Riportiamo con molto piacere una notizia dall’ecosistema degli addon. La Spagnola Tecnofor ha acquisito Shared Estimation, un addon precedentemente conosciuto come Open Poker
Fonte: MrAddon Blog/Tecnofor
Questa acquisizione estende il parco addon, già molto importante, di Tecnofor con un addon interessantissimo. Si tratta di un addon che non abbiamo avuto ancora il piacere di recensire ma che presto diventerà conoscenza dell’Artigiano.
L’addon ci permette di poter affrontare e risolvere una delle problematiche che ogni giorno le aziende affrontano: la complessità di migliorare le stime delle attività. Nello scenario più comune (sicuramente è lo scenario che abbiamo visto in varie situazioni) la persona responsabile della stima non è la persona che esegue il lavoro, non ha esperienza precedente o non possiede le conoscenze tecniche necessarie oppure imposta la stima in base alle indicazioni ricevute (a volte anche per sentito dire). Non diciamo nulla di nuovo.
Queste sono le nostre reazioni quando dobbiamo fare le stime….
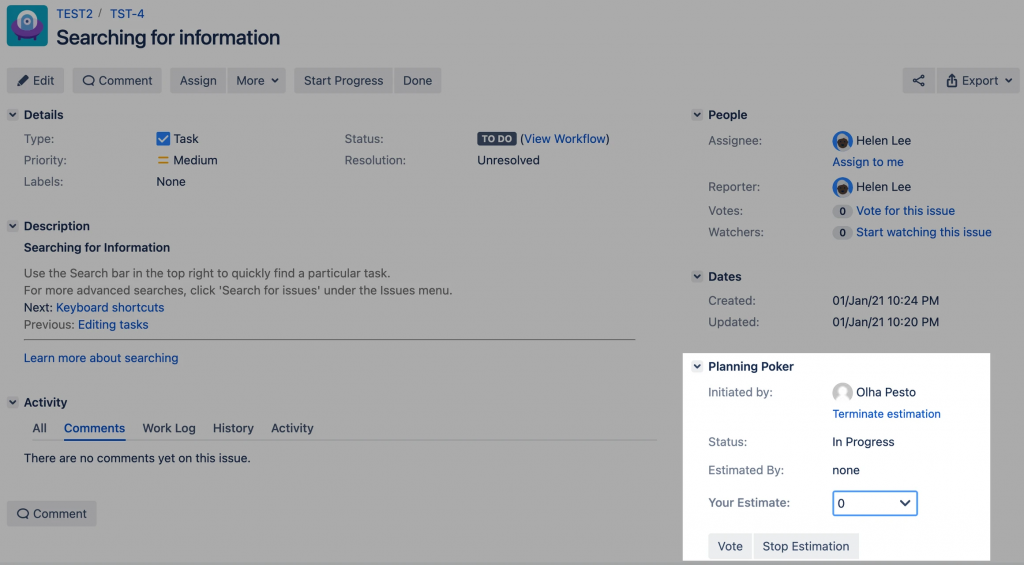
Shared Estimations semplifica il processo di stima consentendo ai team di fornire facilmente le proprie opinioni sulle stime delle attività, il tutto in formato anonimo, basato sulla percentuale, perfettamente integrato in Jira, un popolare strumento di gestione dei progetti. Della serie: ‘chiedi l’aiuto da casa‘.
Un esempio di come l’addon lavora.
Conclusioni
Una notizia molto positiva. Tecnofor si rafforza nell’ecosistema con un pezzo da 90 (come diciamo in Italia) :-D. Chiediamo anche noi l’aiuto da casa ma al grande Chuck Norris. Che cosa ne pensa?
Andiamo quindi al sicuro.
Il nuovo campo Teams: cosa e’, come funziona
Annunciato a Teams23 a Las Vegas, il nuovo campo Teams e da poco disponibile nelle nostre installazioni Cloud. Vediamo in questo post in che cosa consiste, come funziona e che cosa permette. Entriamo in modalità ricerca.
Set Explore mode = on
Subito al sodo
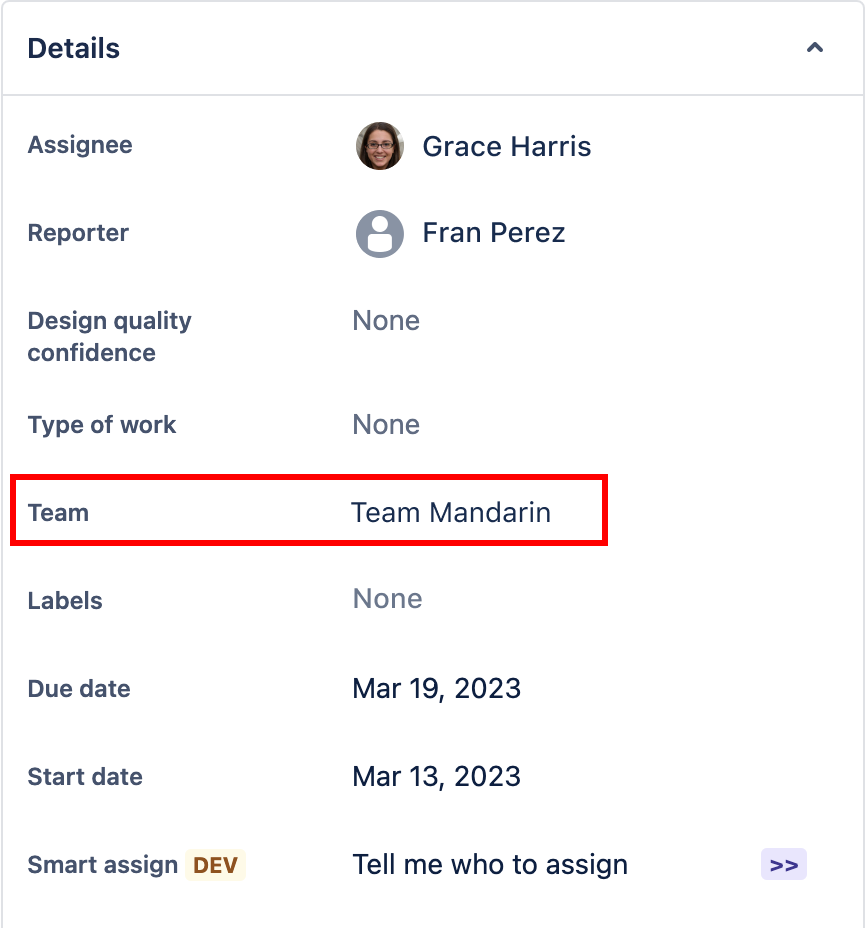
Richiesto a gran voce da tutti, questo campo permette di poter creare dei Team trasversali da poter usare nei nostri progetti, sia per assegnare le issue a gruppi (in precedenza era necessario usare altri mezzi per realizzare questa funzione) oltre che implementare delle notifiche, ma non solo. Vedremo come nei prossimi paragrafi.
Per chi non ha ancora aggiunto il campo negli screen, sono visualizzati questi messaggi
Questo nuovo campo ci permette di avere una marcia in più rispetto ai singoli gruppi. I Teams sono dei gruppi di utenti che possono essere trasversali rispetto ai gruppi che abbiamo definito nella nostra anagrafica utenti. Questi sono gestiti da una apposita funzione che non si trova ella sezione di amministrazione ma direttamente nella nostra istanza, e sono usati da più funzioni.
Questa funzione è stata derivata da Advanced Roadmap (il vecchio Portfolio for Jira), dove questa possibilità era già disponibile. Gli utilizzatori di Advanced Roadmap infatti riuscivano ad eseguire delle assegnazioni a Teams delle issue. Adesso questa funzione non e’ sola esclusiva della pianificazione, ma anche del lavoro di tutti i giorni e di tutti gli utenti.
in questa nuova gestione, i Teams hanno una definizione più ricca rispetto ai gruppi. Possiamo avere delle schede personalizzate e dedicate alle persone che li compongono.
Fonte: Documentazione Atlassian
Interessante, ma che altro e’ possibile?
Un apposito Campo di sistema è a nostra disposizione, come qualsiasi altro campo, ma con una marcia in più. Questo campo ci permette di implementare una assegnazione a gruppi, con l’opzione di poterlo usare delle mentions per implementare notifiche. In aggiunta possiamo usarlo anche nelle nostre importanti regole di automazione.
Adesso la domanda difficile: cosa non è possibile fare?
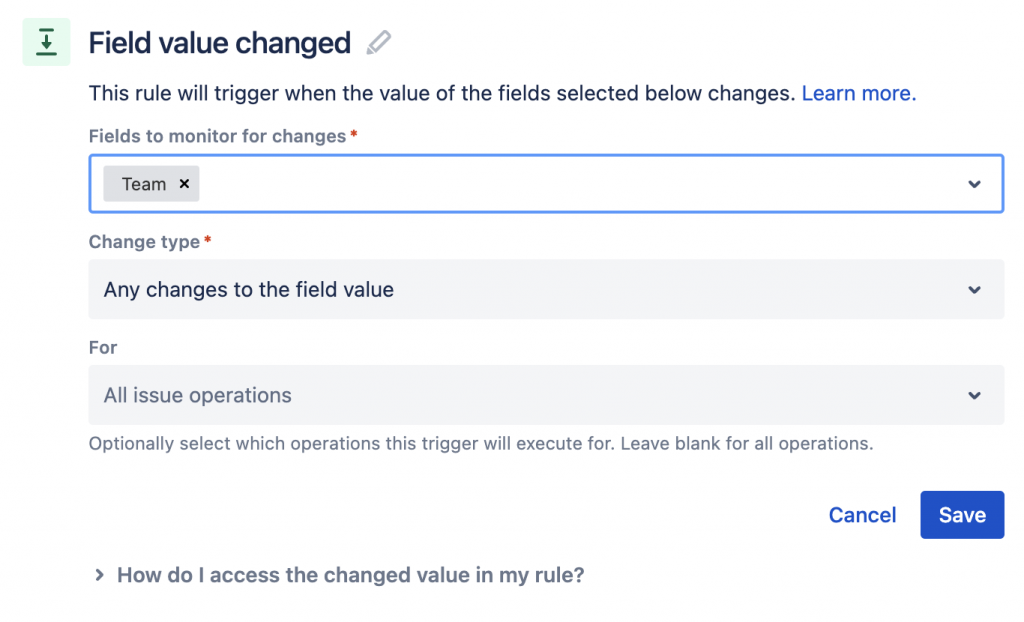
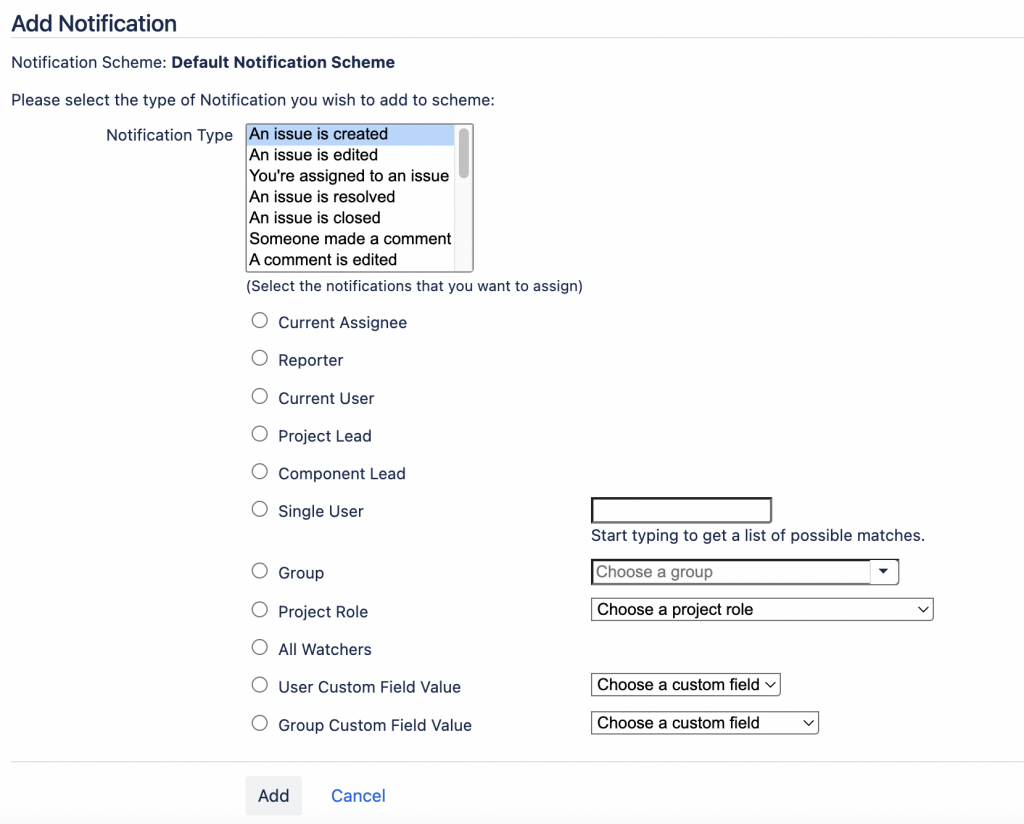
Il nuovo campo non e integrabile con il notification scheme. Questo significa che le notifiche devono essere gestite in maniera differente: mentions o regole di automation. Questo è più scomodo perché non si innesta nel flusso STANDARD.
La pagina che Jira mette a disposizione quando aggiorniamo una notifica. Le possibili scelte non sono cambiate
Come vediamo non abbiamo alcuna possibilità di scelta del team. Quindi non riusciamo in alcun modo (almeno per il momento) a reindirizzare le notifiche attraverso i canali standard.
