Aggiungiamo un pò di sicurezza su Confluence Cloud – Parte 1
Nell’ambito di una organizzazione aziendale, la vera ricchezza è data da due fattori che considero FONDAMENTALI:
- Le persone, attraverso le quali si fa la vera differenza
- Le informazioni aziendali, che rappresentano una ricchezza non indifferente
Chiunque utilizza Confluence sa perfettamente che mantenere al sicuro le informazioni aziendali è di vitale importanza: facendo un paragone militare, è come mantenere efficienti le armi del proprio esercito. In questo post andremo ad esaminare un addon che ci permette di mantenere sempre sotto controllo la nostra istanza cloud di Confluence.

Cosa ci offre lo standard
Lo Standard ci offre non tantissime funzionalità: Abbiamo a disposizione l’Audit Log, che ci permette di capire chi ha fatto cosa, ma non abbiamo un dettaglio molto alto.
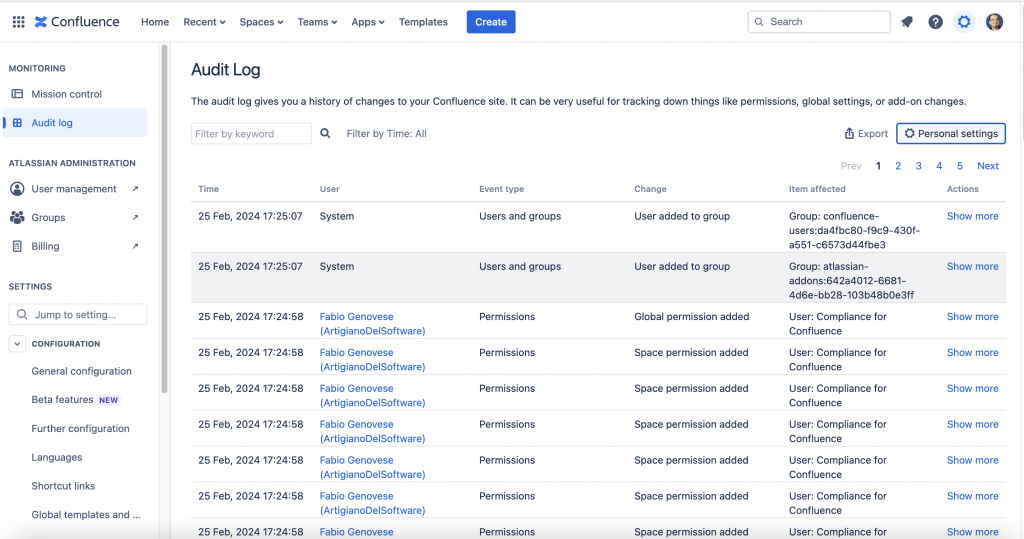
