornire dei dettagli operativi
Vediamo nel dettaglio le due parti da configurare.
JIRA
Cominciamo da JIRA. Sfruttando il concetto di TASK e SUBTASK , procediamo come segue:
- Creiamo un progetto ad hoc, per tracciare le attività del nostro cliente;
- Creiamo un TASK. Ci servirà come contenitore generale per tutte le attività che andremo a svolgere nel nostro Monte Ore;
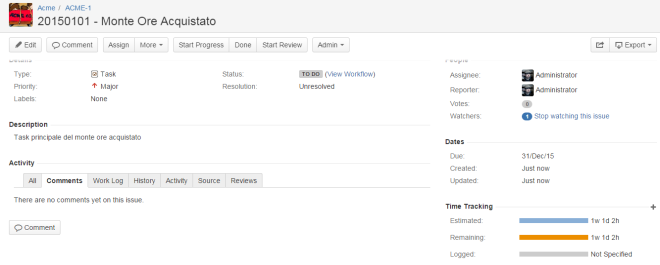
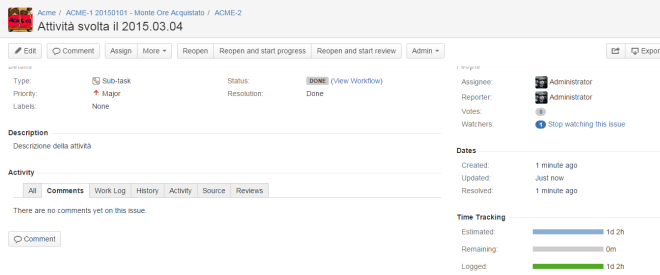
- Creeremo una serie di SUBTASK , uno per ogni attività che andiamo ad eseguire, in cui dettaglieremo ogni singola attività svolta nell’ambito del monte ore.
Sul TASK andremo ad inserire il totale del monte ore acquistato dal cliente (Dettaglio: Sezione Time Tracking). 
Sui SUBTASK , inseriremo, sia come ore stimate (Original Estimate) che come ore effettive (Work LOG), il totale delle ore che sono state dedicate alla attività. Come sempre, inseriamo sui commenti, tutte le annotazioni che riteniamo necessarie, quali le operazioni che sono state svolte, i risultati delle analisi, etc. Nella description, inseriremo la richiesta che è stata operata da Cliente.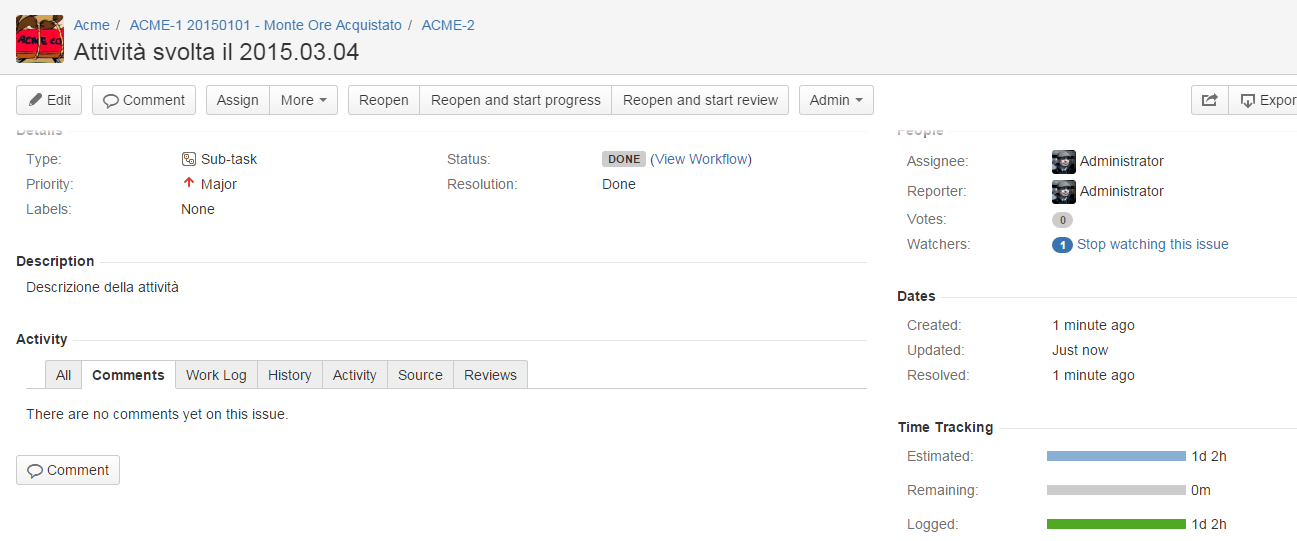
Risultato
Con questa configurazione, controlliamo sempre il monte ore residuo in maniera semplice. Basta semplicemente che teniamo sott’occhio il Time Tracking, del TASK generale. Nei vari SUBTASK abbiamo il dettaglio di ogni operazione di supporto richiesta dal cliente, con tutto ciò che ne riguarda. Con questo modo di procedere, abbiamo la possibilità di gestire il monte ore, tenere sotto controllo e documentare le attività svolte, e monitorare i tempi di reazione. In questo modo possiamo anche consigliare il cliente su come scegliere il monte ore adeguato per le sue esigenze.
Confluence
Passiamo adesso a configurare Confluence. Come prima cosa, seguendo i consigli del post (come creare una scheda del cliente in Confluence), possiamo creare una sottopagina, con le indicazioni del progetto (seguendo la stessa logica) e successivamente, nella pagina del progetto Monte Ore, indicare la cronologia delle attività dettagliate. In questo caso abbiamo diverse possibilità:
- Space, in cui inseririamo le informazioni del cliente. Qui andremo ad inserire tutte le altre informazioni;
- Blog dello space. Qui andiamo ad indichicare le attività svolte di una o più giornate. Consiglio il blog in quanto più comodo per redigere il dettaglio delle attività. Ci sono poi delle macro che consentono di poter visualizzare gli ultimi post e danno evidenza delle ultime attività.
- Dedichiamo una pagina riassuntiva per tutti i monte ore acquistati e tante sottopagine per ogni singolo monte ore acquistato. Sulla pagina principale abbiamo i riassunto di tutti i monte ore. Sulla sottopagina abbiamo il dettaglio dello specifico monteore. In questa pagina andremo ad inserire l’elenco dei SUBTASK del TASK principale, di modo da avere la situazione documentata.
Una variante potrebbe essere quella di avere delle singole pagine per intervento. Questo potrebbe risultare più comodo del BLOG. Teniamo conto che, come indicato in questo post, non esiste ancora la possibilità di poter associare un TEMPLATE ad un post blog
Questo è il risultato che si può arrivare ad ottenere

Suggerimento
Una ulteriore operazione che si può fare, è quella di mettere a disposizione degli utenti un ulteriore strumento, ovvero un Knowledge Base, ovvero uno space dove sono raccolte una sequenza di informazioni, secondo un determinato stile, che consentono di poter mettere a disposizione conoscenza
Conclusioni
Abbiamo visto, in questo post, come possiamo realizzare un sistema di gestione monte ore, sfruttando le funzionalità che Confluence e JIRA mettono a disposizione. Questo è solo uno dei tantissimi esempi di come possiamo sfruttare le potenzialità di questi prodotti e di come possiamo combinarli per ….. soddisfare le nostre necessità. Ma come sempre, questo non è altro che un punto di partenza per altre idee. La fantasia è il nostro solo limite 🙂