Scaviamo in profondità
In questo post andremo a vedere, con alcuni esempi, come possiamo accedere ai dati di Confluence e JIRA, lavorando direttamente su DB. In particolare vedremo alcuni esempi di come sono memorizzate le informazioni. In figura vediamo lo schema delle tabelle di Confluence.

Perché accedere ai dati?
Prima di iniziare ad esplorare le tabelle dei due sistemi, conviene porsi una domanda fondamentale: Perché dobbiamo accedere direttamente ai dati del DB? Quale è la necessità?
Uno dei motivi più importanti è sicuramente quello di dover accedere ad informazioni a cui non si avrebbe altrimenti accesso, oppure il dover eseguire una operazione massiva. Questo perché non sempre è possibile eseguire una operazione su di una grossa mole di dati, in quanto Confluence/JIRA non la consentono, come ribadito in altri post di questo blog. Fino a quando non saranno disponibili delle funzionalità di un certo tipo, occorre dover agire direttamente da DB. In aggiunta, queste informazioni sono sicuramente utili a coloro che vogliono sviluppare addon per i prodotti Atlassian 🙂
Precauzioni

Prima di agire, occorre sempre che siano prese delle semplici precauzioni. Il motivo mi sembra abbastanza semplice: Quando si lavora direttamente su DB, è abbastanza facile arrecare danni. Di conseguenza, sempre meglio avere un backup dei dati/tabelle/DB intero prima di procedere con le modifiche.
Il mio consiglio è sempre quello di avere a disposizione un backup del DB completo + una copia delle tabelle su cui si agisce, prima di procedere con qualsiasi operazione.
Un primo esempio
Supponiamo che si voglia modificare gli avatar standard, con un avatar differente (i motivi possono essere qualsiasi: Marketing aziendale, impostare un avatar di default più carino, etc).
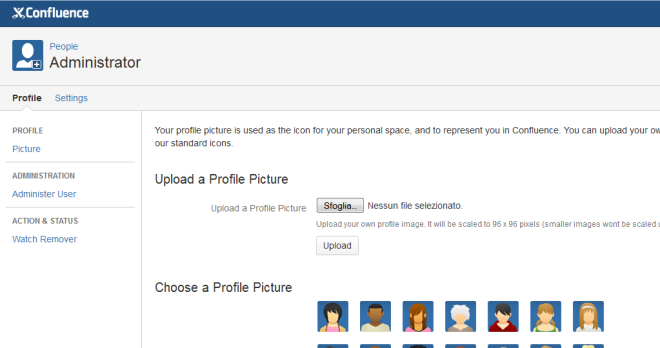
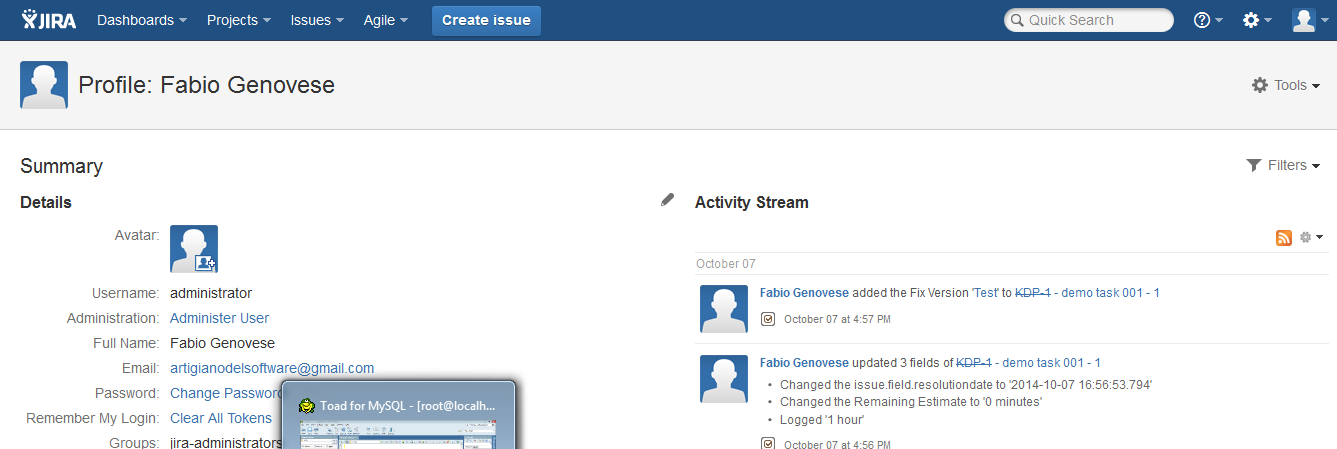
Al momento, solo gli utenti possono modificare il proprio avatar. A livello di amministrazione, non è possibile eseguire tale operazione. La precedente immagine mostra dove è possibile eseguire tale operazione. Adesso vediamo come è possibile aggirare tale limitazione, semplicemente andando a lavorare su DB.
In prima battuta esaminiamo le tabelle dove sono contenute le informazioni delle utenze. In particolare faremo riferimento a:
- cwd_user – Tabella contenente le informazioni degli utenti che sono stati configurati in Confluence.
- cwd_group – Tabella contenente le informazioni dei gruppi definiti su Confluence.
- os_propertyentry – Tabella contenente anche le informazioni degli avatar.
- user_mapping – Tabella contenente la corrispondenza uid – nome utente.
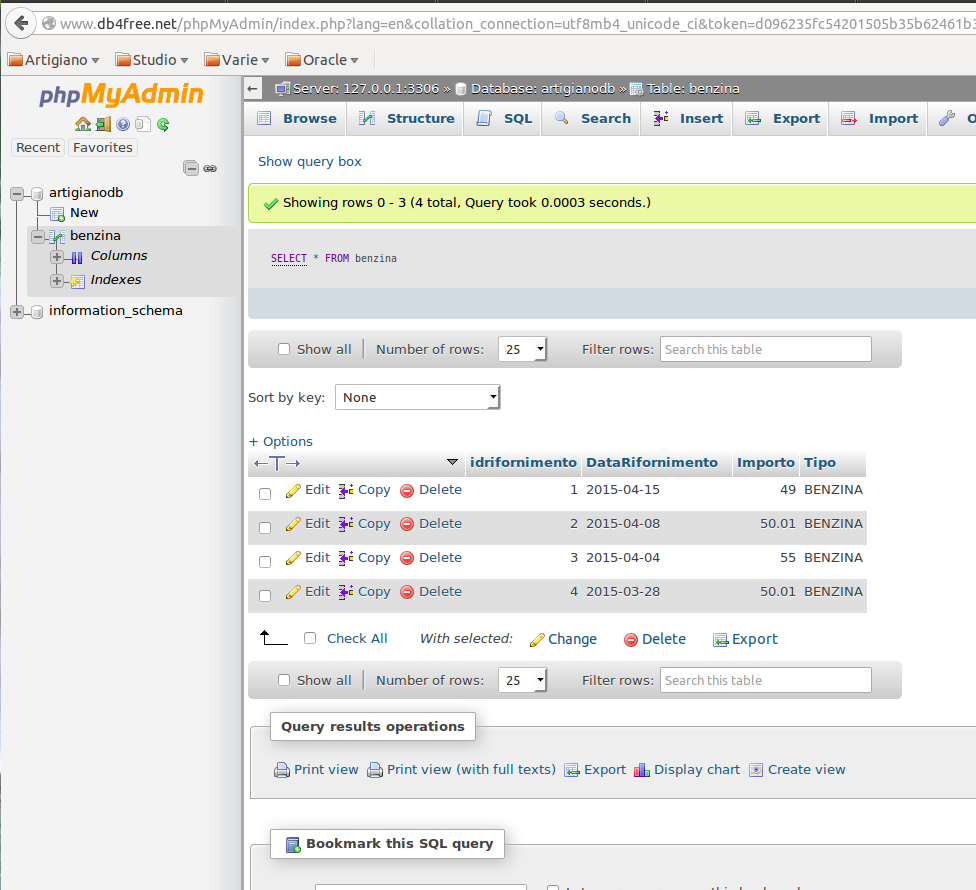
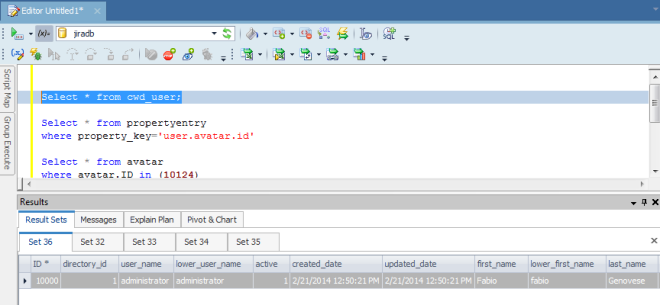
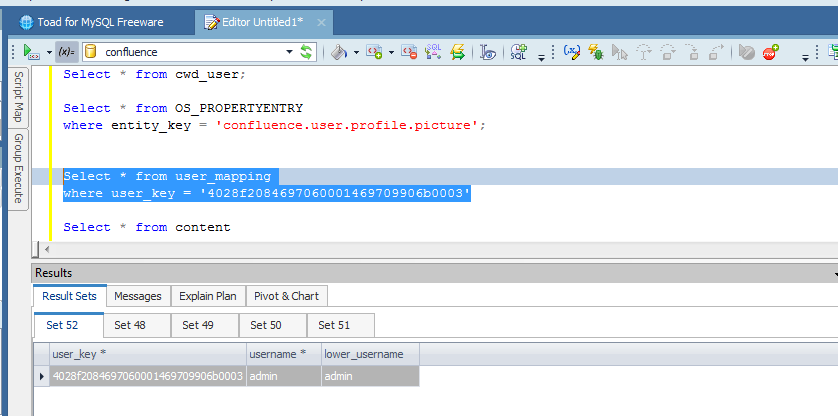
La tabella che ci interessa in particolare è l’ultima. Dobbiamo andare a cercare le informazioni degli avatar, utilizzando questa query:
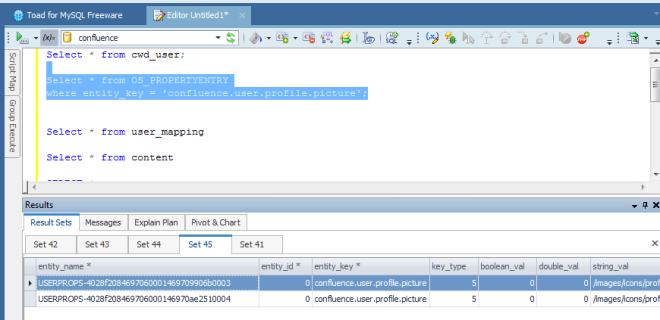
Come si vede dalla precedente immagine, quello che dobbiamo andare a cercare è il campo String_val. In questo campo è presente la localizzazione dell’avatar. In questo caso ho assegnato un avatar di default. 🙂 Nel campo Entity_name abbiamo la userid. Come possiamo vedere è abbastanza ….. criptata. Come facciamo a decodificarla? Il giro è il seguente:
- Dalla tabella os_propertyentry abbiamo le indicazioni del path della immagine
- Dalla tabella user_mapping abbiamo le indicazioni dell’uid dell’utente
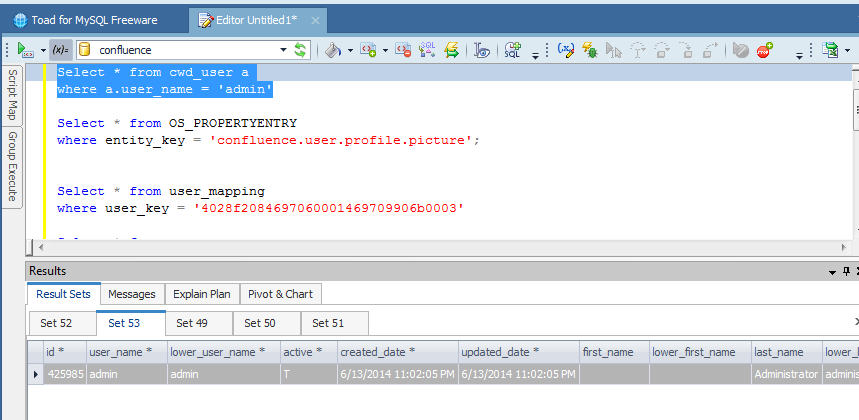
- Dalla tabella cwd_user abbiamo il nome dell’utente.