Aggiungiamo che non abbiamo un dettaglio molto spinto. Di conseguenza non possiamo raggiungere il nostro obiettivo con queste funzioni. Capiamo allora cosa occorre aggiungere: quale addon; per arrivare ad un buon risultato
Un addon lo abbiamo identificato…
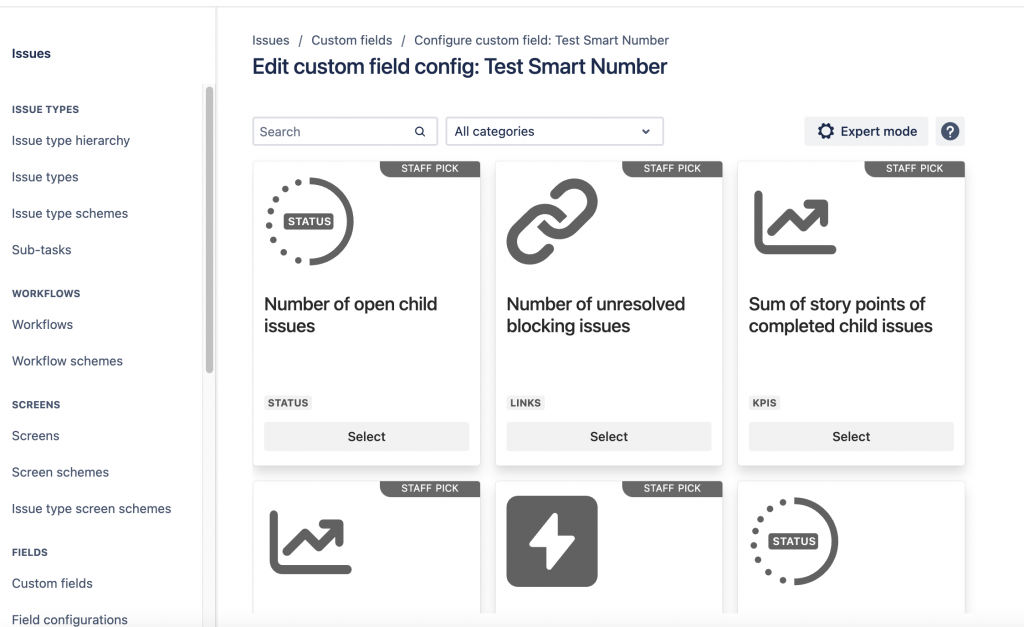
Si tratta di Compliance for Confluence, che permette di poter impostare una serie di funzionalità di controllo e monitoraggio che ci aiutano. Andiamo a curiosare:
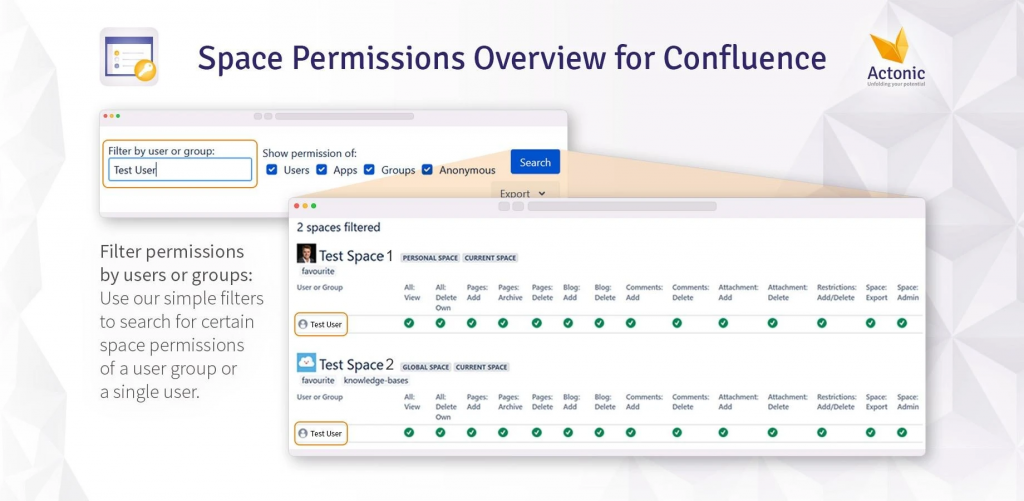
La prima cosa che notiamo è che ci permette di poter identificare i dati sensibili. In questo modo riusciamo a tracciare tutti i punti dove intervenire per lavorare sulla riservatezza:

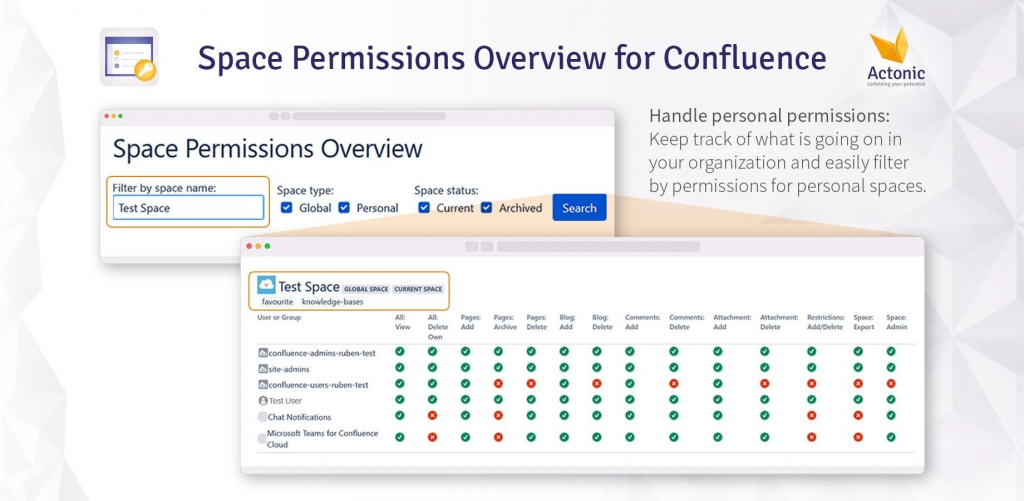
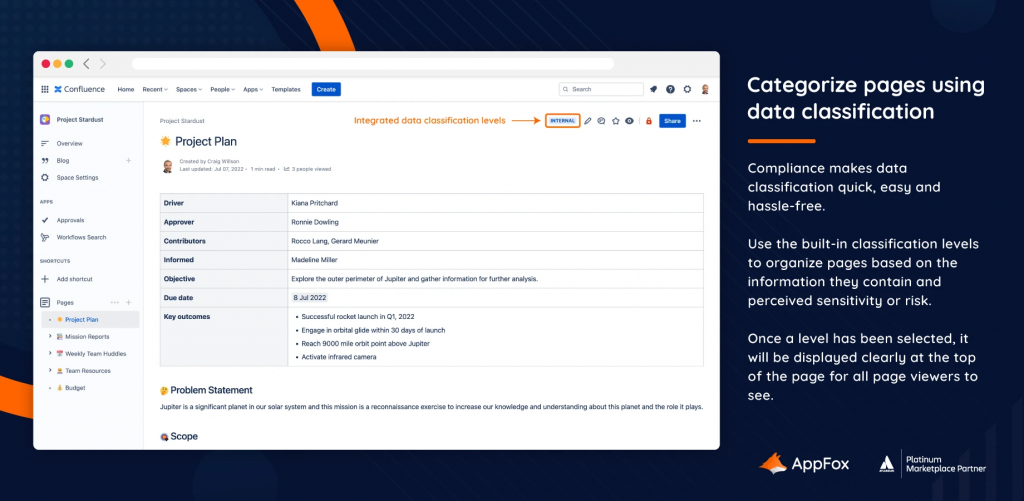
L’addon estende le funzioni base di Confluence permettendo di classificare le pagine in maniera opportuna. Questo ci permette di classificare le pagine assegnando loro un livello di riservatezza.

L’assegnazione di questi livelli ci permette di poter assegnare anche opportuni permessi per poter gestire gli accessi alle pagine

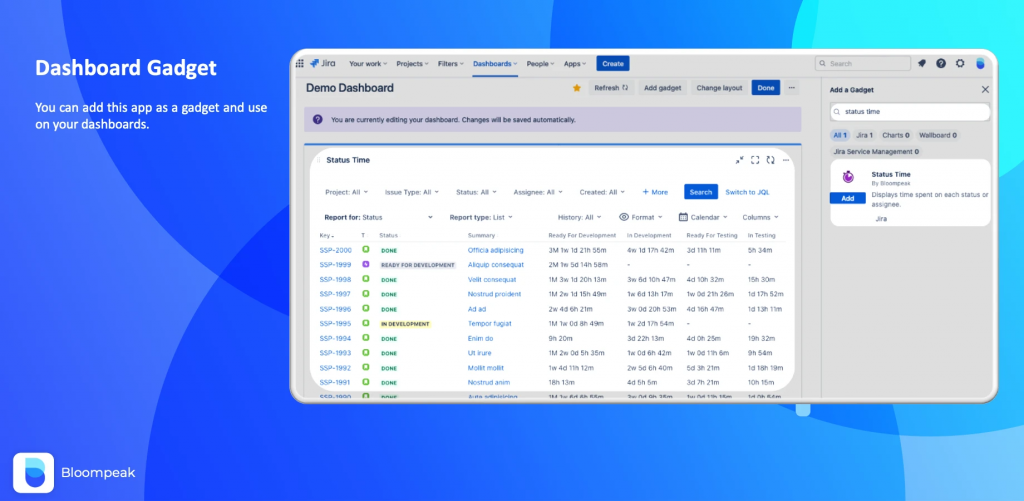
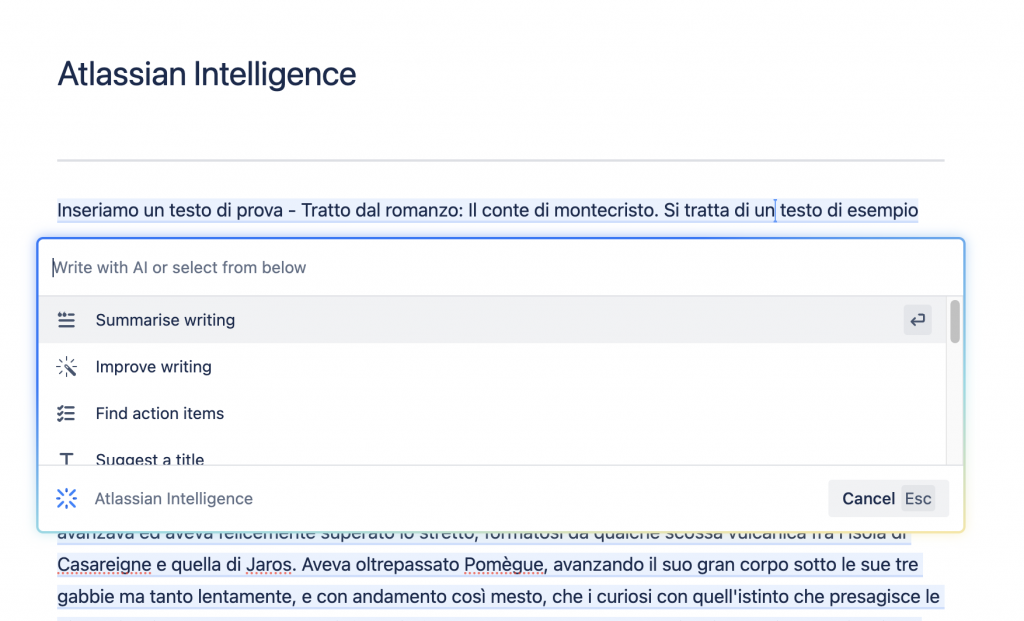
La seguente immagine ci permette di poter vedere il risultato finale che abbiamo a disposizione con l’addon
Spettacolo, lo installo subito
Visti i risultati, sono supercurioso e partiamo dalla installazione. La seguente GIF ci descrive meglio il processo:
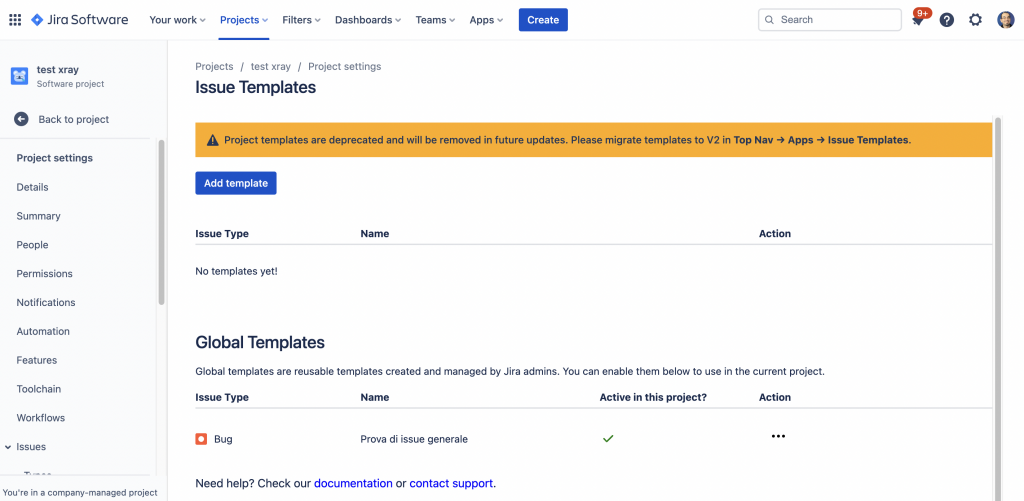
