FishEye & Crucible – Esempio di una Code Review
Code Review
In questo post, vedremo un esempio di utilizzo di FishEye e di Crucible, per realizzare una Code Review.

Definizioni
Partiamo, come sempre, dalle definizioni. La prima definizione che segnalo è quella di wikipedia, che ritengo abbastanza completa (in inglese). Una Code Review fondamentalmente è una analisi critica del codice, il cui obbiettivo è quello di determinare eventuali problemi o errori o possibili punti in cui si può migliorare il codice.
Mi permetto di evidenziare la parola eventuali , in quanto non è detto che quanto rilevato in una Code Review sia effettivamente un errore. Infatti (faccio appello alla mia esperienza), la soluzione adottata potrebbe essere dovuta alla situazione del momento o ad un particolare workaround adottato per poter risolvere il problema in una determinata emergenza. L’analisi deve essere critica ma deve essere fatta con giudizio e sopratutto con la …. testa :-D.
Iniziamo
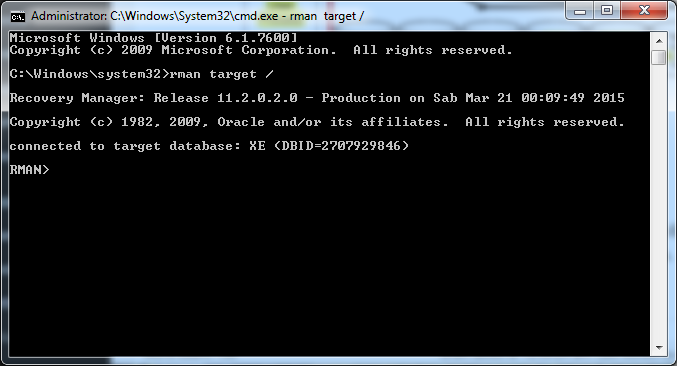
Già nei precedenti post dedicati a FishEye, abbiamo visto come è possibile poter navigare il codice direttamente da interfaccia Web.

I primi passi per poter iniziare una code Review sono i seguenti. Primo passo in assoluto è quello di creare un progetto all’interno di Crucible. Premessa: Occorre disporre dei privilegi di amministratore 🙂
Dal Cog menù, come indicato in figura:
![]()
selezionare Administration. Quindi, nella sezione Project Settings, selezionare Projects. Quindi Dare New Project.

Se si conosce come definire i progetti sotto JIRA, allora risulterà molto semplice gestire i progetti sotto Crucible. La logica è la medesima. Si definisce una KEY, utilizzata per numerare le segnalazioni di Code Review.
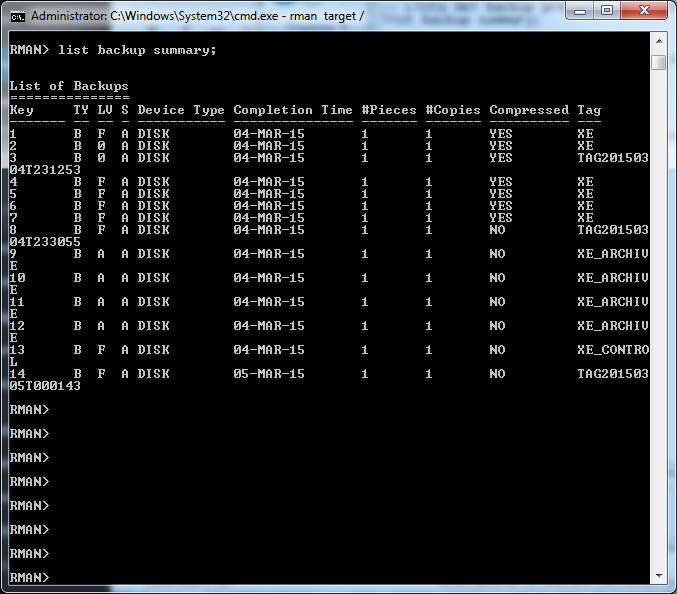
Una volta definito il progetto, possiamo andare ad iniziare la Code Review. Come? Semplicemente andando a spulciarci il codice e andando a controllarlo.

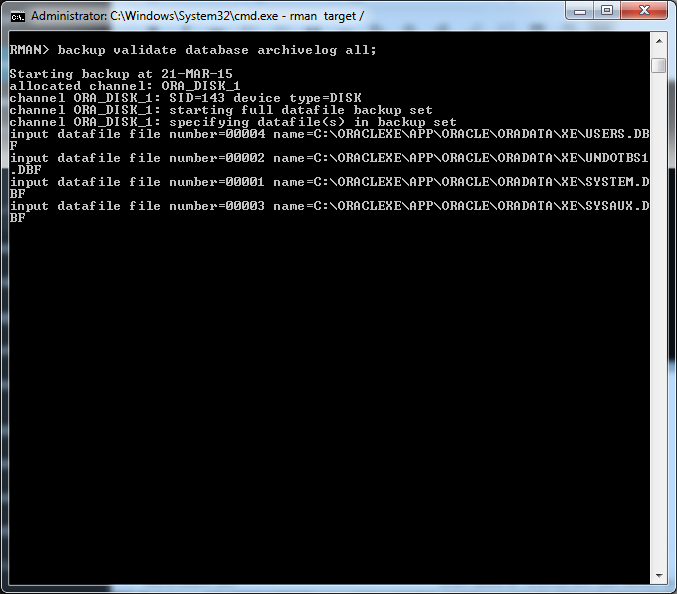
Semplicemente andiamo alla riga di codice che … attira la nostra curiosità 🙂 e con un semplice click del mouse, andiamo ad inserire il nostro commento. Il codice non sarà modificato: tutte queste informazioni saranno inserite nel db di FishEye. In questo modo possiamo iniziare una discussione che può terminare con una richiesta di intervento, esattamente come viene fatto per JIRA.

Da queste richieste è possibile andare a generare la richiesta di intervento sotto JIRA. Se abbiamo eseguito le operazioni di Application Link tra JIRA e FishEye, allora possiamo anche eseguire questa operazione, assegnando la modifica del codice.

Tutte le attività sotto Crucible sono comunque tracciate:

Ogni singolo commento viene tracciato e, in caso di necessità, è possibile risalire all’iter che ha portato alla modifica oppure alla mancata modifica del sorgente.

Tramite apposite Dashboard, abbiamo la possibilità di avere sempre la situazione completa delle Reviews in corso, quali chiuse, quali sono sfociate in segnalazioni JIRA, etc. 🙂
Conclusioni
Abbiamo visto come lavorare sotto Crucible, come gestire una Code Review e come poter sfruttare al meglio FishEye e come intergrarlo con i vari applicativi della Atlassian. Nei prossimi post andremo a visionare altre funzionalità.
Riferimenti
Manualistica: