Calculated custom fields arrived in Jira Cloud! Con questo annuncio non possiamo che essere curiosi di questo addon che ci permette di poter gestire al meglio i campi calcolati (che sono la nostra croce e delizia su Jira) e che ci permettono di raggiungere grandi risultati. Andiamo a curiosare
Modello Flash, andiamo a curiosare immediatamente
Di cosa tratta l’addon?
Questo addon ci permette di poter creare dei campi calcolati preconfigurati che ci possono aiutare tutti i giorni. Sappiamo bene che su ambiente Jira Cloud abbiamo qualche problema con i campi calcolati: Non ne abbiamo.
Alcune delle espressioni facciali che assumiamo quando lo scopriamo. La faccia allegra è l’utente sadico (Scherzo ovviamente) 😀
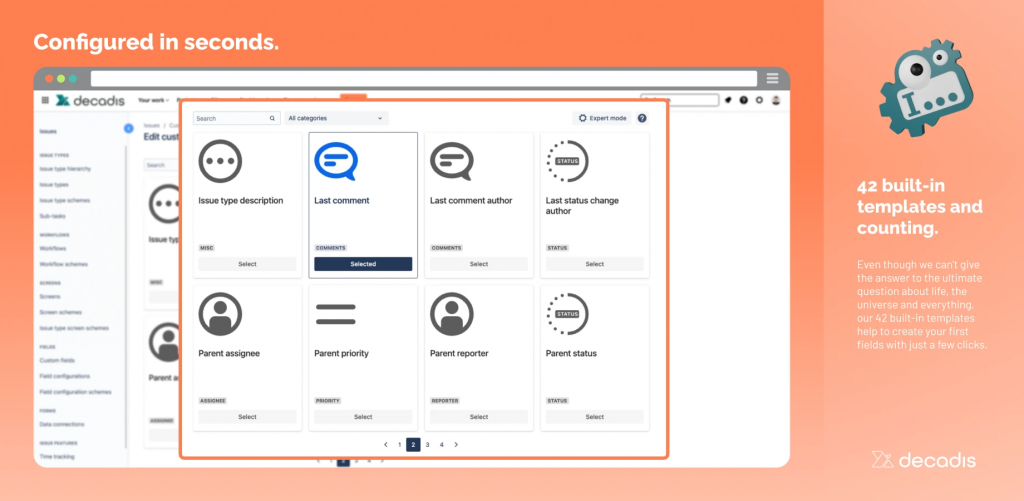
Questo addon ci permette di poter rimediare a questa situazione strana. Abbiamo la possibiità di poter scegliere tra circa 42 diversi tipi di campi calcolati.
Fonte Marketplace: Alcuni esempi di possibili campi calcolati
E’ interessante disporre di tali campi già pronti. In questo modo possiamo usare direttamente senza tanti problemi. Come possiamo vedere dalla seguente immagine, molti di questi campi già coprono diverse necessità (anche se, da buon Italiano dico: Ma ci sarebbe anche il campo calcolato …… 😛 )
Fonte Marketplace: Alcuni esempi.