Procediamo quindi con la configurazione Generale….. che non è proprio semplice. Qui abbiamo la necessità di diverso tempo per descriverla: Mettetevi comodi e prendete appunti:

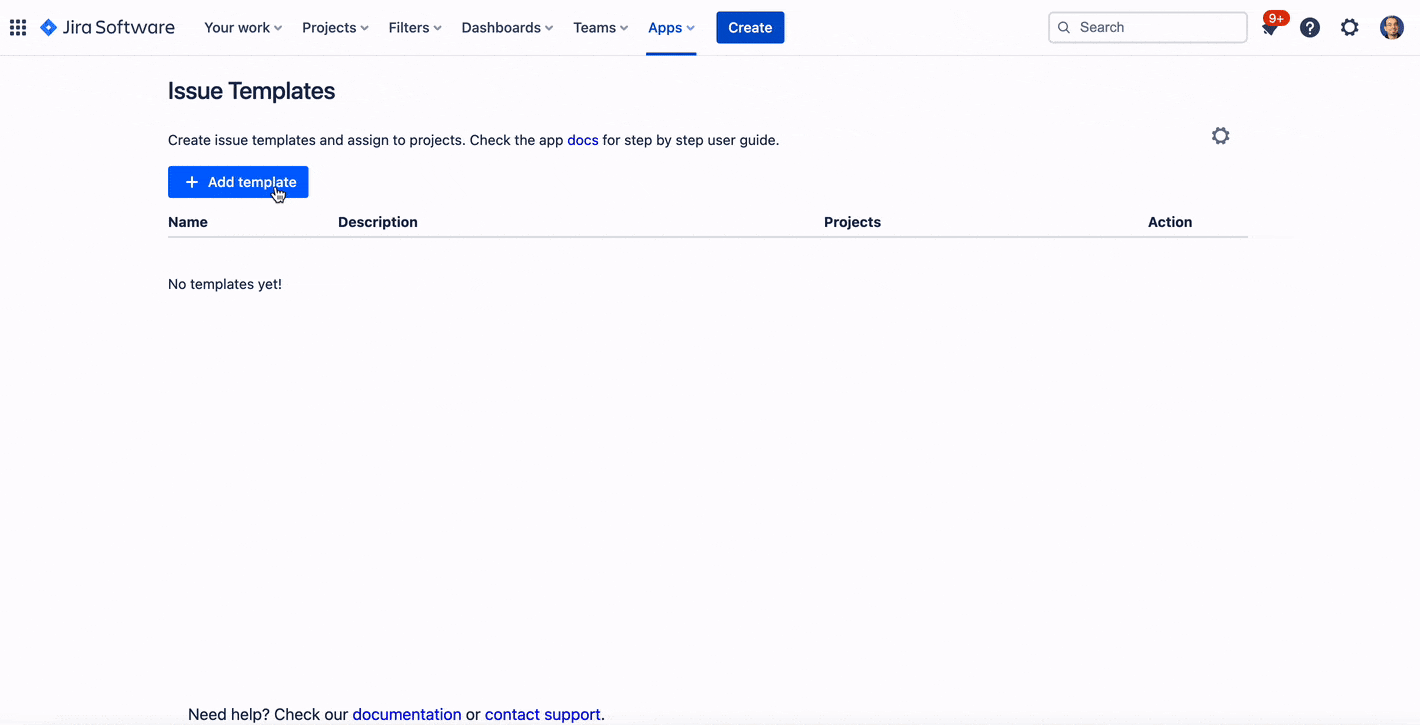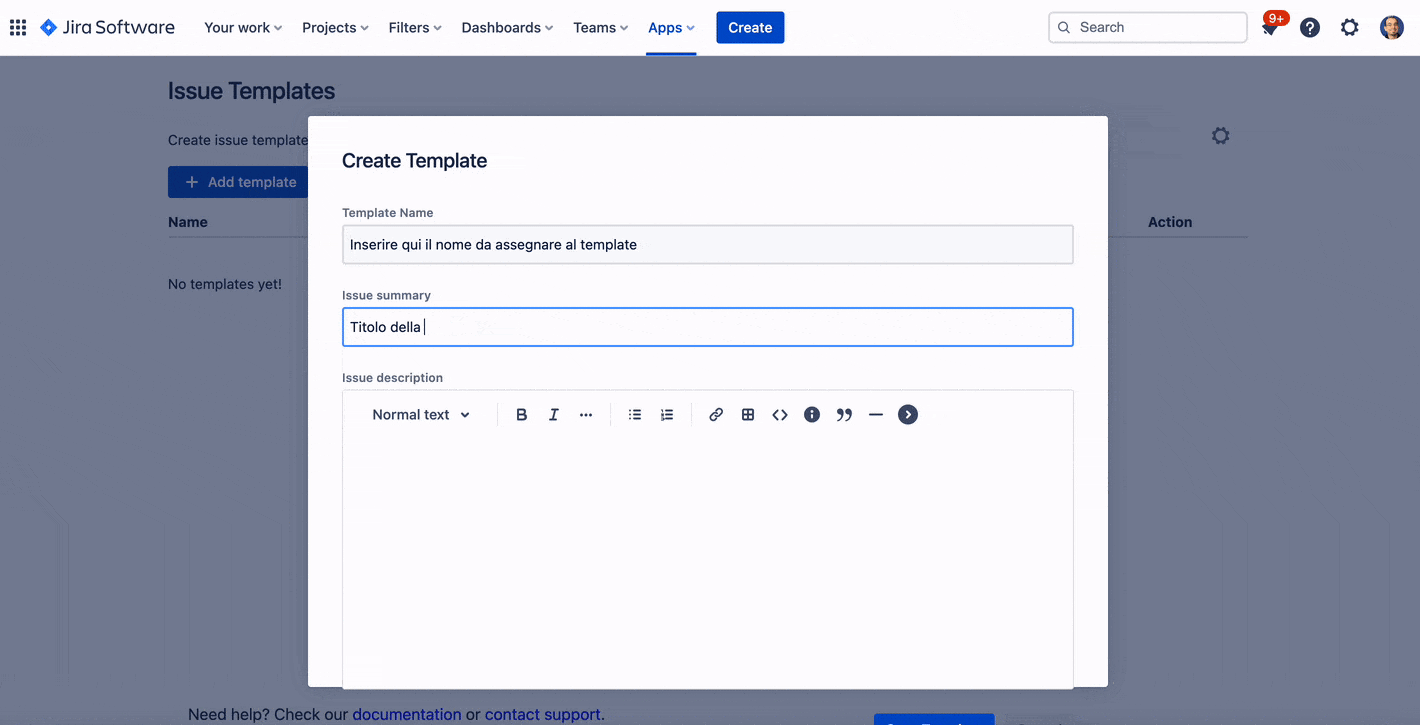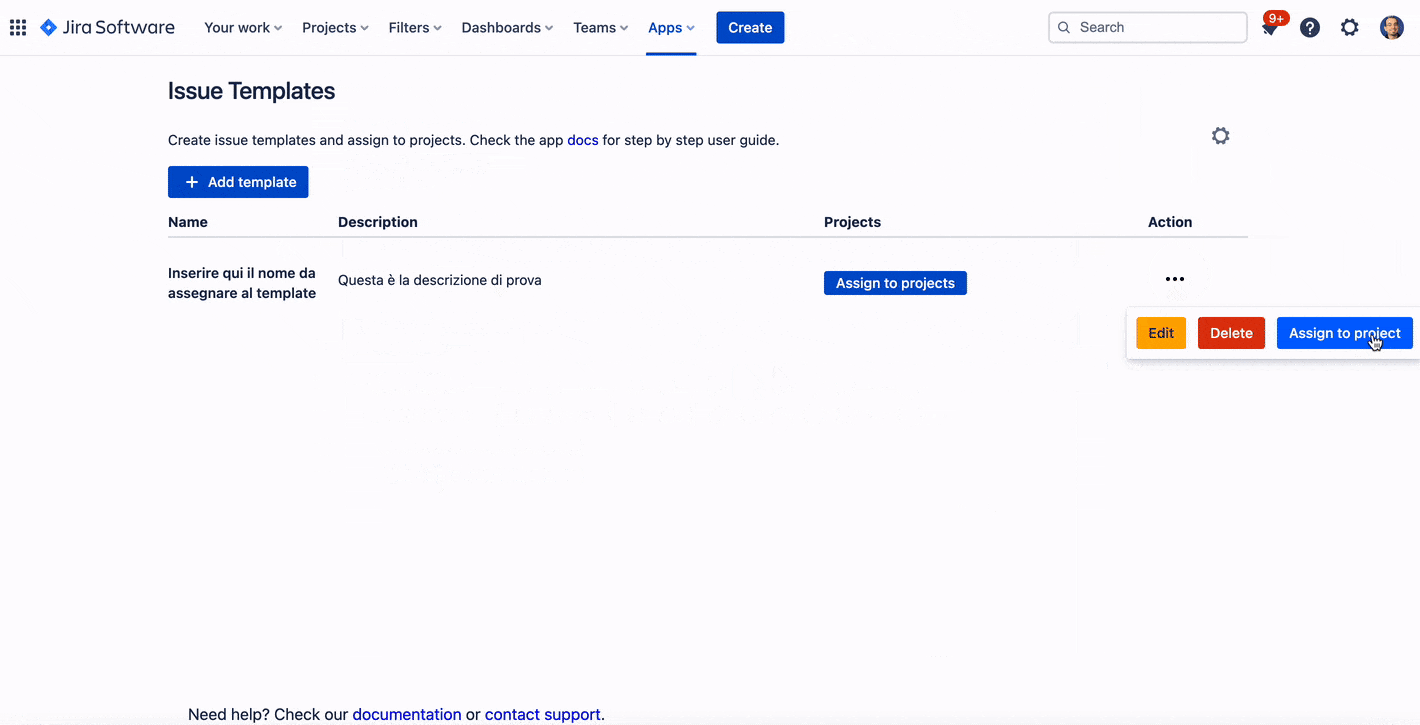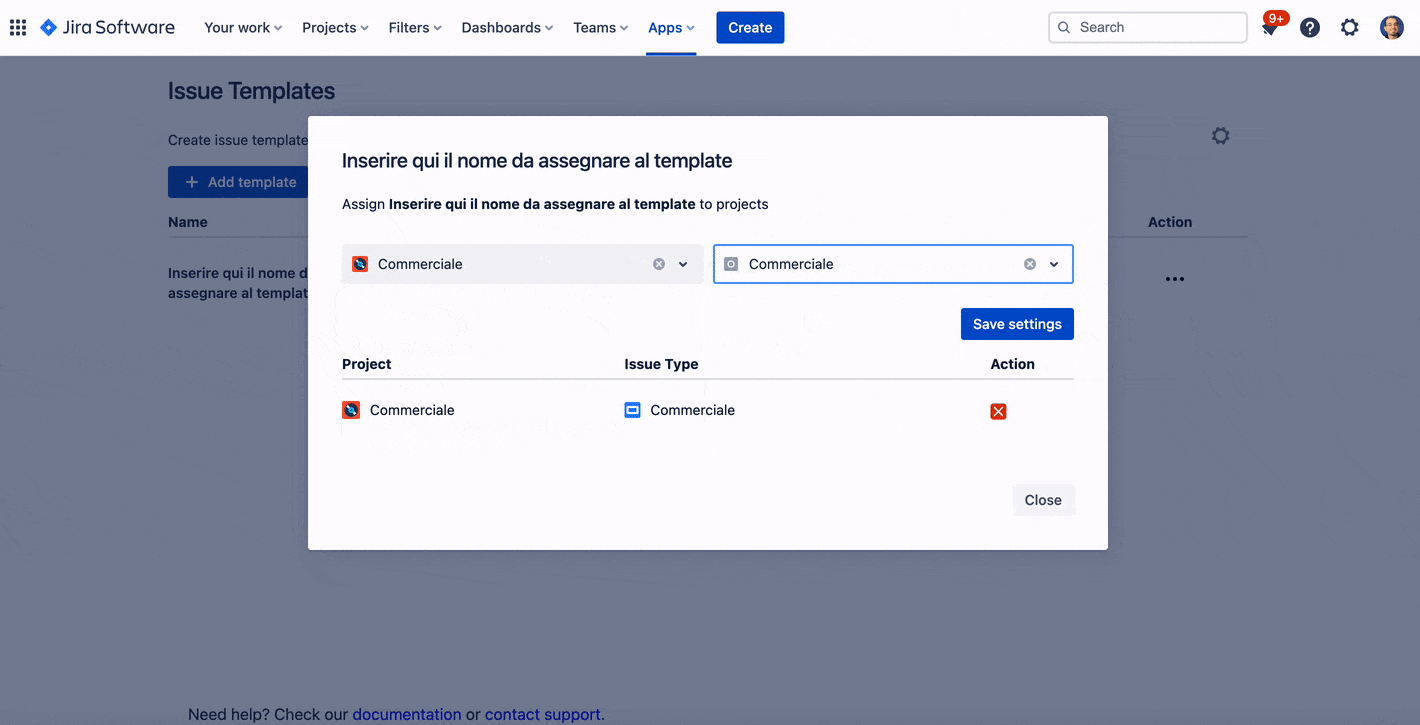
Selezioniamo le opzioni dell’addon andando a selezionare dal menù Apps –> Compliance, come mostrato nella seguente immagine

Viene quindi mostrata all’utente la maschera di gestione dell’addon