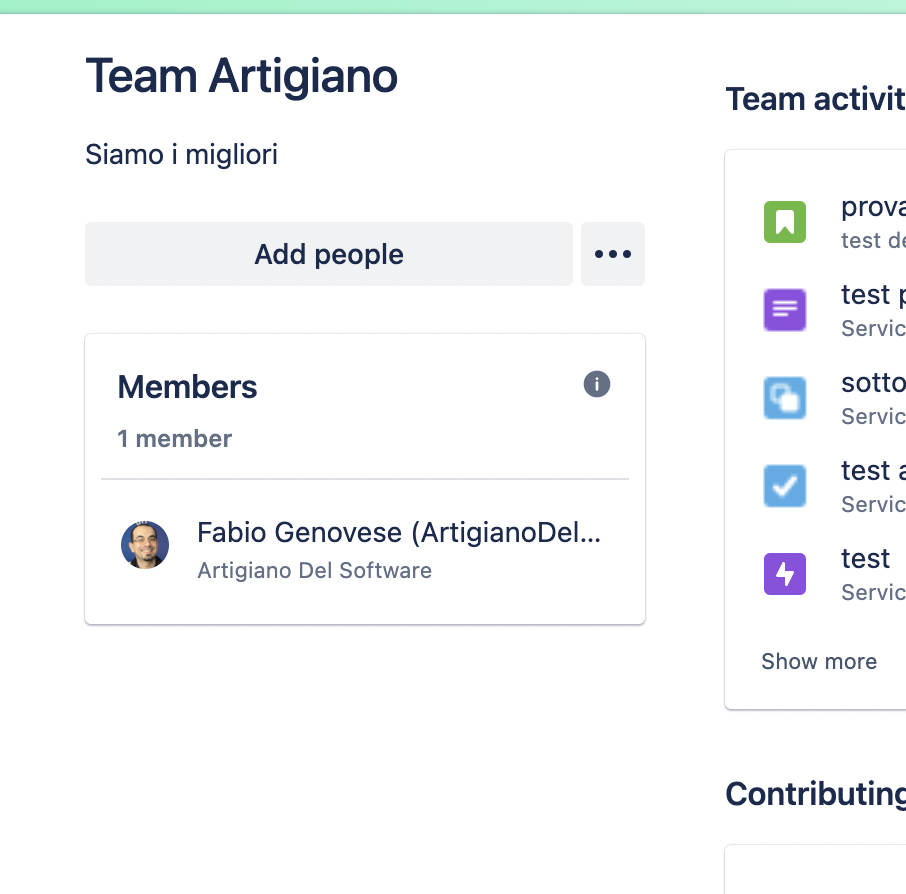
L’unico sistema rimane le mentions. Infatti se definiamo un Team
In questo caso mi sono creato il mio team ufficiale
il risultato che otteniamo è:
Cosa vediamo nelle mentions
Conclusioni
Abbiamo una funzionalità interessante, che introduce alcuni concetti che prima non erano presenti in Jira. Questo è sicuramente importante ma, secondo il mio modesto parare, occorre ancora aggiungere delle componenti e delle funzioni ai Team. Siamo agli inizi e sono sicuro che Atlassian non ci deluderà in questo.
Proseguiamo con le analisi mostrando i risultati su Confluence. Verifichiamo cosa viene offerto da Atlassian per Confluence.
esplorazione alchemica
Nel precedente articolo abbiamo visto quali novità introduce Jira, e ci siamo fatti una idea di quali possibilità sono offerte. Adesso andiamo ad esaminare quali possibilità sono offerte su Confluence.
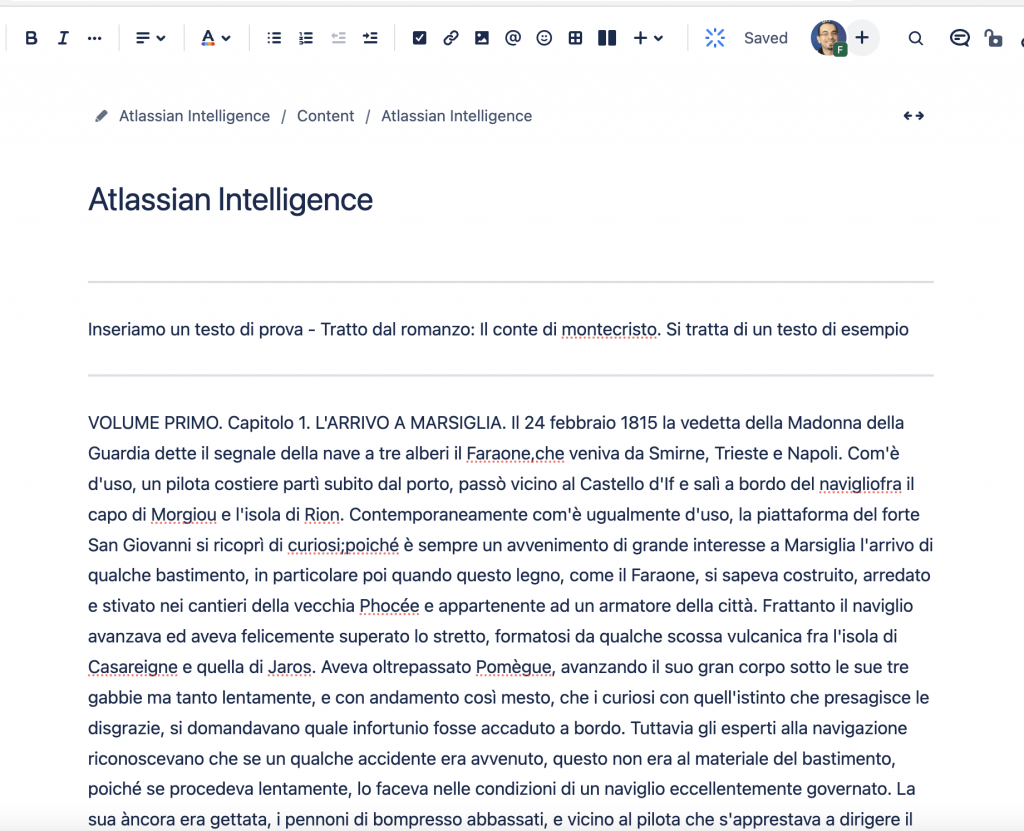
Anche in questo caso sfruttiamo la nostra installazione Premium per vedere cosa è possibile fare. Creiamo uno space ad hoc e andiamo ad analizzare. Ho quindi creato una pagina all’interno dello Space dove ho riportato i primi 2 capitoli del romanzo Il Conte di Montecristo. Quale esempio migliore.
Uno stralcio del testo che ho copiato. Mi serviva un testo da usare come banco di prova
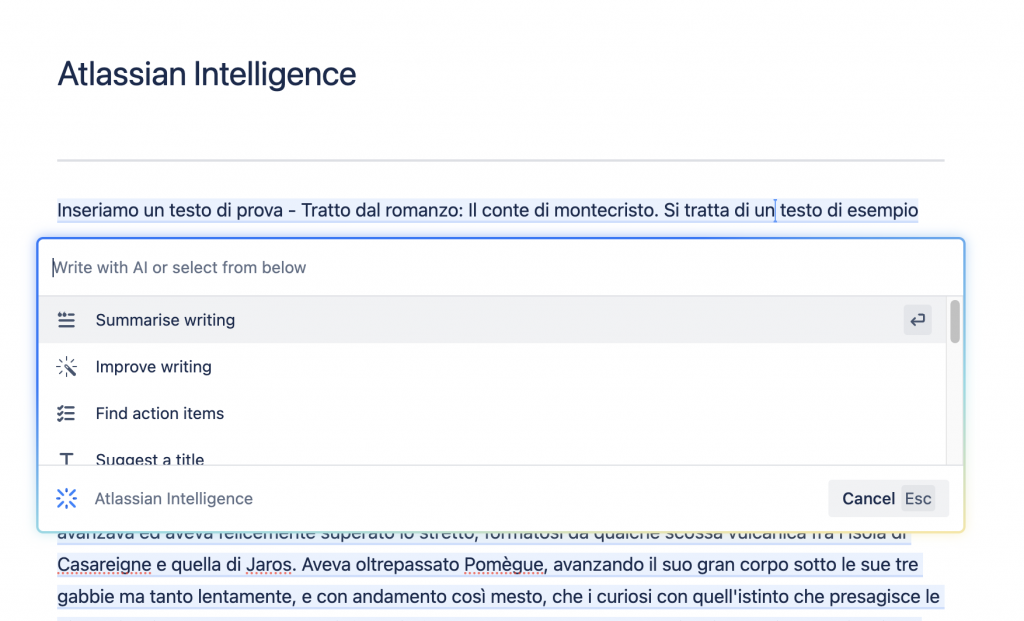
Ho chiesto quindi ad Atlassian Intelligence di fare un riassunto dello scritto. L’opzione è presente, come possiamo vedere nella immagine successiva:
Alcune delle opzioni offerte
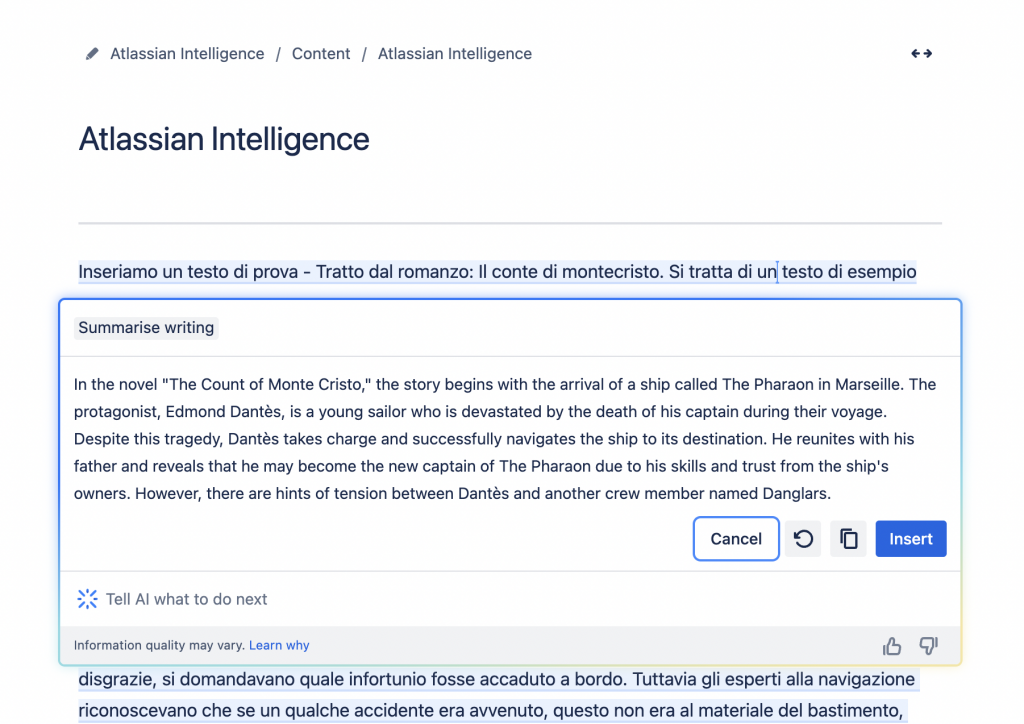
Questo è il risultato.
Ecco un riassunto che è stato prodotto
Il risultato è in inglese, ma risulta notevole. In poche righe ha riassunto quanto ho riportato nella pagina. Ma non solo. Una volta confermato la pagina ho anche usato la funzione Define, per trovare le definizioni. Questi i risultati:
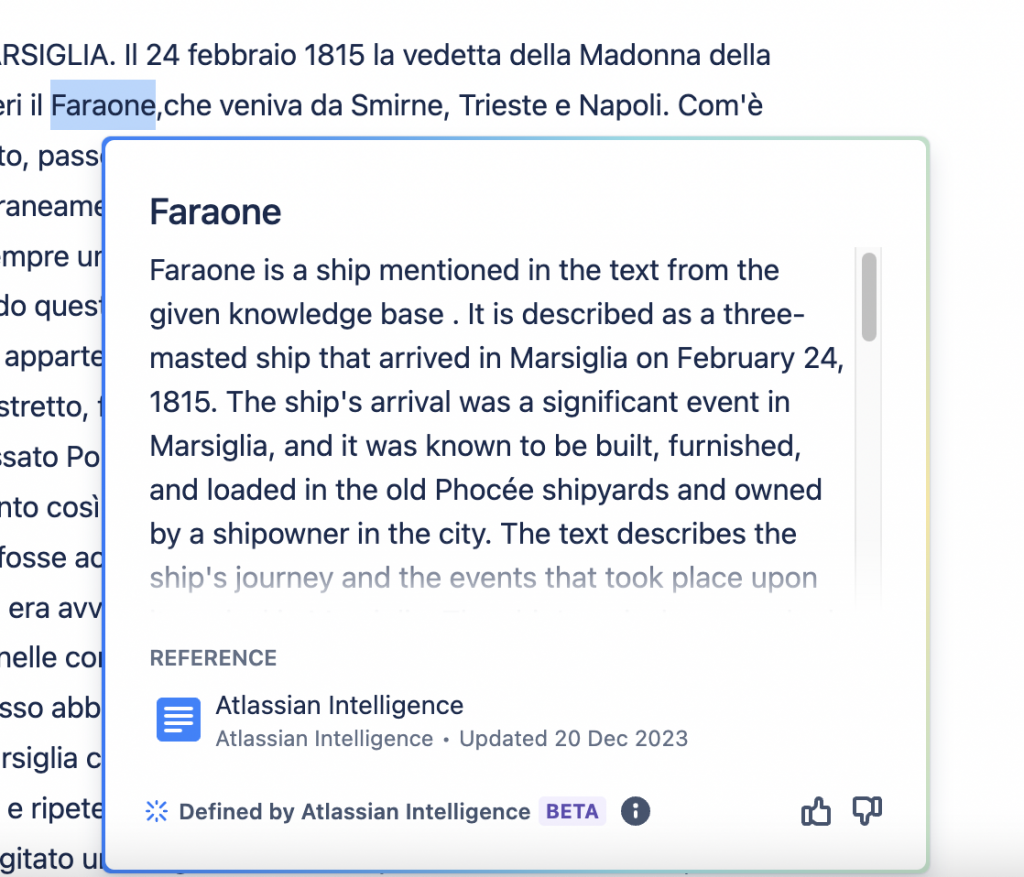
U(n esempio di definizione
Un esempio di definizione
E’ interessante notare che riesce a identificare le definizioni anche di città e di nomi di navi, oltre che le pagine di riferimento della documentazione di Confluence dove il termine viene indicato. Questo mi fa pensare che Atlassian Intrelligence si riferisca anche a dati esterni alla organizzazione. Interessante come avviene questa sinergia.
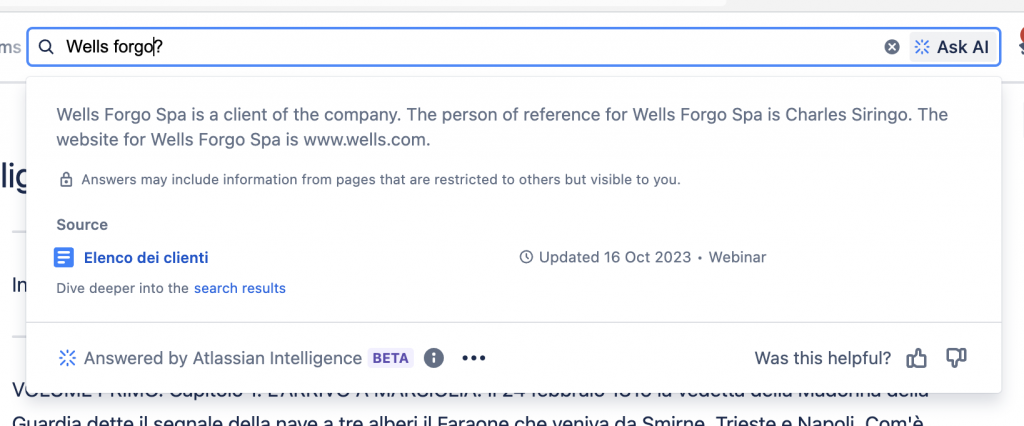
Possiamo anche usare questa funzionalità anche per la ricerca sui documenti e trovare le risposte direttamente dalla barra di ricerca…… in questo caso sto utilizzando le informazioni che ho preparato per uno dei webinar di Atlassian Espresso
In questo caso ho usato il nome di fantasia Wells Forgo…..
Atlassian Intelligence ha indentificato il dociumento, il nome e la definizione. Ha anche citato il nome della persona di riferimento, Charles Siringo, persona storica che mi sono permesso di citare in questo webinar. Per chi non la conosce, suggerisco di andare a cercarne la storia. Sono sicuro che troverà delle ottime sorprese.
Conclusione
Come possiamo riassumere questo risultato. Direi con una sola parola…. S P E T T A C O L O. Queste nuove opzioni ci permettono di ottimizzare la nostra conoscenza aziendale, ma non solo. Abbiamo delle caratteristiche che se ben sfruttate, ci permettono di poter ottenere dei risultati impensabili. Non vedo l’ora che sia resa operativa e definitiva su tutte le installazioni: soino sicuro che con il tempo le funzionalità aumenteranno e diventeranno sempre più interessante
Domande & Risposte. Abbiamo bisogno di una licenza Confluence per usare la KB su Jira Service Management?
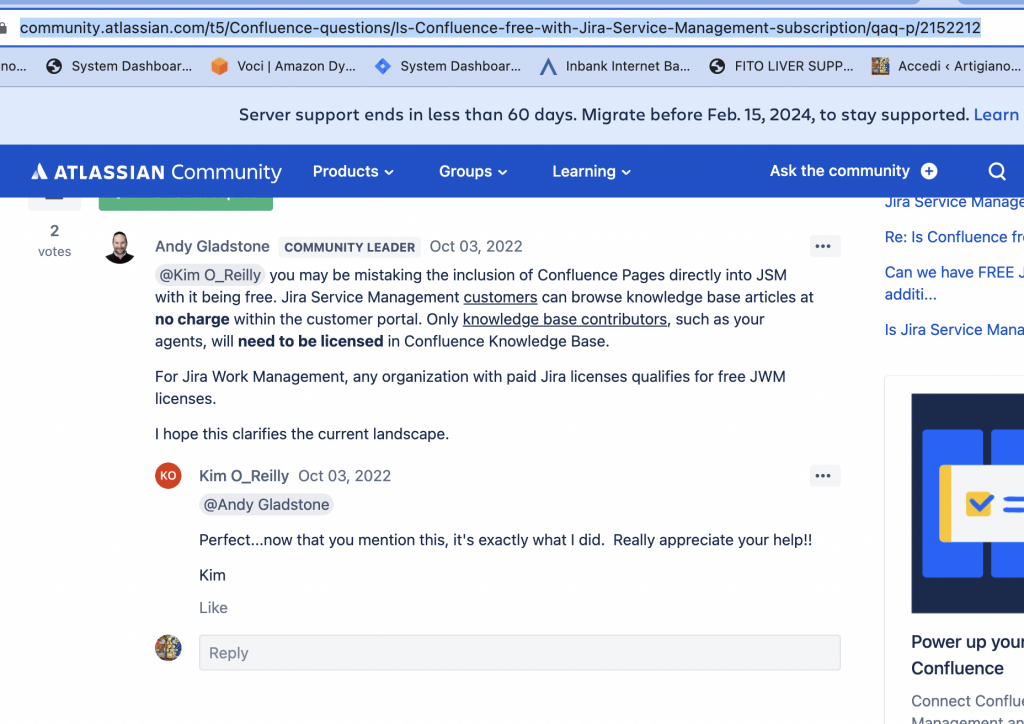
Proviamo a rispondere alla domanda partendo dalle informazioni di base che abbiamo a disposizione. Se infatti consultiamo la Community, ci imbattiamo in queste risposte:
La risposta risulta chiara. Abbiamo bisogno di una licenza …..
…. ed invece NO.
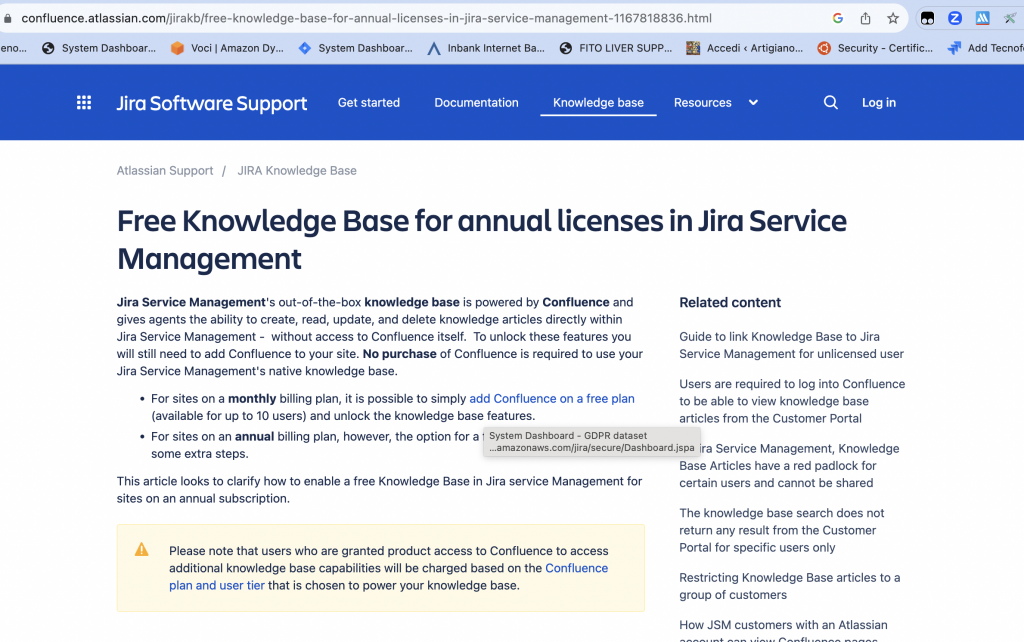
Non da tantissimo tempo, possiamo usare gratuitamente Confluence per implementare la KB basta che siamo titolari di una licenza JSM pagata ed annuale. Come riportato in questa documentazione ufficiale.
Fonte: Documentazione Atlassian
In questo caso, se abbiamo una licenza mensile, possiamo aggiungere Confluence con profilo Free (questo è sempre stato possibile) ma la vera novità è ceh con profilo annuale è possibile usufruire di Confluence per gestire la KB. Questo è molto interessante e l’articolo spiega come arrivare ad ottenere il risultato.
Un nuovo addon da esaminare
In questo post andremo ad esaminare un addon che ci mette a disposizione una funzione interessante. Vediamo in dettaglio addon e funzione.
Esplorazione alchemica
Le presentazioni
L’addon che vogliamo descrivere
Questo addon ci permette di poter eseguire delle operazioni interessanti, ovvero:
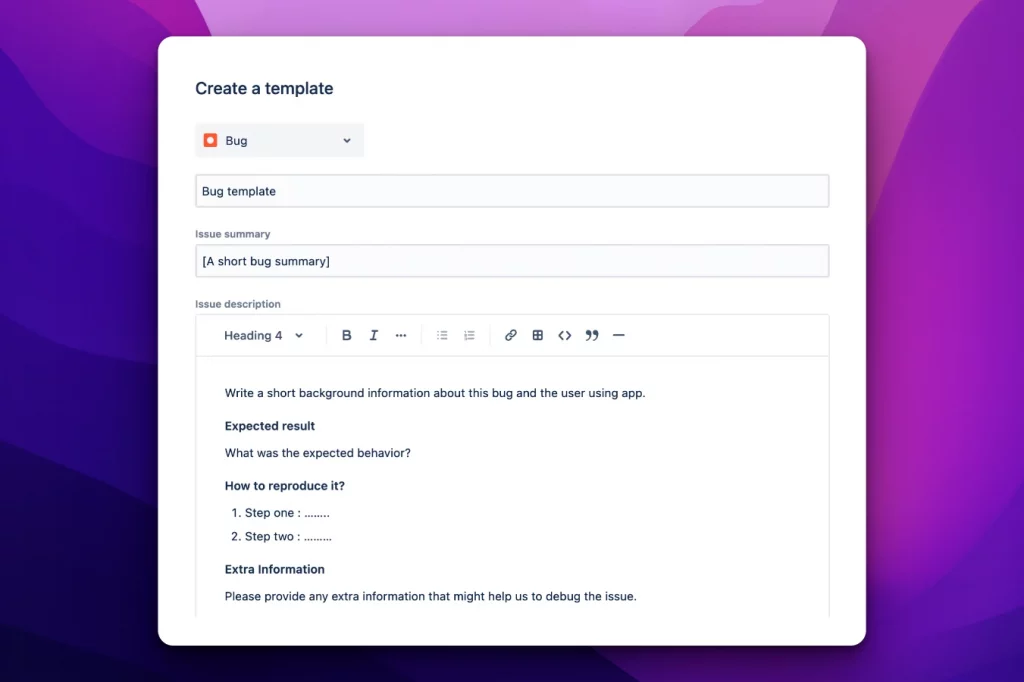
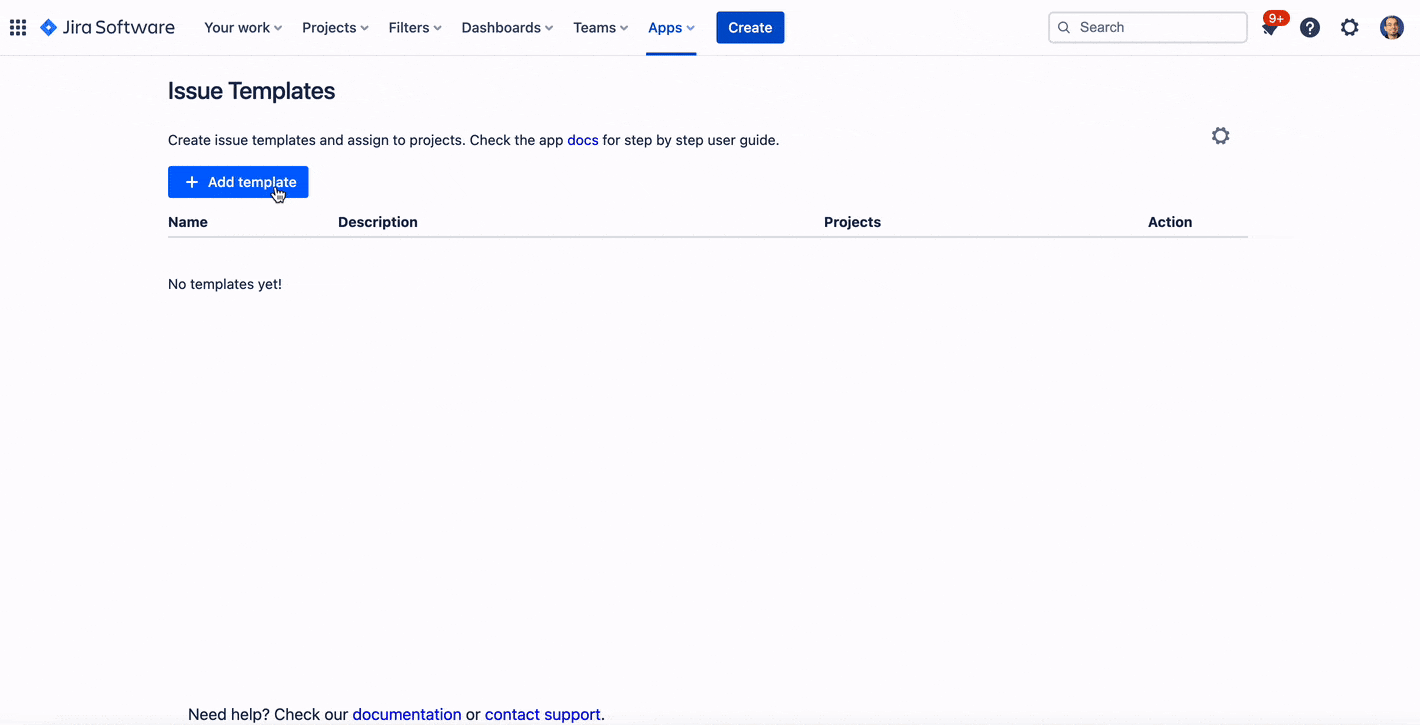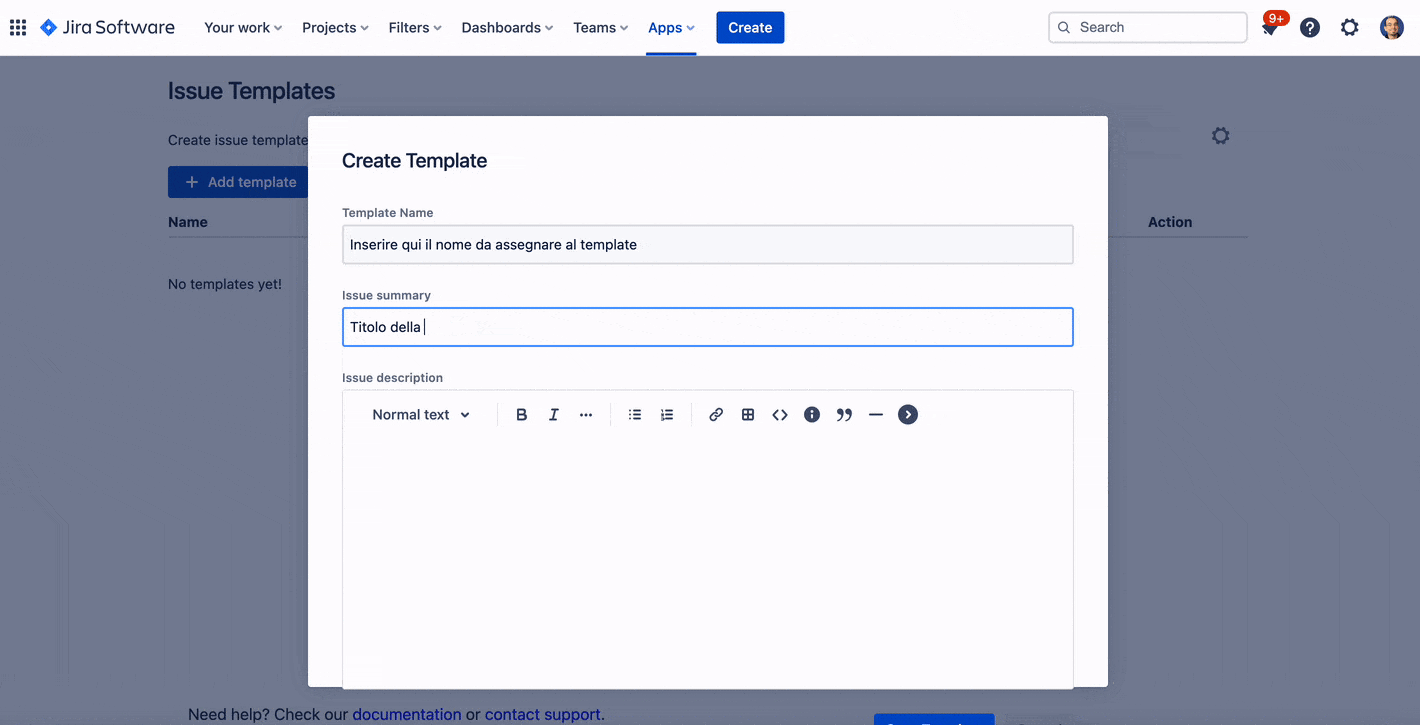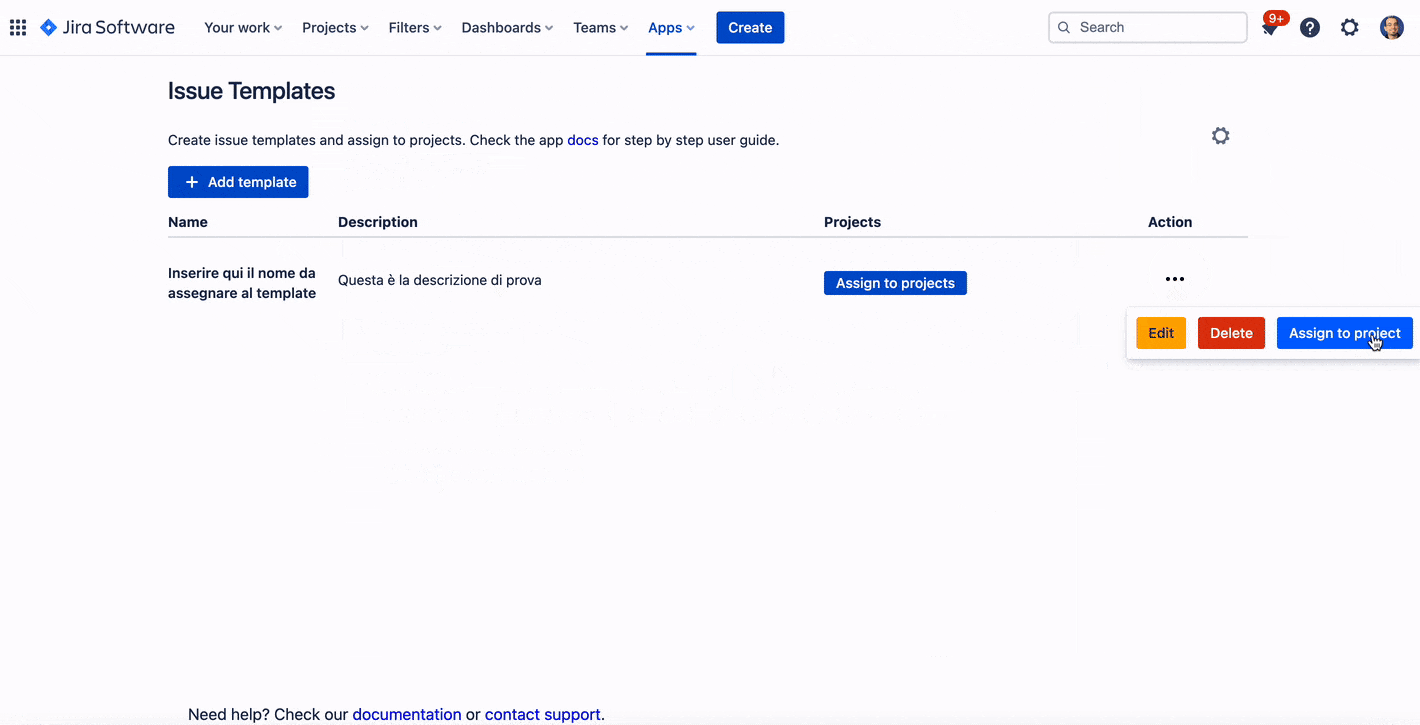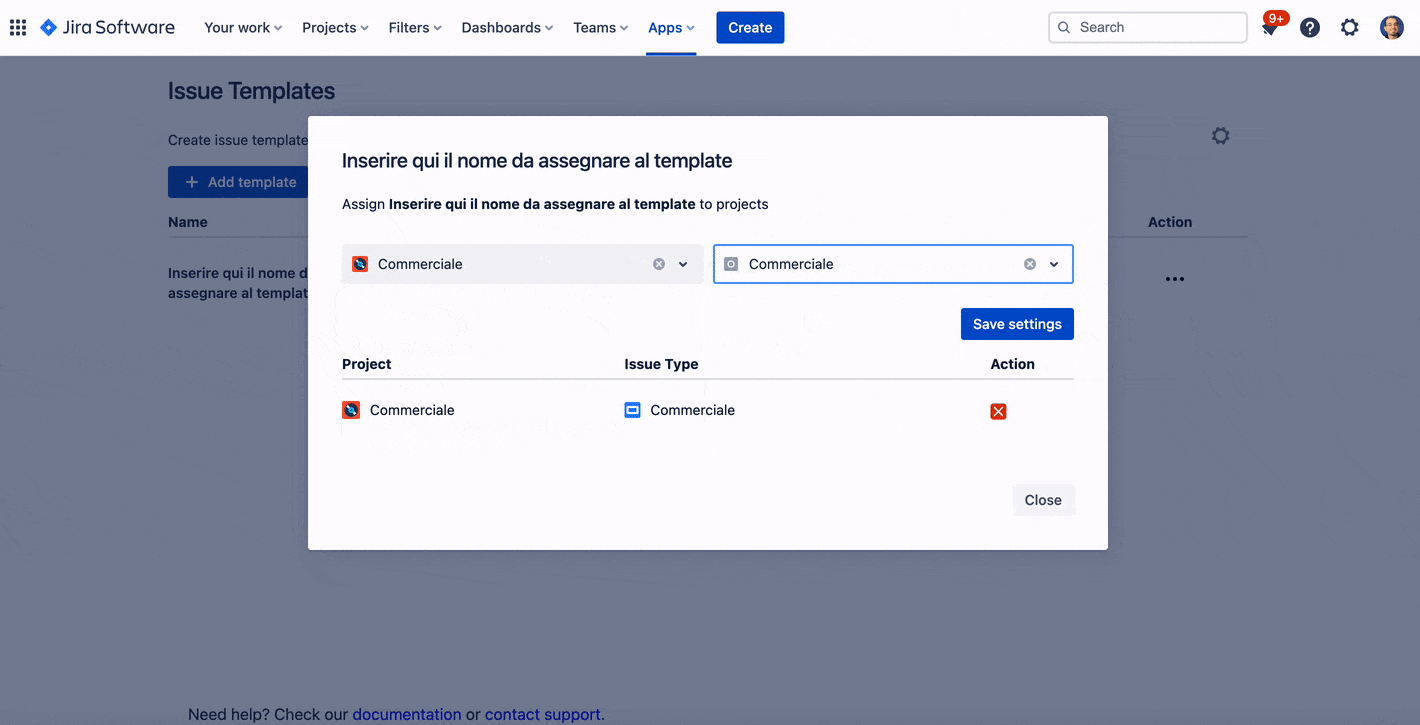
Permette di definire un template di issue
Possiamo precompilare titolo e descrizione della issue
A questo punto abbiamo una cosa molto interessante
Fonte Marketplace
Dalla precedente immagine possiamo vedere come l’addon permette di definire un template. Ci avete fatto caso? abbiamo lo stesso sistema che abbiamo per creare una issue. Questo significa che non dobbiamo imparare nulla di particolare.