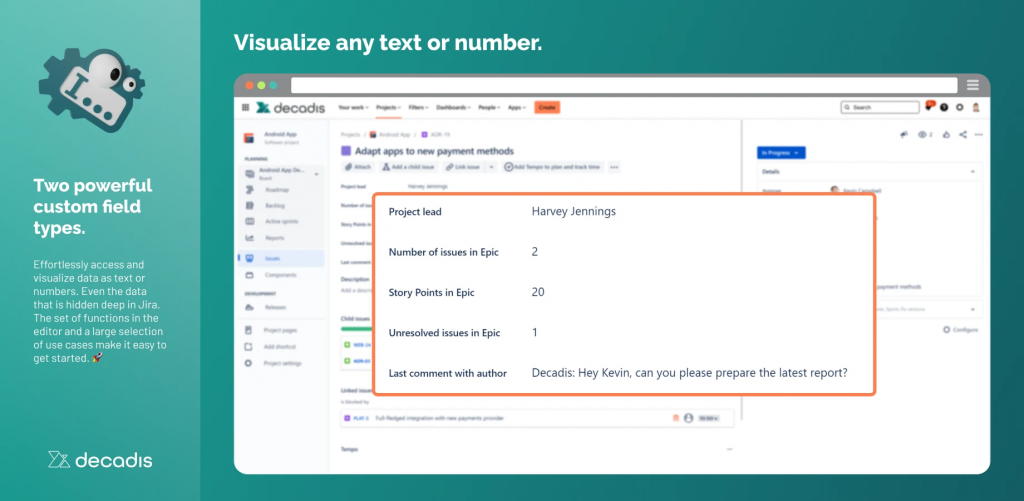
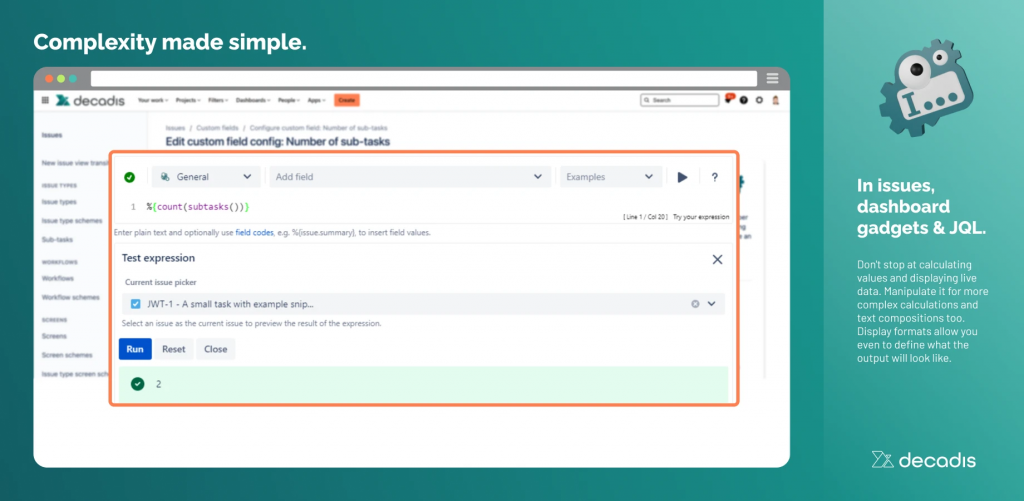
ma non solo. Dalla seguente immagine:
notiamo che l’addon permette anche di manipolare le formule. Questo è INTERESSANTE perché ci permette di scatenare la nostra fantasia.
Conclusioni
Abbiamo un addon da esaminare con tantissima attenzione. Possiamo risolvere il problema dei campi calcolati, ma non è l’unico. Diamo un annuncio in anteprima: Ho identificato una soluzione da usare per generare i campi calcolati. Pubblicherò un articolo a breve,
Scrivo questo articolo a seguiuto di una analisi che ho seguito per un mio cliente e che mi ha portato a scoprire un addon molto interessante, che permette di ricavare delle statistiche sui nostri ticket. L’obiettivo era trovare una interrogazione sui dati di una istanza cloud che mostri le seguenti informazioni:
Capire quanto tempo un addon è rimasto in un determinato stato
Estrarre queste informazioni ed inserirle in un report
Fare delle statistiche molto più precise di quanto tempo un ticket è in lavorazione, quanto è in attesa di una risposta da un customer
Entriamo in modalità esplorazione
Subito al dunque
L’addon in questione è Status Time Reports Free – Time in Status, che permette di tracciare il tempo speso per i nostri ticket in ogni stato del workflow che il ticket assume in ogni istante della sua vita. Questo ci permette di ricostruire la storia di ogni ticket. Questa è la versione free dell’addon, disponibile anche nella versione a pagamento con ulteriori caratteristiche aggiuntive.