Sulla sinistra abbiamo a disposizione i menù di gestione e di configuirazione, con tutti i settaggi
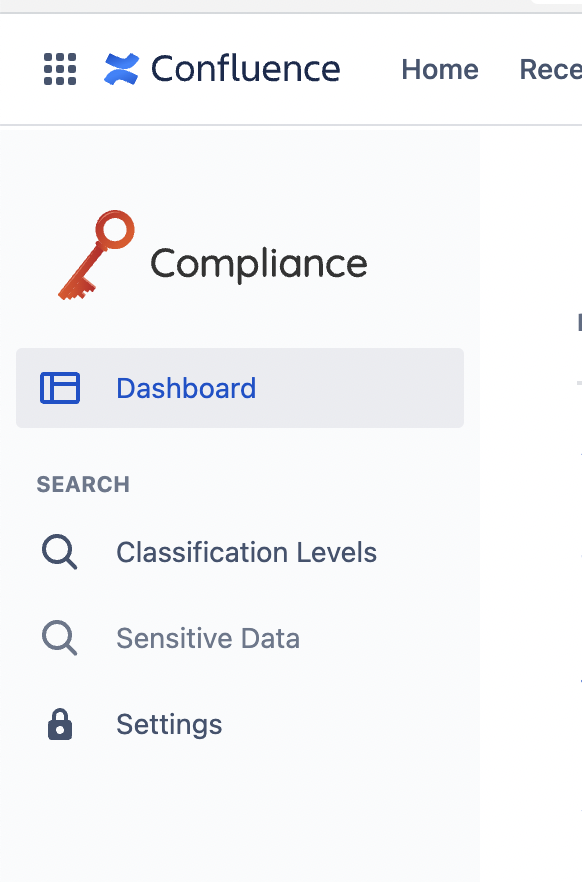
Se selezioniamo Settings, Possiamo visualizzare tutte le possibili configurazioni che sono disponibili lato addon:
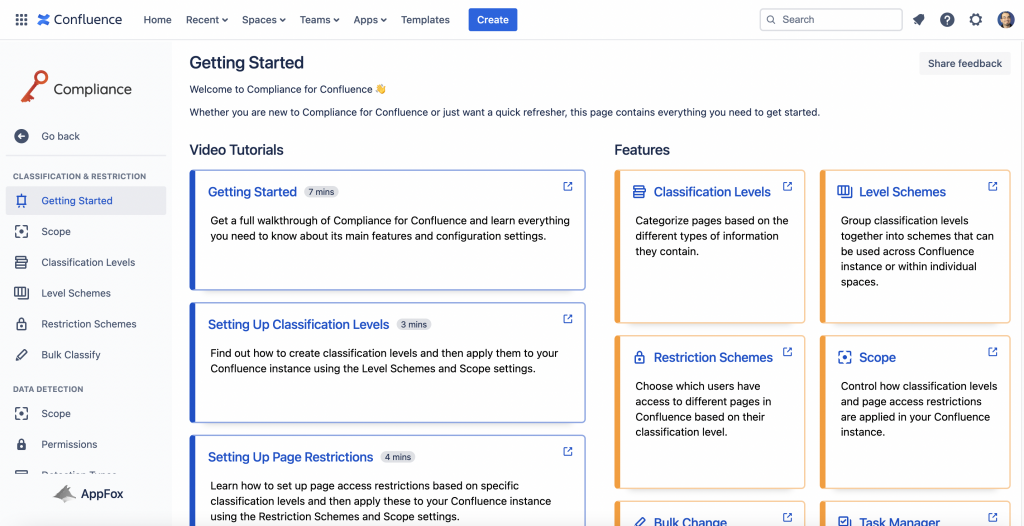
Abbiamo un discreto numero di possibilità e di configurazioni. Un passo alla volta. La prima cosa che notiamo è quella di un insieme di video tutorial, che ci permettono di poter imparare