Fonte Marketplace
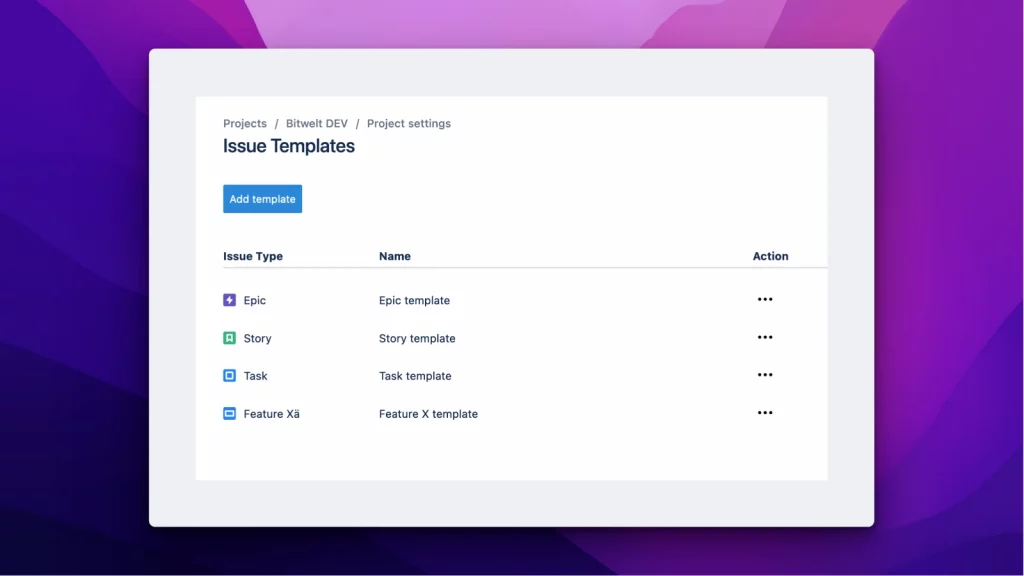
Possiamo definire, nell’ambito dello stesso progetto, una template per issue type. Lo vediamo dalla precedente immagine
Interessante, lo provo subito
Partiamo subito dalla prima operazione. Installiamo l’addon nella nostra istanza. Come sempre vediamo come procedere.
Configurazione Generale
Proseguiamo con la configurazione generale che l’addon. Ci accediamo dal menù principale Apps.
Le funzioni che sono presenti nella sezione
Da li possiamo referenziare i vari template che abbiamo definito. Possiamo anche accedere dalla sezioen Apps presente nelle Project Settings. Faccio una annotazione. Potrebbe darsi, per chi ha installato l’addon quando ancora era gratuito, potreste trovare una immagine come la seguente
Quello che si può vedere nella installazione che ho usato per i miei test
Da li andiamo a definrie il template che andremo ad usare. Vediamo come si configura un template
La GIF ci mostra come eseguire la configurazione da zero del template e l’assegnazione ad un progetto
Come possiamo osservare, la creazione di un template non richieste alcuna complessità: Sembra quasi che creiamo una nuova issue. L’assegnazione non è altro che una semplice opzione che andiamo a selezionare.
Proviamo quanto abbiamo configurato
Adesso proviamo il tutto e verifichiamo il risultato.
Un semplice esempio di utilizzo.
dalla Gif sopra riportata, vediamo che l’utilizzo è molto semplice e ci permette di poter generare le issue direttamente compilate come abbiamo definito.
Conclusioni
Abbiamo un addon che ci permette di poter generare delle issue pre-compilate come ci servono con pochissima configurazione. Questo addon non risulta molto difficile da usare e permette di poter risolvere alcuni casi di uso che mi sono stati richiesti nel corso della mia vita lavorativa. La prova è stata eseguita con la versione free dell’addon. Nel momento in cui scrivo è disponibile una versione a pagamento che sicuramente presenta delle ulteriori funzionalità.
Creiamo una schedulazione pianificata con automation
In questo post affrontiamo un argomento interessante, inerente le Regole di Automazione. Vogliamo creare una schedulazione pianificata tramite le regole di automation per creare una issue/task/compito in base a delle richieste particolari. Vediamo come fare.
Come moderni Bandeirantes, andiamo in esplorazione
Andiamo con ordine
Vogliamo creare in maniera automatica e schedulata una issue particolare ma quando andiamo a richiamare tutti i vari mattoncini lego delle nostre regole, abbiamo dei problemi e siamo in pieno disastro. Come possiamo fare?