Come possiamo vedere dalle immagini del marketplace:
Fonte: Marketplace Atlassian. Un esempio delle metriche che possiamo ottenere
In questa immagine possiamo vedere quali metriche abbiamo a disposizione e che informazioni possiamo ottenere. Si tratta di un esempio, ma ci illustra anche quali caratteristiche possiamo disporre da un addon gratuito.
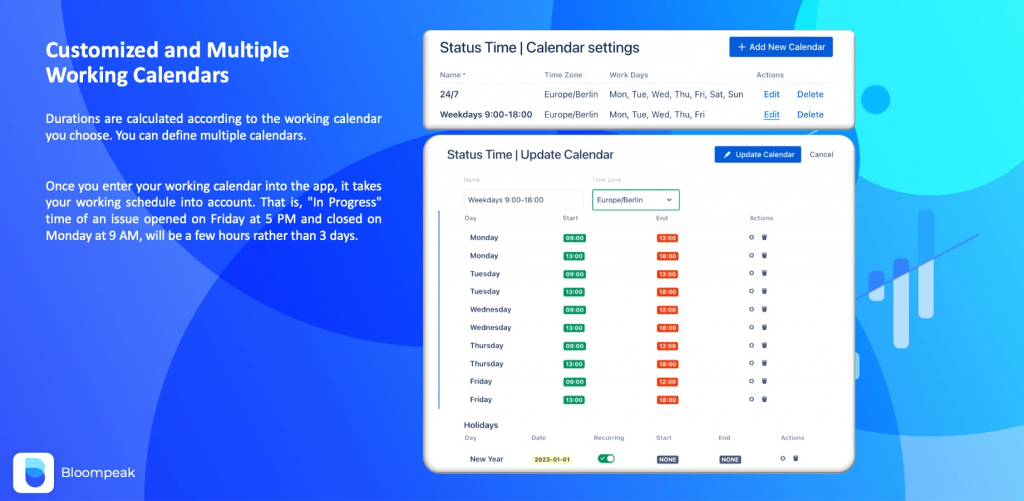
Questo addon consente di poter parametrizzare questi calcoli attraverso la definizione di un calendario:
Fonte Marketplace: Come definiamo un calendario
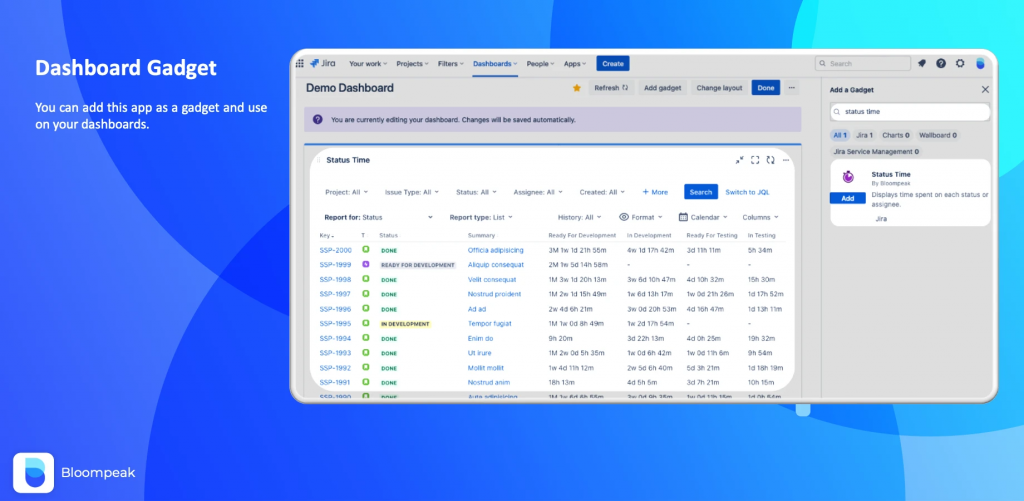
Altra caratteristica importante è la possibilità di poter disporre di un apposito Gadget da poter esporre nelle nostre Dashboard,
Fonte Marketplace: Gadget in azione.