al volissimo queste funzionalità. In questo caso, gli autori dell’addon sono stati lungimiranti in quanto mettono a disposizione tutti i mezzi per poter imparare al meglio le funzioni e le configurazioni dell’addon.
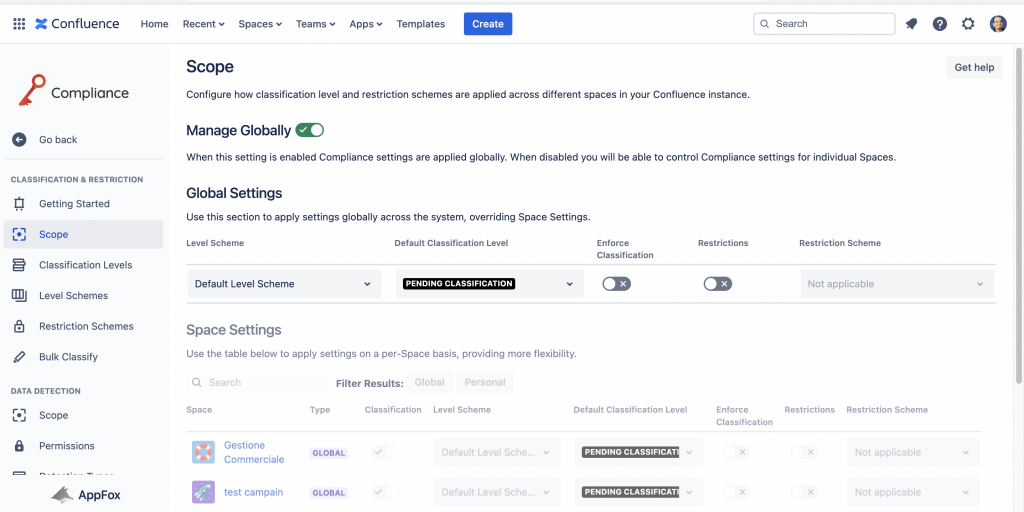
L’addon ci mette a disposizione una funzionalità interessante, ovvero la possibilitàò di applicare le funzioni dell’addon a livello globale o di singolo Space Confluence. Questo di permette di poter scegliere ciò che ci risulta più agevole per noi.