Stiamo calmi
Abbiamo una soluzione
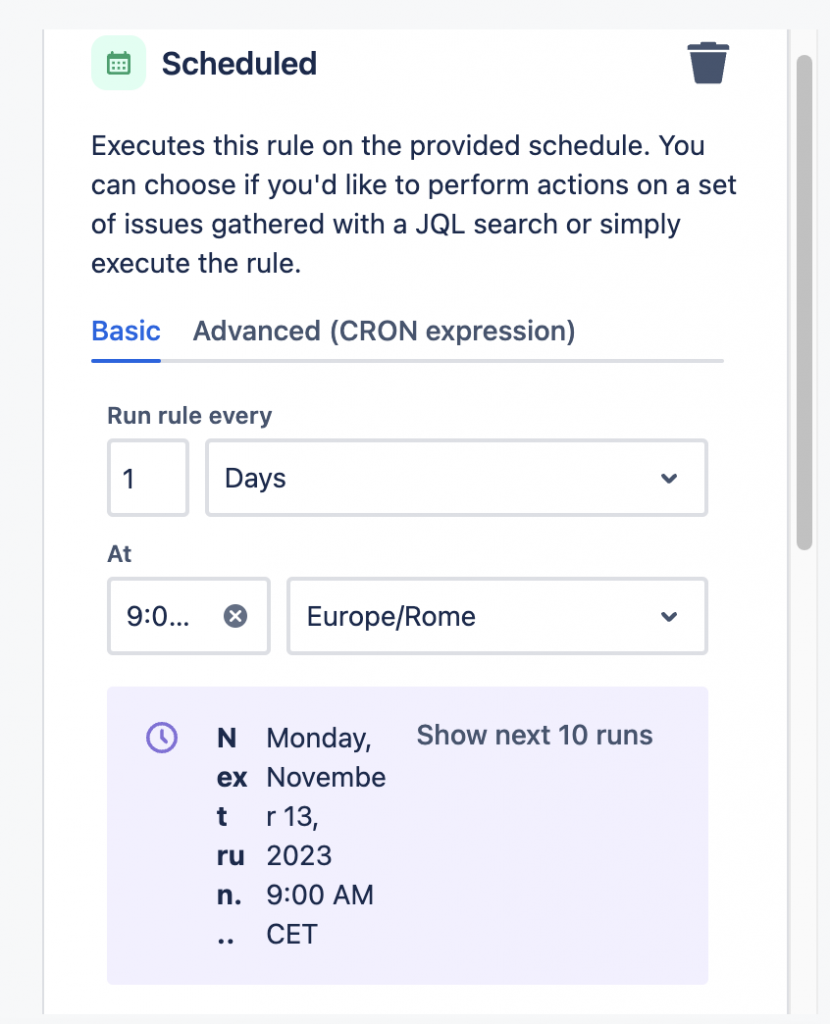
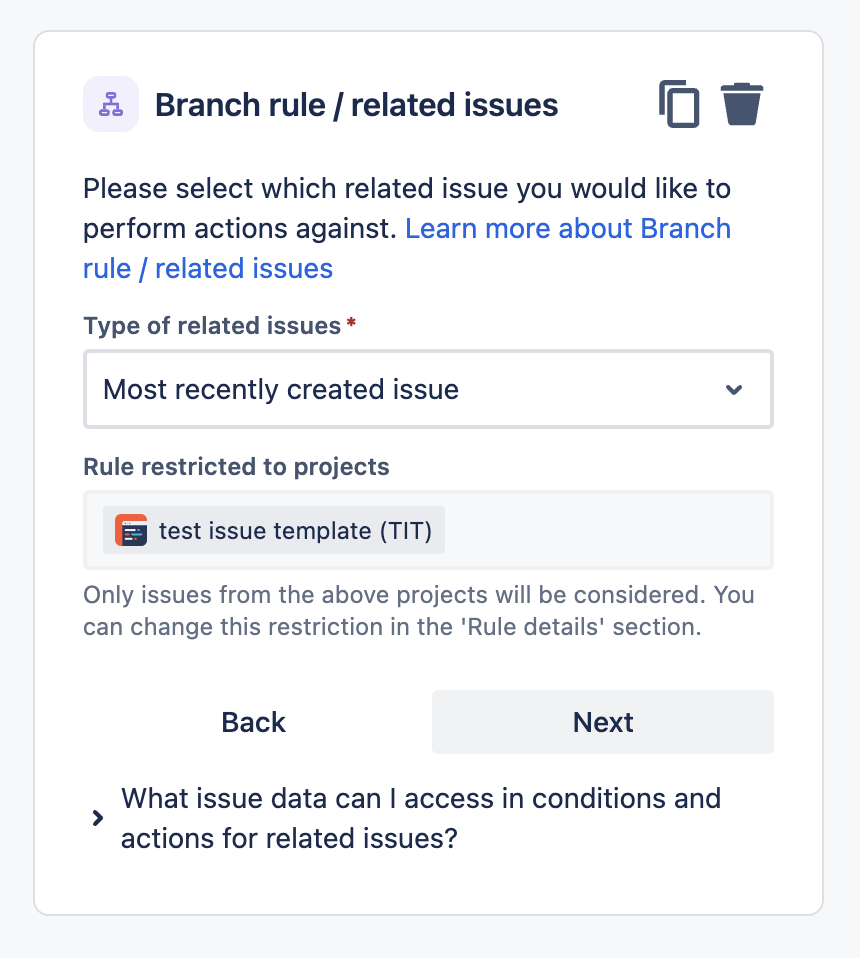
Ebbene si: abbiamo una soluzione, ma andiamo sempre con ordine: un passo alla volta. Sappiamo che possiamo impostare un apposito trigger nelle nostre regole di automation, che ci permette di poter gestire le schedulazioni. In particolare (vedi immagini seguenti):
Un semplice esempioLa relativa sezione di JQL
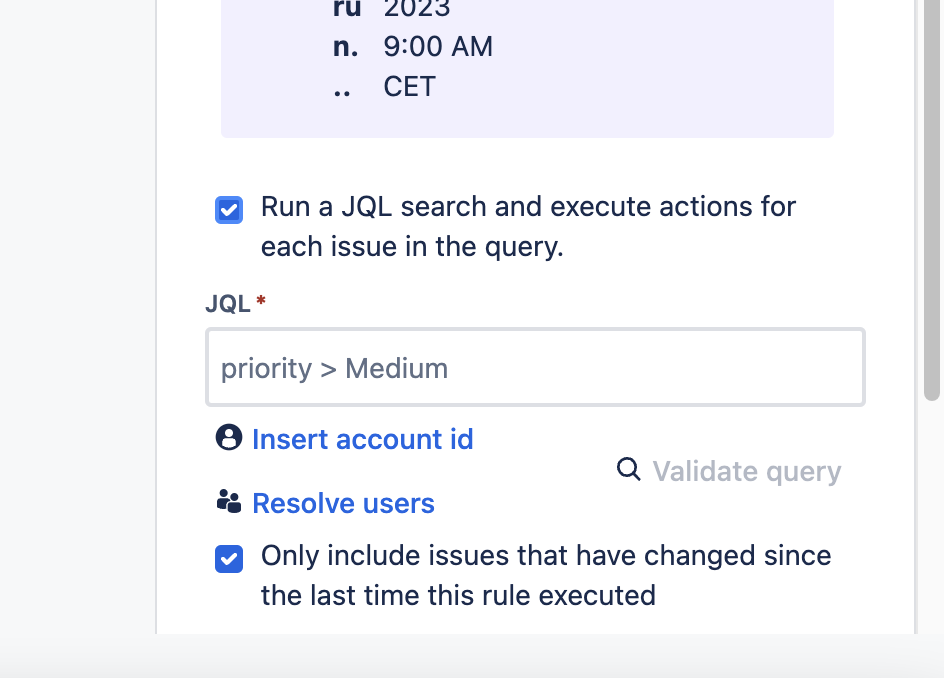
abbiamo quindi tutto, ma abbiamo anche un problema che non possiamo trascurare: Dobbiamo specificare un JQL per selezionare l’elenco delle issue da usare.
Ragioniamo e verifichiamo
Possiamo non specificare il JQL, non sembra obbligatorio. Nel nostro caso di uso vogliamo creare una issue ad un orario ben definito, ma senza dover avere un insieme di issue da gestire. Come possiamo fare? Abbiamo la soluzione e si prega di inoltrare i ringraziamenti alle persone citata nell’articolo di Atlassian Community riportatoi di seguito.
Occorre impostare la seguente condizione
Da dove andiamo a selezionare l’opzioneLa parametrizzazione proposta
che ci permette di poter gestire questa situazione e ci permette di creare una nuova issue non appena scattato il trigger.
Vediamola in azione
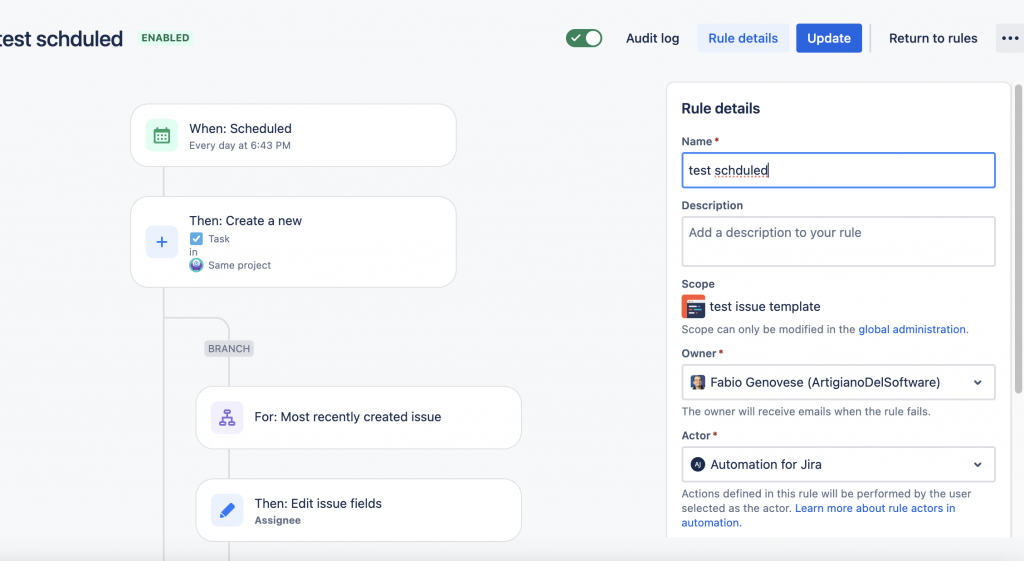
Ho predisposto una regola di prova, per eseguire il test:
regola semplice e banale
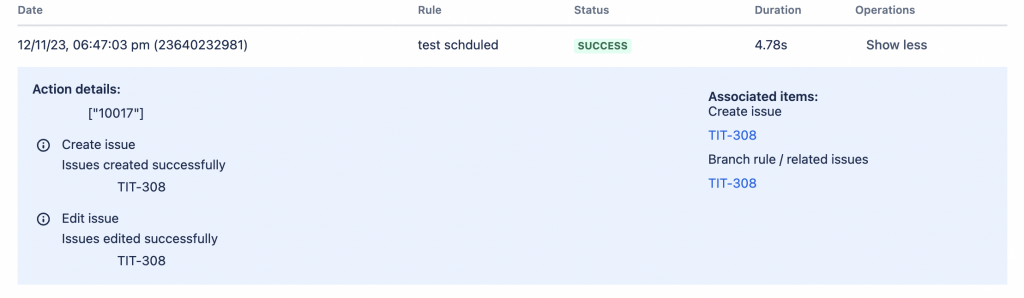
Una volta attivata abbiamo il seguente risultato:
Il risultato dal LOG di esecuzione della regola
e la issue risulta
la issue generata
Conclusione
Abbiamo scoperto un trucco molto importante perché ci permette di creare questa tipologia di schedulazione. questo ci permette di poter avere delle issue create a richiesta senza dover acquistare altri addon e sfruttando lo standard. Ovviamente si tratta di una soluzione che ci fa risparmiare, ma occorre sempre tenere conto di quanto ho già spiegato nel mio post che riguarda la nuova gestione dei limiti di esecuzione delle regole.
Reference
Ringraziamenti a tutti coloro che hanno partecipato alla discussione della Atlassian community e che hanno reso possibile la stesura di questo articolo in Italica lingua.
Grazie.
Ancora una piccola precisazione sulle Automation
Credo che sia sempre ottimo precisare e dare ulteriori indicazioni sulle Automation, che sono un mondo molto vasto ed interessante. Cerchiamo di fare una piccola precisazione che sicuramente sarà molto utile.
Procediamo senza indugio
Nel dettaglio
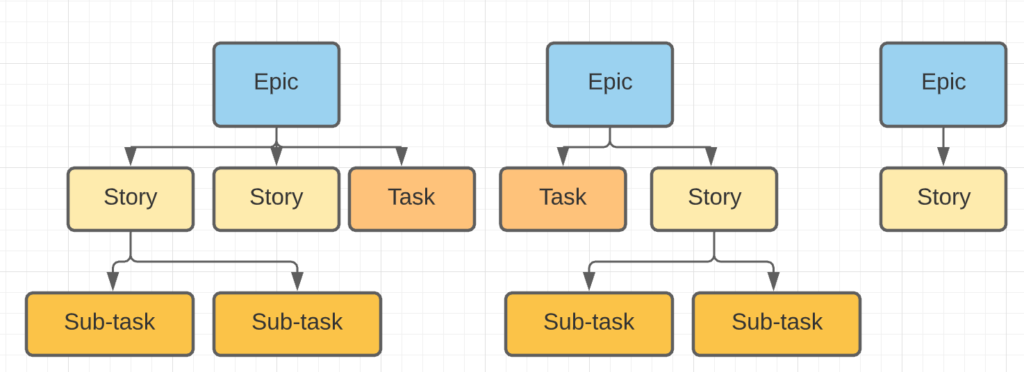
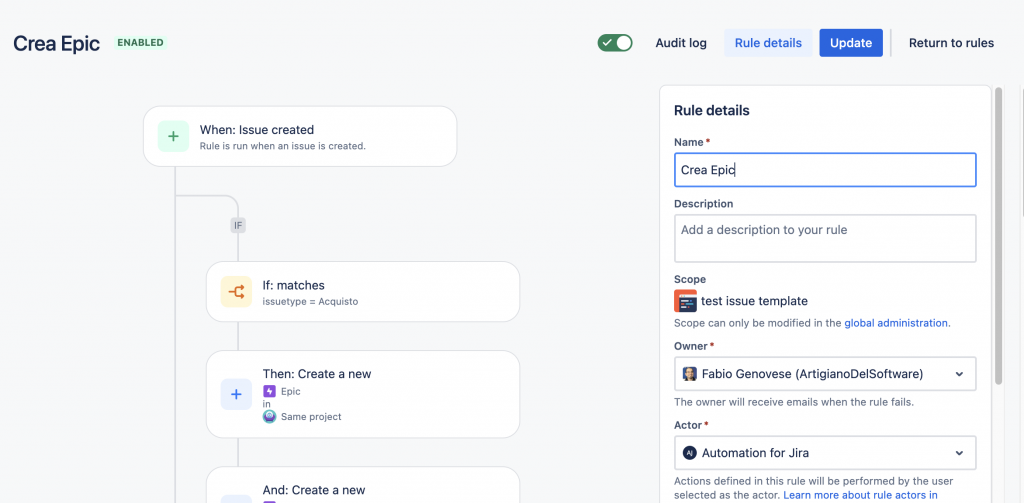
Quello che abbiamo a trattare riguarda il come generare un task affinché sia collegato ad una Epic. Come sappiamo la Epic è un caso eccezionale tra tutte le issue presenti su Jira. Si tratta dell’unica issue type che permette di poter avere delle Issue figlie. I motivi li abbiamo trattati in altri post precedenti ma credo che a breve li andremo a riprendere. 😉
Un esempio ben dettagliato di questa gerarchia
Se vogliamo introdurre questa informazione quando usiamo le regole di automation ci accorgiamo di una cosa: Usando l’azione di Edit Issue, quando selezioniamo il campo Epic Link, non riusciamo a passare il valore. Qualcosa non funziona.
Un dettaglio della azione
Il risultato non è quello sperato. Sembra quasi che l’azione non si esegua. Quindi?
Ragioniamo e verifichiamo
Nozioni di Storia di Jira
Dobbiamo sapere (da storico dilettante non posso esimermi) che originariamente non esisteva la gestione Agile su Jira. E’ stata aggiunta da un addon (greenhopper) che ha introdotto questo aspetto. Atlassian si è buttata a pesce ed ha acquisito l’addon. Adesso sembra tutto integrato, ma….. in realtà credo ci sia una separazione ancora netta. Credo che sotto sotto sia rimasto un addon separato e di conseguenza anche il campo sia gestito in maniera separata.