Conclusioni
Addon interessante e sopratutto gratuito. Ci permette di tracciare una statistica relativamente al tempo impiegato (secondo il calendario parametrizzato) di un ticket in un particolare stato. Ogni stato rappresenta un determinato momento della lavorazione e ci permette di poter capire quando il ticket è in lavorazione da parte degli Agenti e quanto è in carico del customer, quanto è in carico a fornitore esterno, etc.
SI tratta di un ottimo addon. Non vedo l’ora di testarlo.
Annunciato a Teams23 a Las Vegas, il nuovo campo Teams e da poco disponibile nelle nostre installazioni Cloud. Vediamo in questo post in che cosa consiste, come funziona e che cosa permette. Entriamo in modalità ricerca.
Set Explore mode = on
Subito al sodo
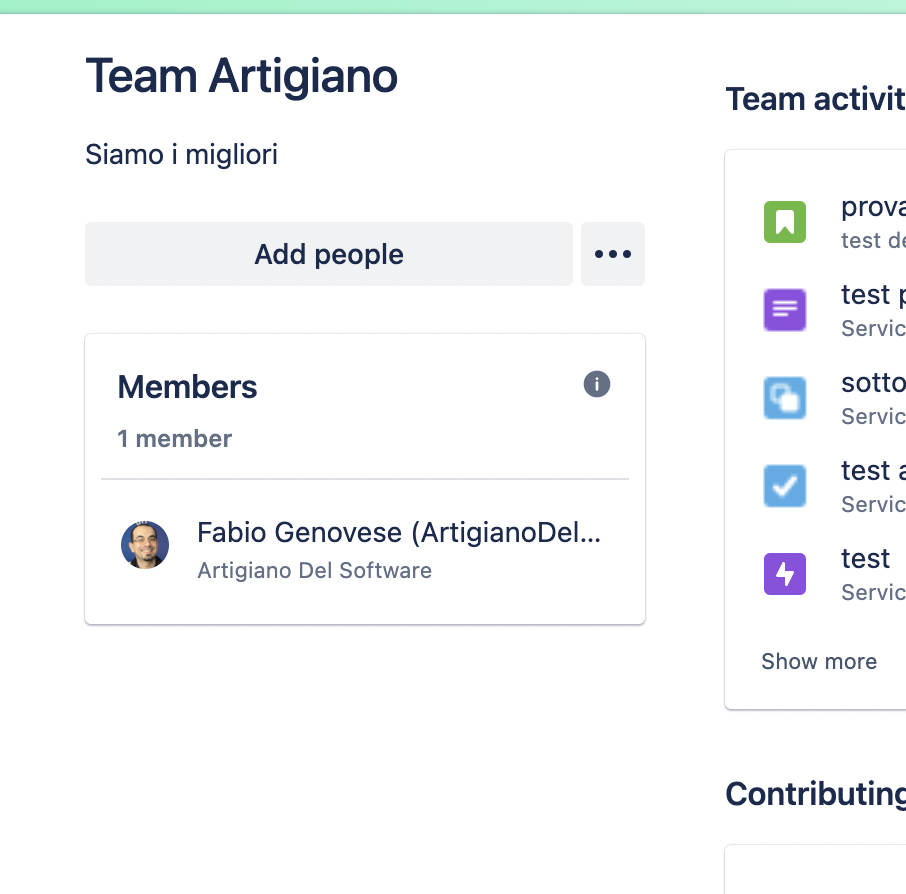
Richiesto a gran voce da tutti, questo campo permette di poter creare dei Team trasversali da poter usare nei nostri progetti, sia per assegnare le issue a gruppi (in precedenza era necessario usare altri mezzi per realizzare questa funzione) oltre che implementare delle notifiche, ma non solo. Vedremo come nei prossimi paragrafi.