Le seguenti immagini chiariscono il tutto: Dall’ID identifichiamo l’utente

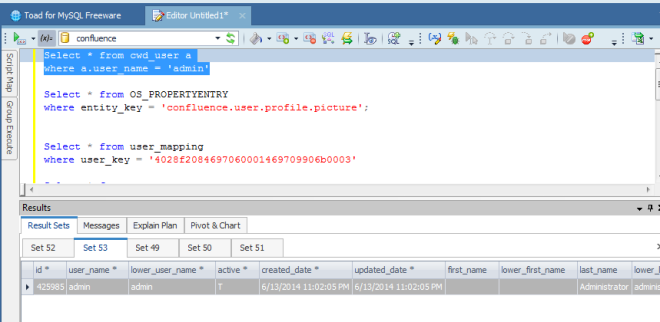
Di conseguenza, per modificare l’avatar dell’utente admin (in questo caso), possiamo semplicemente modificare il path e andare ad assegnarne uno nuovo. Supponiamo di creare una sottodirectory nel path utilizzato da Confluence per gestire gli avatar di default, ovvero:
<Install_dir_Confluence>confluenceimagesiconsprofilepic
supponiamo di chiamarla Demoprofile e di memorizzare il seguente avatar:

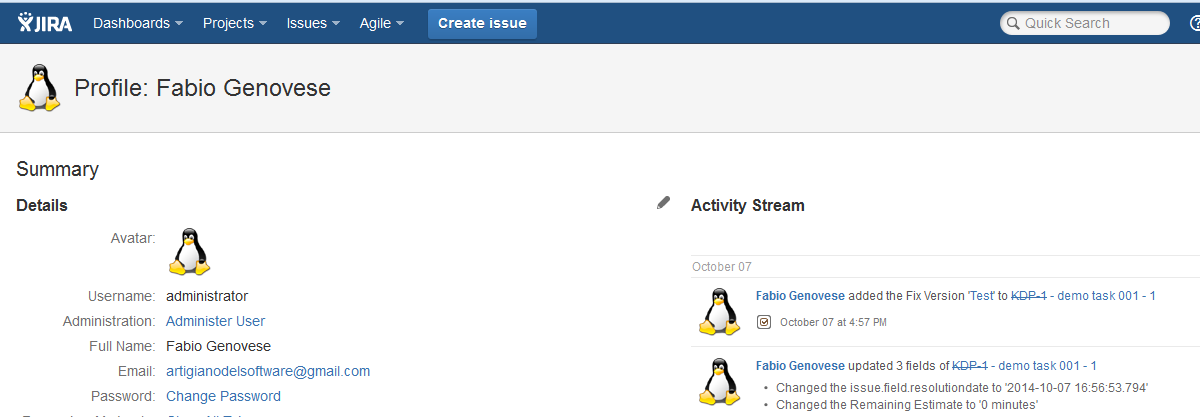
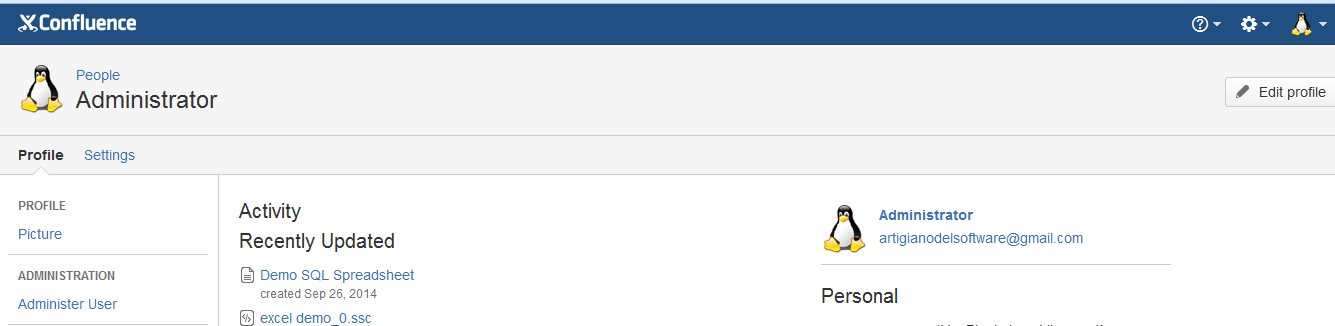
Eseguire il restart del servizio Confluence e, come per magia, il risultato sarà il seguente:
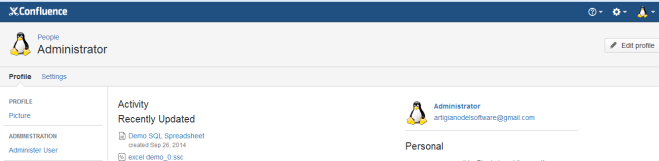
Conclusioni
Abbiamo visto un esempio di come si può modificare il database per modificare gli avatar degli utenti di Confluence. Questo esempio può essere utilizzato anche per le installazioni per cui gli utenti sono presi da LDAP e non sono solo utenti locali di Confluence. Nei prossimi post vedremo altri esempi di come si può accedere ai dati e …. vedere altre informazioni.













{kind=link}