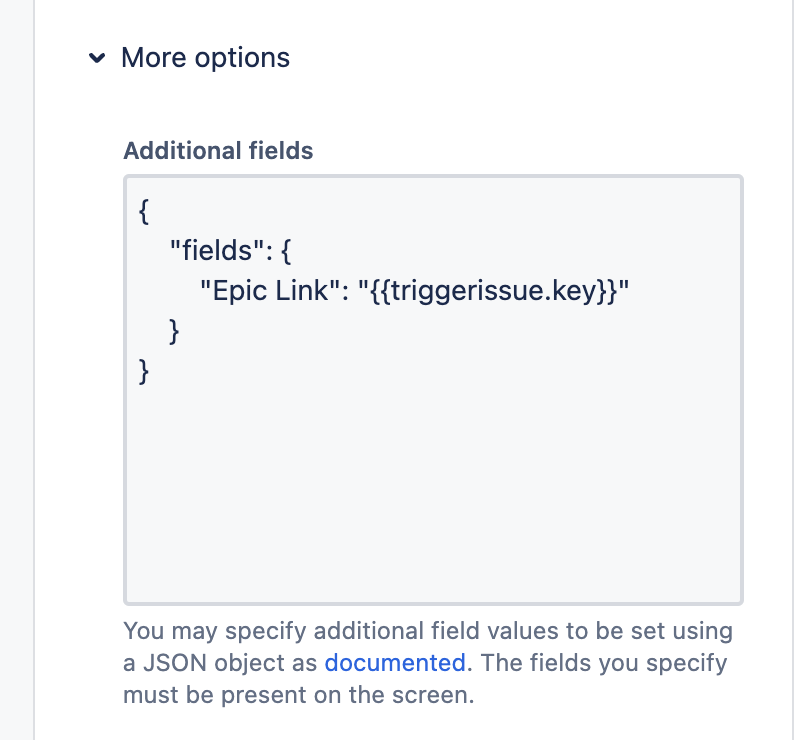
Ho scartabellato e verificato ed il risultato è questo articolo del Community: Il campo va gestito esattamente come un qualsiasi campo custom. Passiamo al Json:
Uno schema del JSON da usare
Se usiamo questa indicazione, riusciamo ad arrivare all’obiettivo.
Conclusione
Un ringraziamento a tutti coloro che hanno partecipato a questa discussione che ha permesso la redazione di questo articolo in Italica Lingua.
Grazie.
Un ultimo appunto:
Mentre componevo questo articolo, ho notato una cosa molto carina. Atlassian sta rivedendo l’interfaccia grafica della sezione delle regole di Automation. Infatti:
URCAAAAAA
promette bene. Vedremo nei prossimi mesi che cosa succederà.
Creiamo un link ad una pagina di Confluence su Jira
In questo post affrontiamo un argomento interessante, inerente le Regole di Automazione. Già recentemente abbiamo parlato, in questo post, di come la gestione dei limiti di queste regole cambiano dal prossimo primo novembre. Vediamo in questo caso come sopperire ad una necessità, ovvero come possiamo aggiungere un link ad una Pagina di Confluence ad una issue, direttamente da Regola di automazione.
Come moderni Bandeirantes, andiamo in esplorazione
Andiamo con ordine
Vogliamo associare ad una issue, quella che ha causato l’esecuzione della nostra regola, una pagina di Confluence ben precisa. Una cosa che notiamo subito è che non abbiamo a disposizione una azione specifica attraverso le Automazioni. DI conseguenza siamo leggermente frustrati. La domanda sorge spontanea. Come possiamo fare??
Stiamo calmi
Abbiamo una soluzione
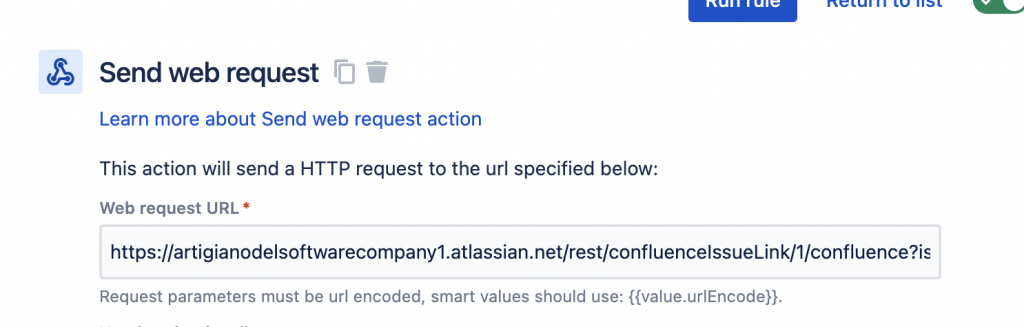
Ebbene si. Possiamo sfruttare una delle azioni che meglio si adegua per poter agganciare una pagina ad una issue. In particolare possiamo sfruttare questa azione:
Send Web Request è quello che ci serve
Da questa azione possiamo fare ua cosa molto semplice: Chiamare una API di Atlassian e agganciare la pagina alla issue. ma vediamo quale è la API che andiamo a richiamare.
Quello che occorre fare è impostare i parametri che ci servono e successivamente applicarli tramite la regola.
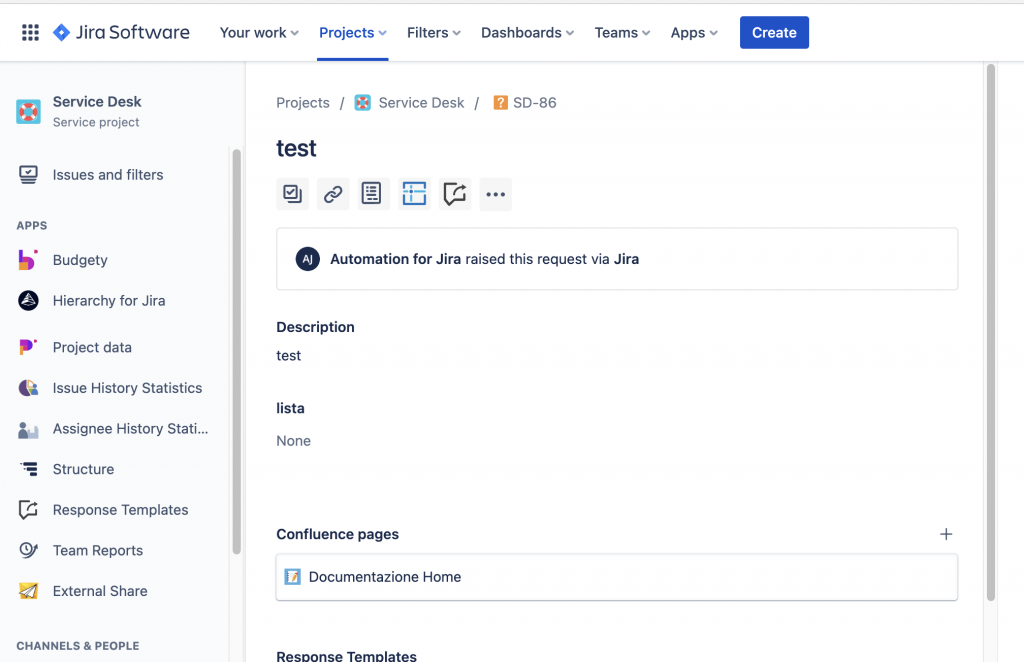
Il risultato è il seguente:
Un esempio che ho impostato su di un mio ambiente di prova
Conclusione
Questo è molto interessante. Possiamo agganciare una pagina Confluence alla nostre issue in maniera veramente semplice. Ci sono degli accorgimenti da tenere presente quando si utilizzano delle API, ma ne parleremo in maniera più approfondita in separata sede. Si tratta di una sorpresa. Rimaniamo in contatto.
Reference
Un ringraziamento a tutti i partecipanti a questa discussione della Atlassian Community, dove è stato chiarito questo punto e che ha permesso di poter scrivere questo articolo in Italica Lingua.
Sulla necessità di modificare massivamente i dati di un campo Jira Cloud
In questo post andremo ad esaminare un addon veramente interessante. Vi posso assicurare che ho avuto la possibilità di eseguire un collaudo molto accurato ed il risultato mi ha lasciato seriamente a bocca aperta dai grandi risultati ottenuti. Ma andiamo con ordine: Partiamo dall’inizio e spieghiamo il caso di uso cercando di mostrare come funziona questo addon.
Set explore mode = ON
Il caso di uso che mi si è presentato
In questa situazione, avevo la necessità di dover modificare massivamente il contenuto di un determinato campo, risultato della Migrazione da Server a Cloud per conto di un mio cliente. In questo caso, i campi migrati erano il risultato della migrazione del valore di Elements (ex nFeed). Il problema è che il valore dei campi risultava un qualcosa di questo genere, inaccettabile da proporre al cliente.
{“key:[“XXXXXXXX – Una descrizione del codice”]}
il risultato era un Json che non rispecchia proprio il valore desiderato dal cliente. Le funzionalità standard non permettono delle modifiche così approfondite. Si rendeva necessaria una operazione di ingegno. Iniziavo una analisi alchemica che mi aiutasse nella risoluzione del problema.
Questa immagine descrive la mia situazione. Nottate ad elucubrare per un risultato
…. ma alla fine il risultato è giunto insperato
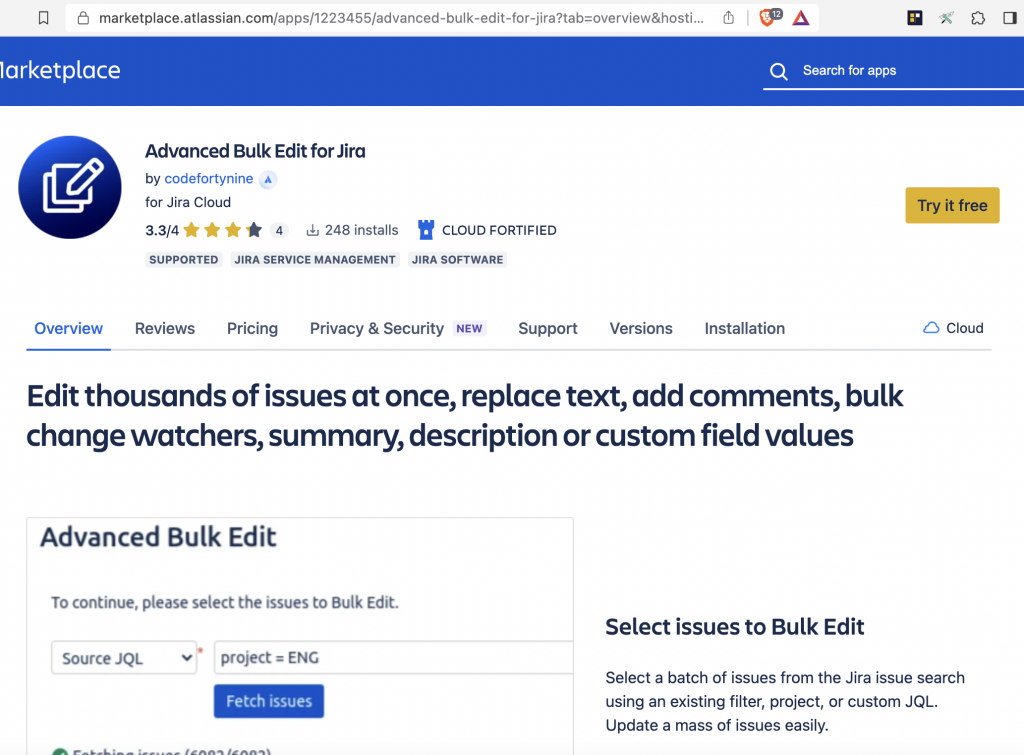
Una soluzione si è presentata quando oramai sembrava tutto perduto. Un addon mi salvava la vita e mi permetteva di poter correggere il valore e risolvere la questione. Si tratta di Advanced Bulk Edit for Jira, un addon della Codefortynine molto molto interessante.
La pagine dell’addon su Marketplace.
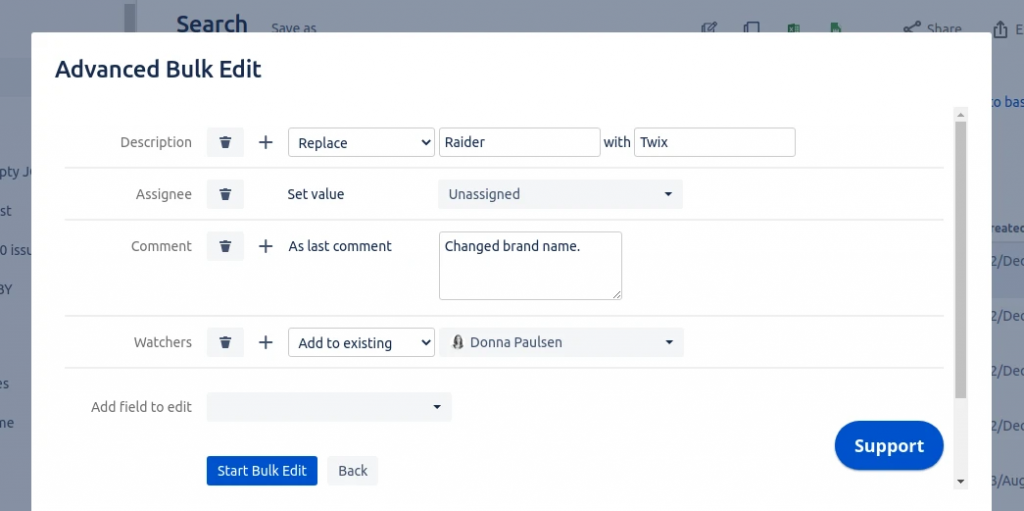
Questo addon permette di poter eseguire delle operazioni sui campi permettendone la MODIFICA. Questa è una caratteristica molto molto interessante.