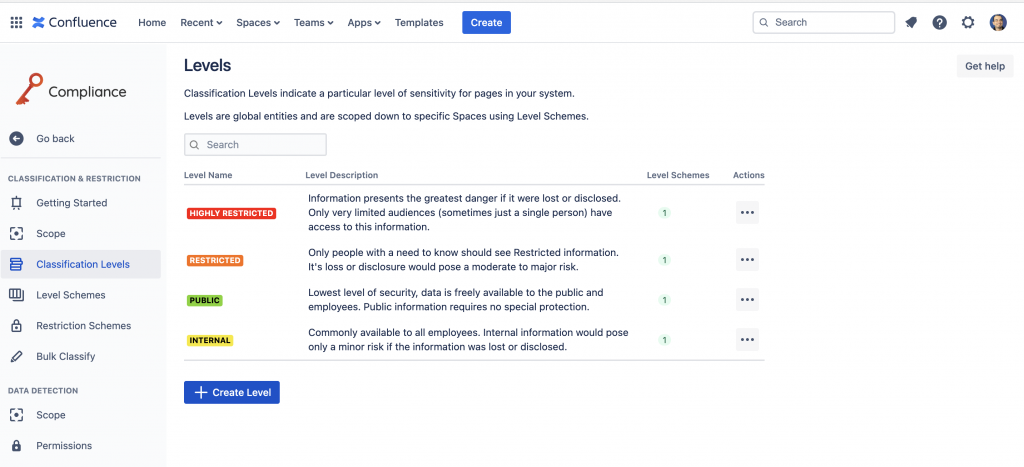
Altra configurazione importante: Possiamo classificare i livelli che ci interessano. L’addon viene fornito con una prima configurazione di base, a mio giudizio, molto completa, ma avere la possibiloità di poter gestire questa configurazione, ci permette di specializzare la nostra istanza come meglio riteniamo opportuno.
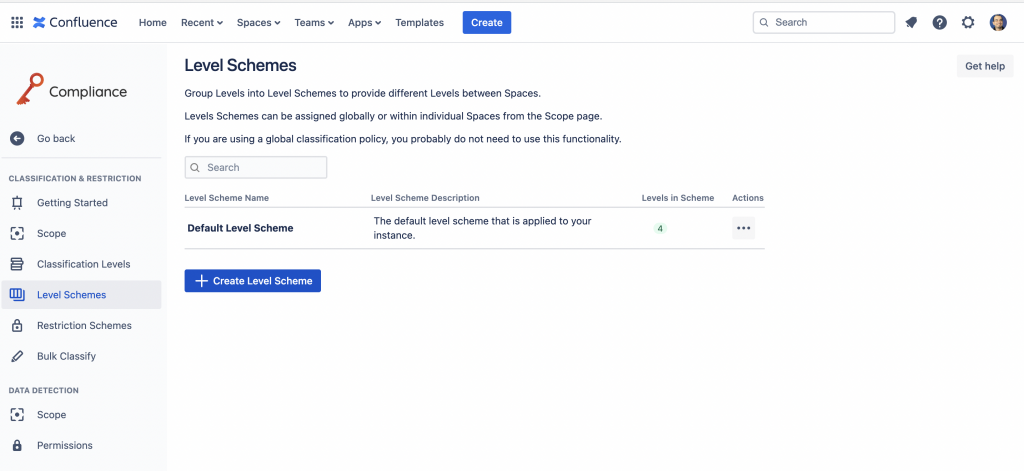
Questa configurazione ci ricorda qualcosa, ma direi più verso Jira. L’addon introduce uno scheme, una configurazione che ci permette di defiunire classi di livelli da poter poi applicare su diversi space o di default direttamente su tutta la nostra istanza.
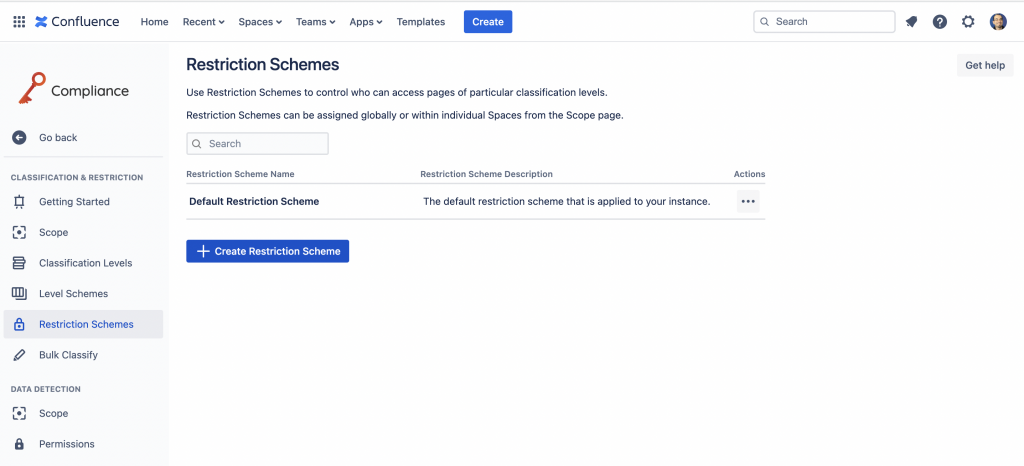
Siamo a due: Devono averci preso gusto. I produttori dell’addon hanno introdotto anche uno scheme per gestire gli accessi in base ai livelli di classificazione. Anche in questo caso abbiamo la doppia possibilità di avere una configurazione su tutta l’istanza che una configurazione su alcuni Space.