Fonte Marketplace Atlassian
Dalla precedente immagine possiamo osservare che abbiamo diverse possibilità per modificare i campi. Possiamo aggiungere dei valori, eseguire delle operazioni di Sostituzione di testo con altro, etc. La faccenda diventa interessante
Iniziamo a rilassarci e a pensare quante possibili applicazioni possiamo farne
La mia esperienza lavorativa
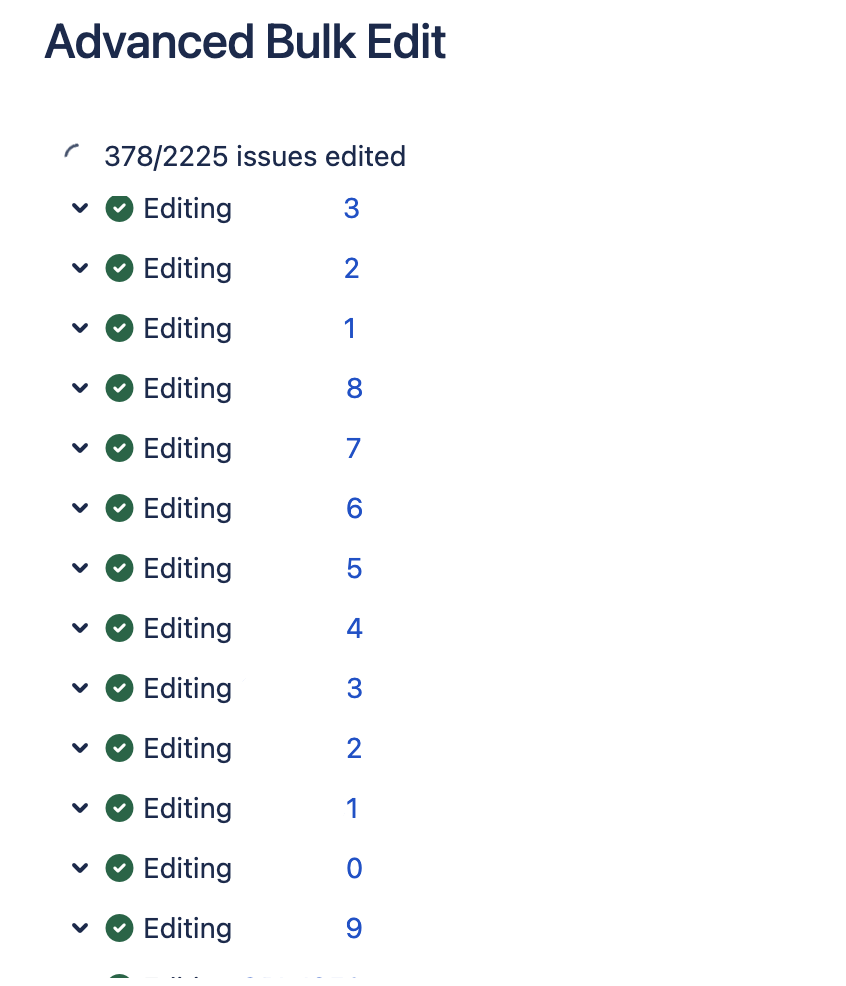
Nell’utilizzo di questo addon ho notato una cosa molto molto interessante. Se andiamo ad eseguire una query JQL, quello che otteniamo è il seguente risultato (il particolare sul CLOUD): La query JQL non restituisce più di 1000 risultati, anche se le issue sono più di 1000. Questa è una limitazione che le API di Jira dispongono. DI conseguenza abbiamo sempre qualche problema
Calma, non disperiamo. Abbiamo una piacevole novità
La seguente schermata è stata presa (opportunamente trattata per non mostrare dati riservati) al fine di riuscire a mostrare il risultato. Se ci fate caso il numero di issue selezionato è maggiore di 1000.
Tratto da una operazione di Bulk Edit che hi eseguito.
Quello che si nota è che il limite di 1000 issue è superato con questo addon. Non male, assolutamente non male.
Conclusione
Abbiamo un addon MOOOOOOOLTO MOOOOLTO interessante. Ho già identificato una serie di possibili utilizzi di questo addon in altri casi di uso. Verificherò e vi riporterò di seguito in altri post. Rimaniamo in contatto.
In questo post provo a riassumere i primissimi test che ho operato su Atlassian Intelligence. Si tratta delle primissime funzioni che sono state introdotte e, faccio ancora presente che si tratta di funzionalità che sono ancora in BETA.
Set explore mode = ON
Quali funzioni sono state rilasciate?
Al momento tutte le funzionalità rilasciate sono presenti solo su Jira (principalmente su Jira Software e su Jira Service Management). Siamo in trepida attesa di poterle testare anche su Confluence, dove sicuramente saranno un validissimo aiuto nella redazione dei documenti. Per il momento ci acconenteremo di eseguire un valido test anche su Jira.
Su Jira Software ….
…. abbiamo a disposizione una funzione molto interessante, La possiamo vedere subito nella nuova maschera di ricerca:
Il primo impatto
Abbiamo a disposizione nella Nuova maschera di ricerca delle issue (in questo caso abbiamo la necessità di fare una piccola digressione: con la nuova maschera di ricerca intendo la maschera che presenta delle caratteristiche grafiche carine ed interessanti, ma che ci propone anche delle limitazioni non indifferenti, che saranno affrontate in un apposito articolo) e che presenta un apposito tasto che ci permette di poter attivare le nuove funzioni ai Atlassian Intelligence.
Una volta che selezioniamo tale tasto, questo è il primo risultato
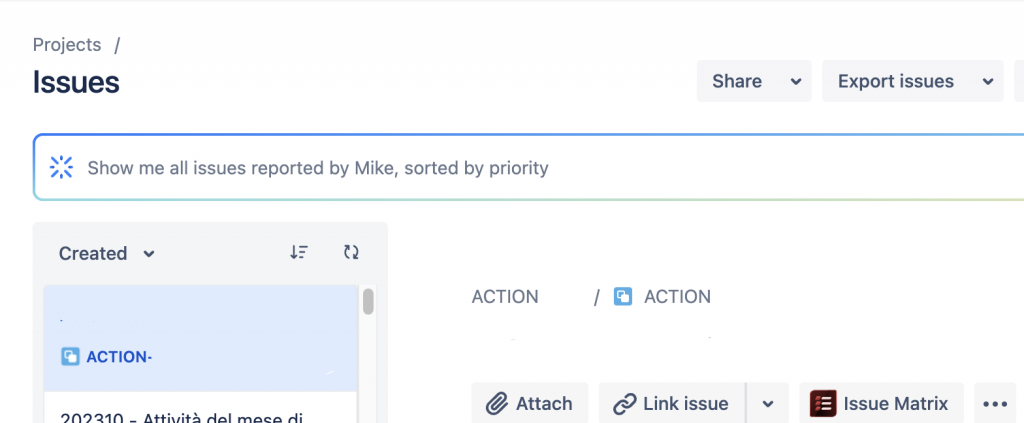
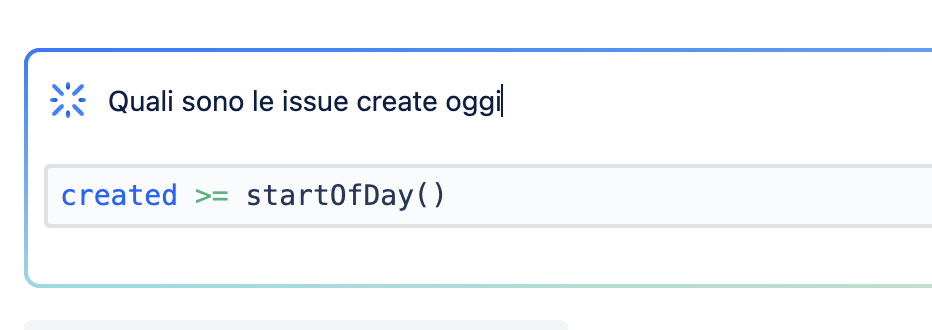
Nella nuova text box possiamo richiedere, in linguaggio naturale, le richieste che vogliamo. Queste saranno tradotte in JQL, come mostrato nelle seguenti figure
Un primo esempio di conversione eseguito da Atlassian IntelligenceUn secondo esempio di conversione eseguito da Atlassian Intelligence
L’esempio che vediamo è molto interessante. Anche se amante del JQL, sono affascinato dal fatto che abbiamo a disposizione una funzione che da linguaggio naturale ci conferte la richiesta in JQL e ci permette di poter generare i nostri filtri in maniera semplice. Mi sembra un buon inizio.
Su Jira Service Management ….
…. abbiamo a disposizione altre funzioni interessanti, quali ad esempio:
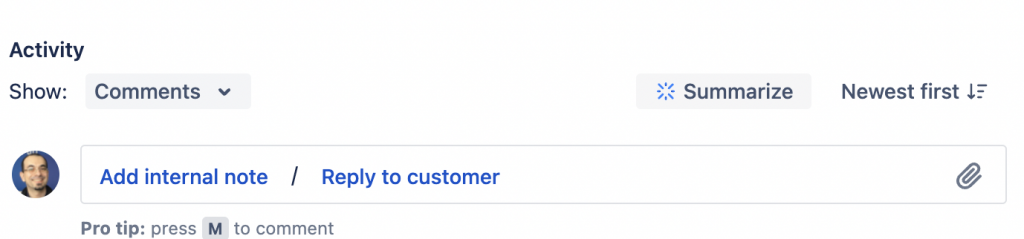
Riassunto di tutti i commenti di una issue
Abbiamo a disposizione una funzione che ci permette di poter eseguire il rassunti di tutti i commenti di una issue, permettendoci di risalite in pochissimo tempo ai fatti salienti ed essere allineati subito.
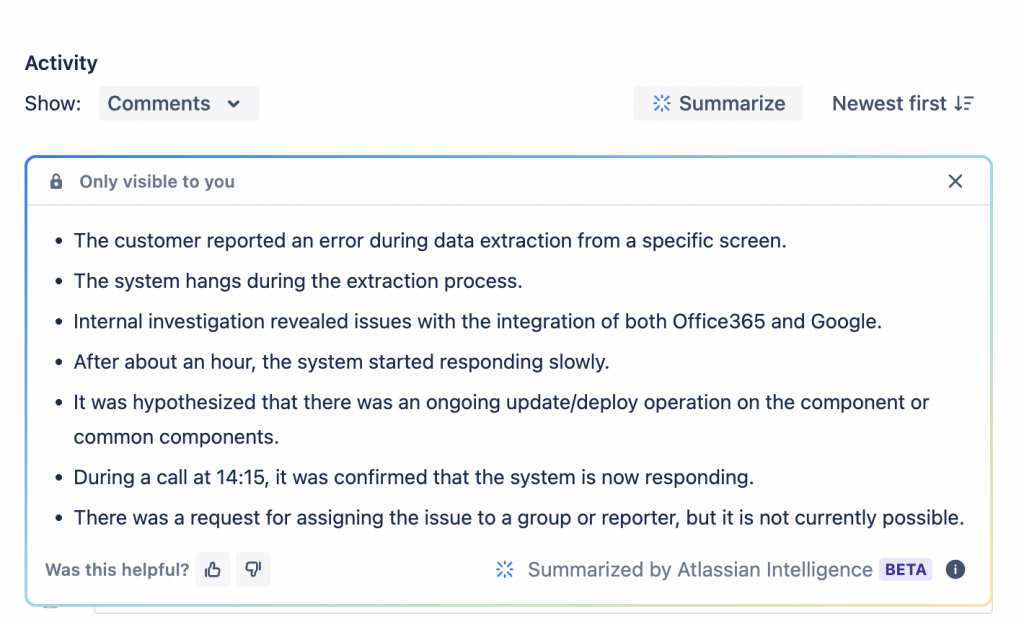
Un esempio di applicazioen ad un caso reale
In questo caso ho provato un esempio su di una mia segnalazione interna, dove (ahime ancora in Inglese) riassume la sitiazione, ma non disperiamo: presto sarà disponibile in lingua. Abbiamo infatti visto che l’interprete che converte in JQL legge perfettamente l’Italiano
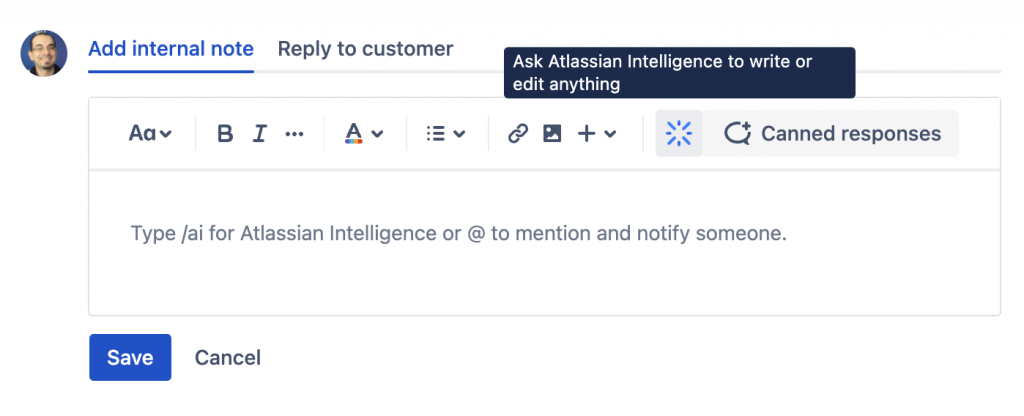
I commenti possono essere implementati anche con l’aiuto di Atlassian Intelligence
Abbiamo la possibilità di poter scrivere i commenti sfruttando le potenzialità di Atlassian Intelligence
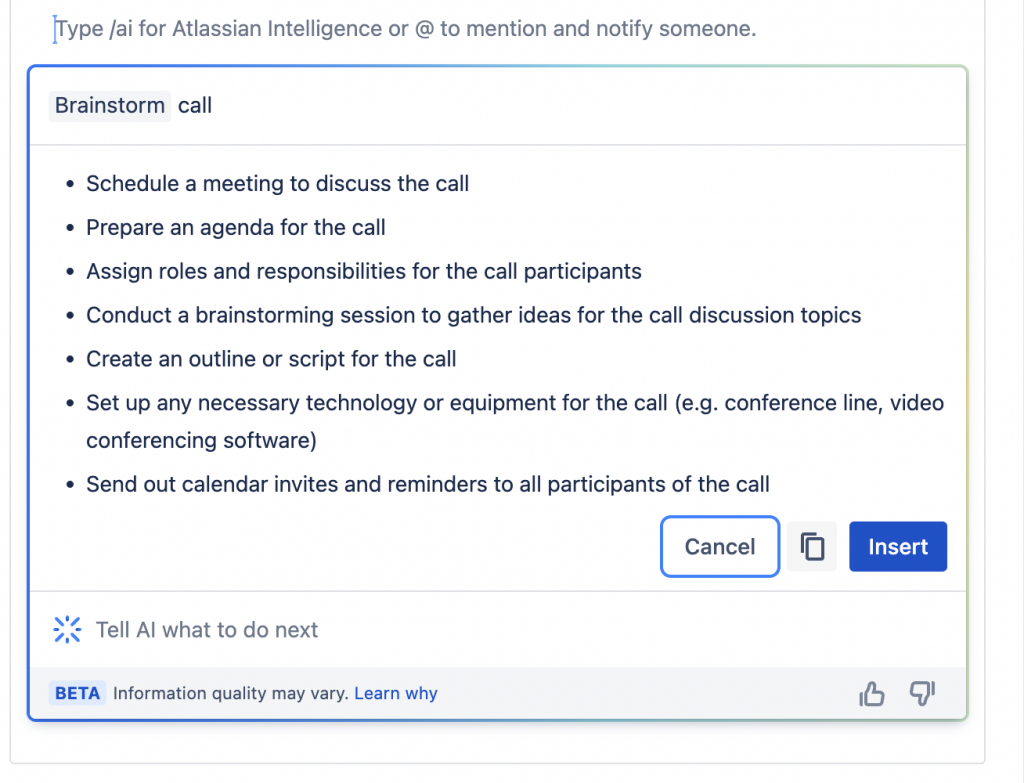
Ecco un esempio
La precedente immagine ci mostra un possibile esempio. Il risultato è interessante, ma come sempre pongo sempre l’attenzione sul fatto che si tratta di una applicazione (per quanto sofisticata ed attentamente sviluppata) e quindi tutti i risultati devono essere sempre valutati e confermati prima di essere inviati.