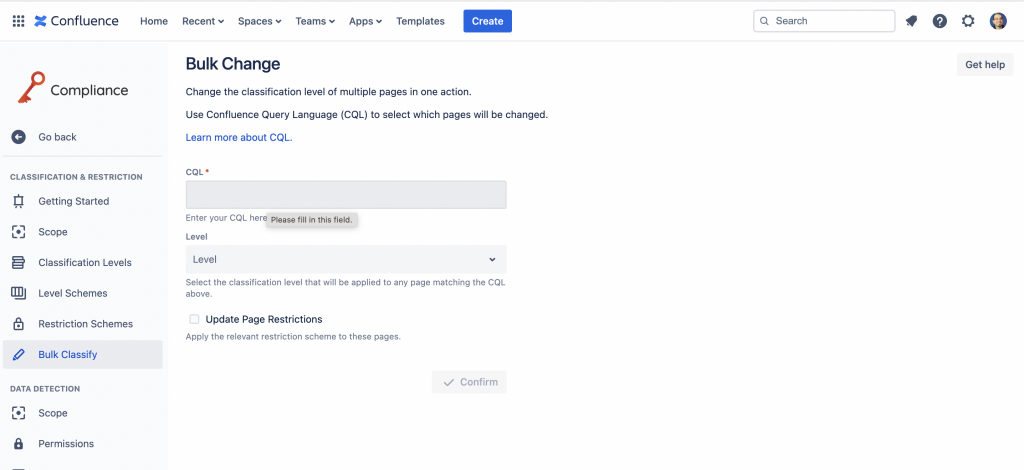
Una altra funzionalità interessante è la possibilità di eseguire una assegnazione via bulk, sulla falsariga delle Bulk operation di Jira, usando il CQL (Confluence Query Language) per selezionare i contenuti. Funzione importante perché ci permette di selezionare velocemente i contenuti cui assegnare (come primo setup) il livello interessato.
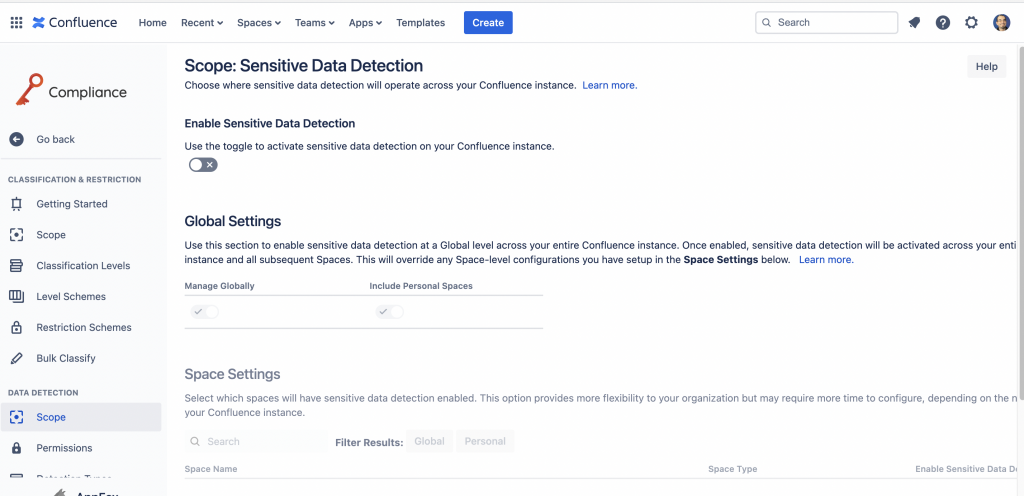
Adesso porto carico, perché andiamo ad esaminare una funzione molto interessante: L’addon ci permette di eseguire uno scanning della nostra istanza per identificare i dati sensibili presenti.

Questa configurazione ci permette di poter gestire la visualizzazione dei dati sensibili, permettendoci di gestire quali gruppi sono autorizzati oppure no. In alternativa ci consente di aprire tale visualizzazione a tutti gli utenti. Manca una cosa. Come definiamo quali sono i dati sensibili?? Tranquillità: lo sappiamo bene perché i produttori dell’addon lo hanno previsto.
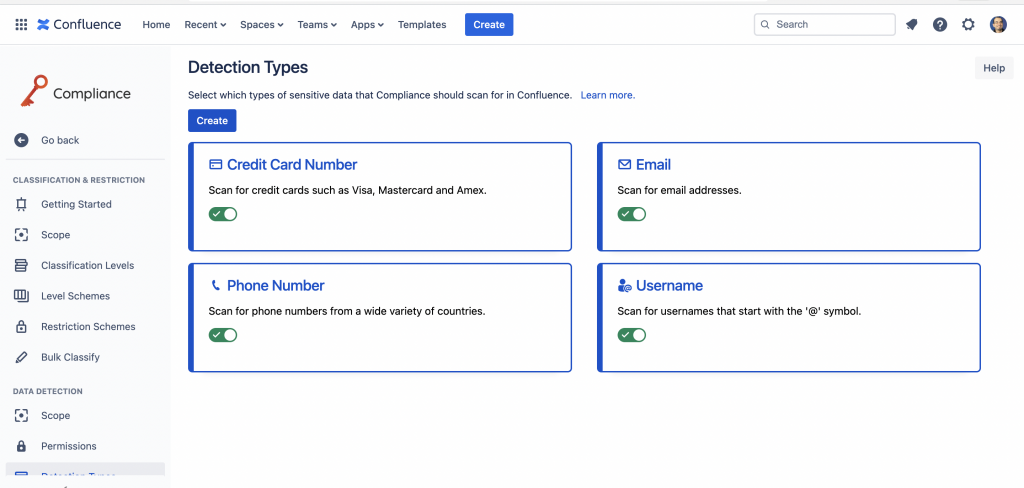
questa funzionalitòà ci permette di poter identificare cosa è dato sensibile e permette all’addon di andarlo a ricercare.
Fine prima parte
Chiudiamo l’articolo con questa prima carrellata di descrizione dell’addon. Nel prossimo articolo andremo a vedere la prova di utilizzo che abbiamo eseguito. vi assicuro che non rimarrete delusi.
Reference
Maggiori informazioni sono reperibili alla pagina del Marketplace.