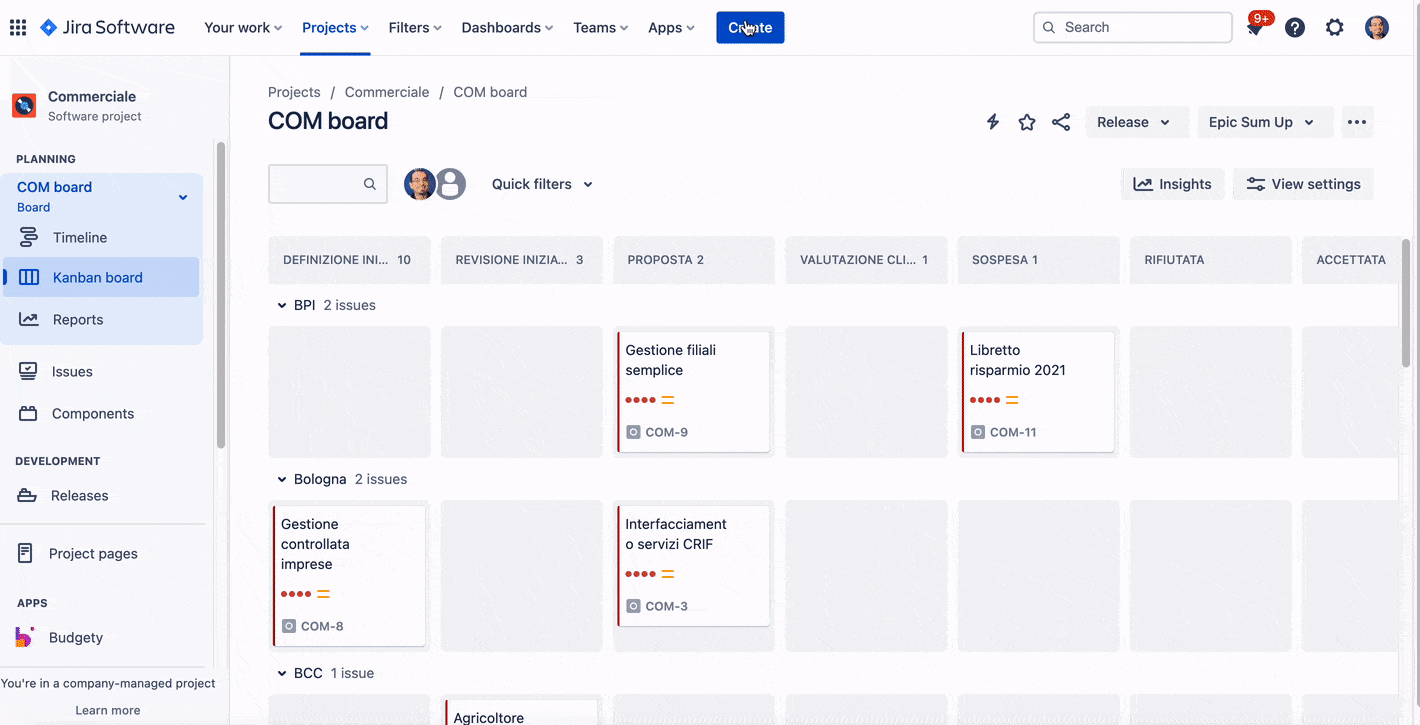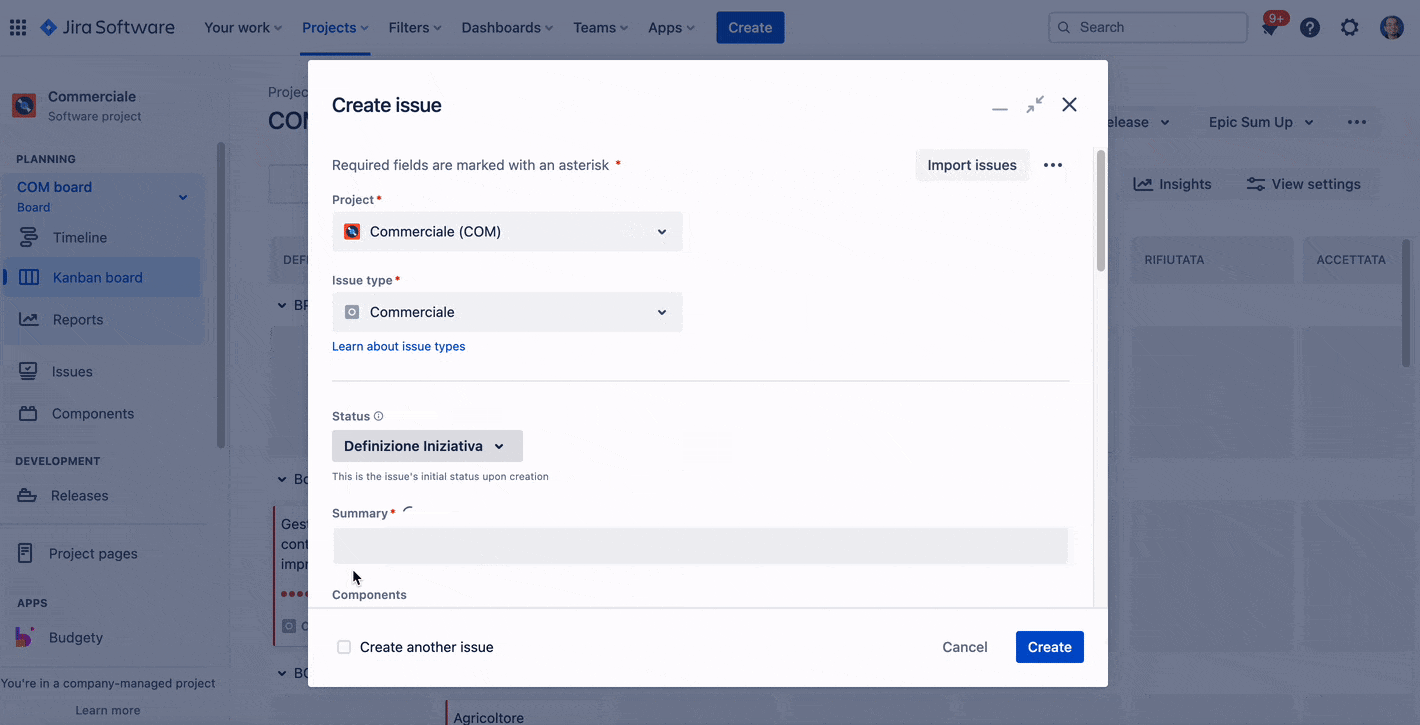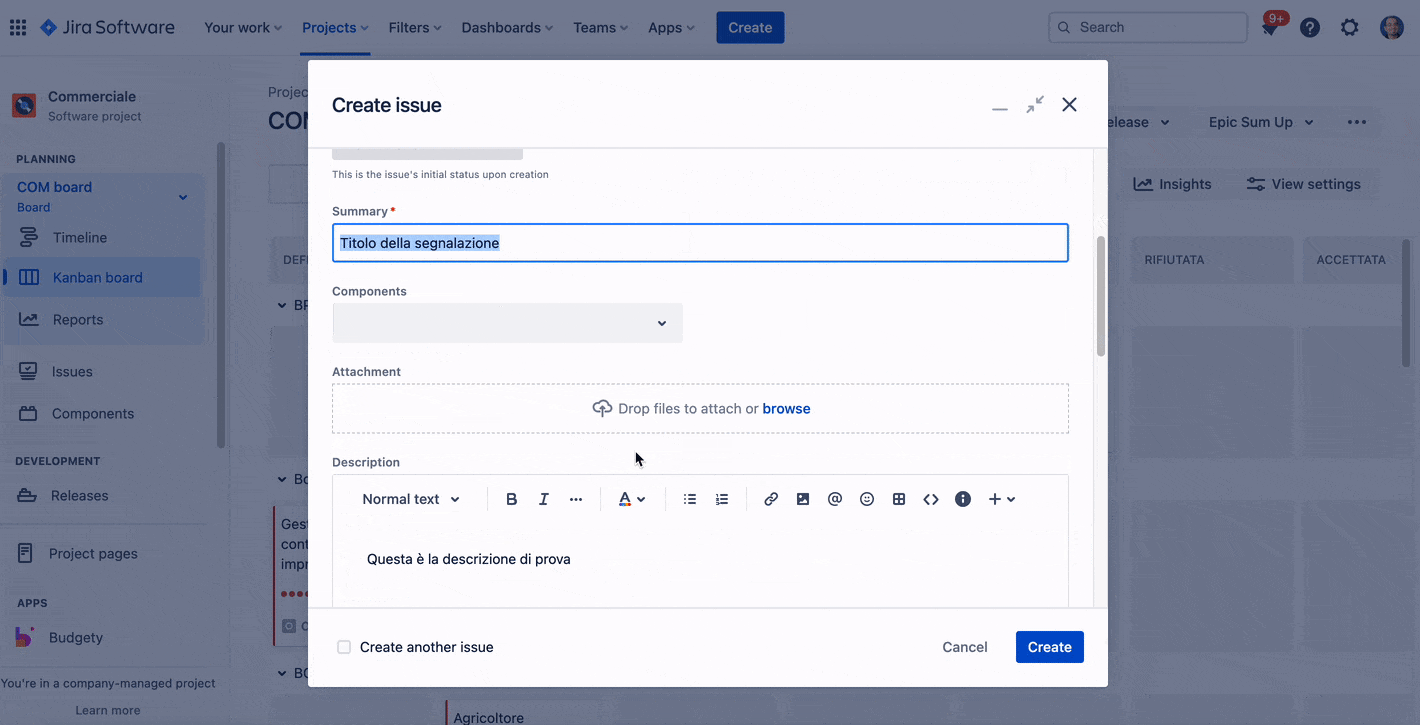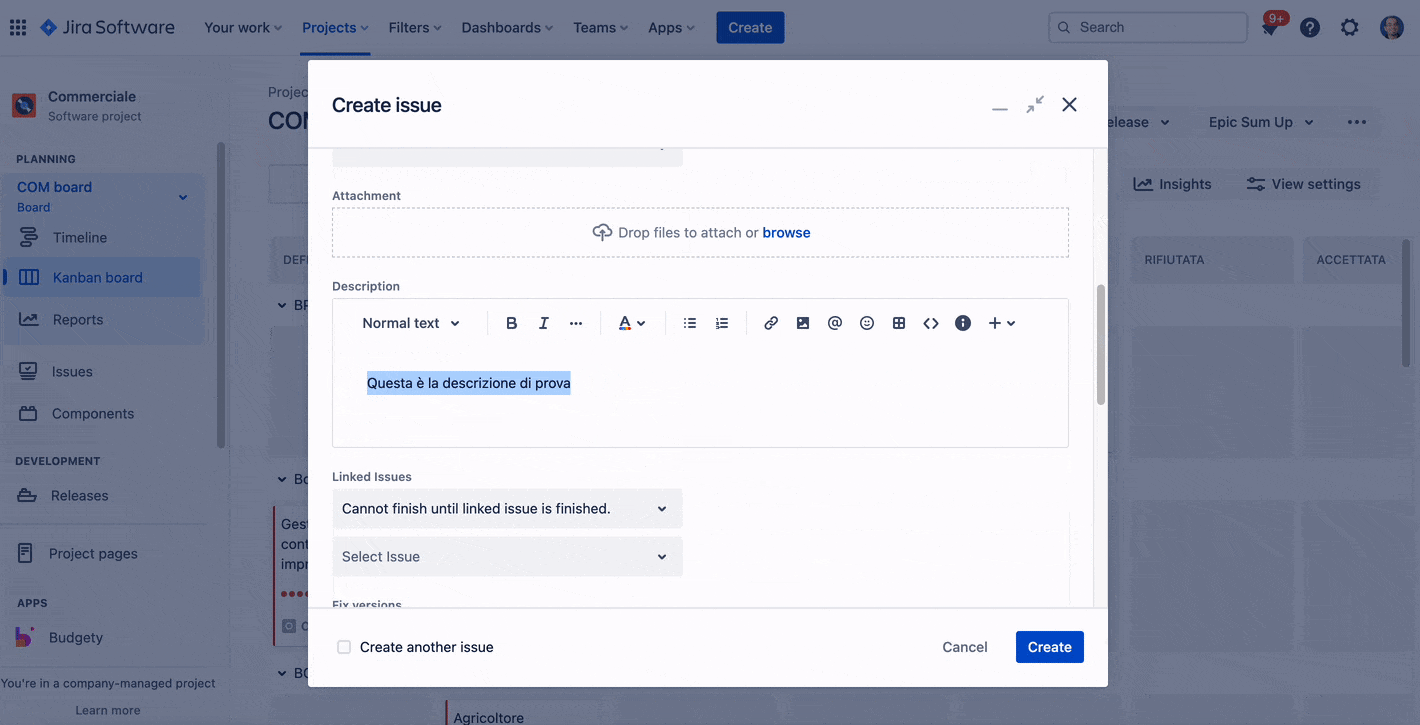
Non solo commenti, ma anche un aiuto nello scrivere la descrizione del task
Atlassian Intelligence ci fornisce un aiuto anche nello scrivere la descrizione della nostra issue. Anche in questo caso possiamo sfruttare le sue potenzialità per meglio esprimere quello che necessitiamo, ma come sempre e costantemente ribadisco, l’ultima parola è e rimane la nostra.
Interessante, ma quali funzioni su Confluence?
UDITE UDITE
Fino a qualche settimana fa non era possibile includere Confluence. Mentre stavo eseguendo la revisione del post mi hanno fatto notare che le funzionalità sono adesso disponibili per Confluence. Cosa facciamo? Ma andiamo ad analizzare immediatamente quello che è possibile fare con Confluence, ma lo riporteremo nella prossima puntata.
Corriamo immediatamente a fare un test
Conclusione
Abbiamo un primo risultato che è molto incoraggiante e sopratutto ci mostra come questo strumento è e rimane sempre a nostra disposizione per migliorarci, supportarci e permetterci di fare meglio il nostro lavoro. Rimaniamo in attesa della funzionalità applicata a Confluence.
Aggiungo un video molro interessante, dove troverete altre informazioni e indicazioni sulle funzionalità aggiunte
Poi porto carico (Cit. Il Commissario Montalbano). Ho avuto il piacere di assistere all’ACE di Boston di recente e li ho avuto modo di poter vedere i risultati di Atlassian Intelligence e quali meraviglie ci presenterà. Per questo motivo mi permetto di condividere il video (in Inglese) dell’evento. L’ultimo intervento è proprio relativo alla parte di Atlassian Intelligence. Buona visione.