Per chi non ha ancora aggiunto il campo negli screen, sono visualizzati questi messaggi
Questo nuovo campo ci permette di avere una marcia in più rispetto ai singoli gruppi. I Teams sono dei gruppi di utenti che possono essere trasversali rispetto ai gruppi che abbiamo definito nella nostra anagrafica utenti. Questi sono gestiti da una apposita funzione che non si trova ella sezione di amministrazione ma direttamente nella nostra istanza, e sono usati da più funzioni.
Questa funzione è stata derivata da Advanced Roadmap (il vecchio Portfolio for Jira), dove questa possibilità era già disponibile. Gli utilizzatori di Advanced Roadmap infatti riuscivano ad eseguire delle assegnazioni a Teams delle issue. Adesso questa funzione non e’ sola esclusiva della pianificazione, ma anche del lavoro di tutti i giorni e di tutti gli utenti.
in questa nuova gestione, i Teams hanno una definizione più ricca rispetto ai gruppi. Possiamo avere delle schede personalizzate e dedicate alle persone che li compongono.
Fonte: Documentazione Atlassian
Interessante, ma che altro e’ possibile?
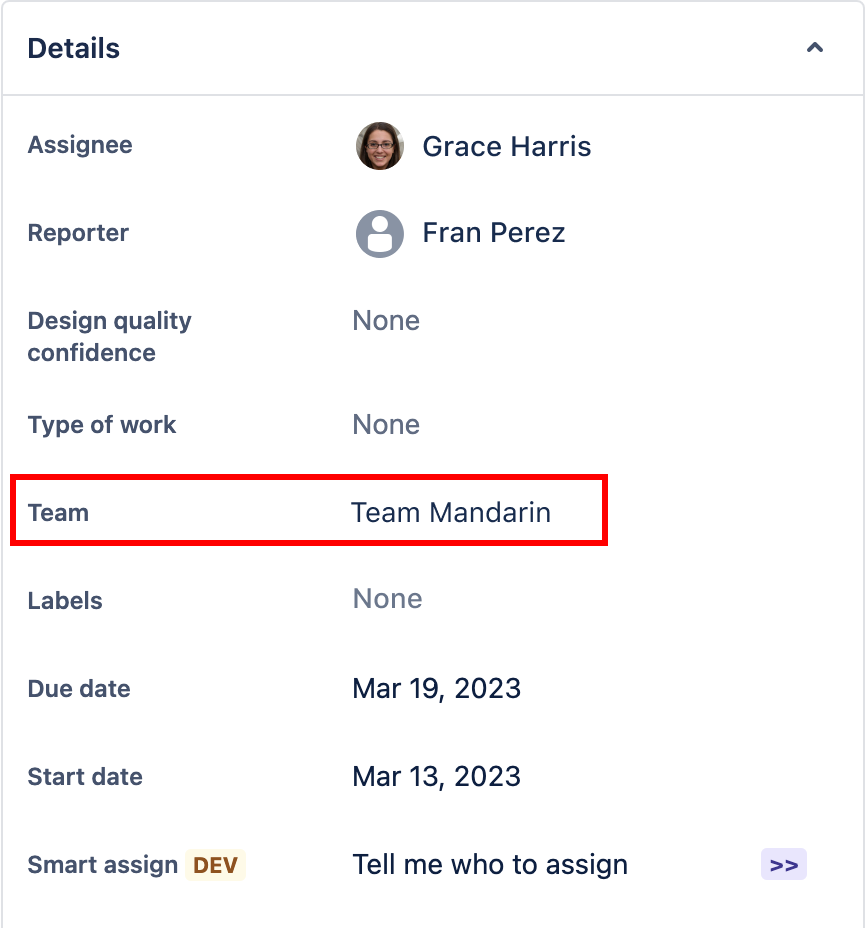
Un apposito Campo di sistema è a nostra disposizione, come qualsiasi altro campo, ma con una marcia in più. Questo campo ci permette di implementare una assegnazione a gruppi, con l’opzione di poterlo usare delle mentions per implementare notifiche. In aggiunta possiamo usarlo anche nelle nostre importanti regole di automazione.
Adesso la domanda difficile: cosa non è possibile fare?
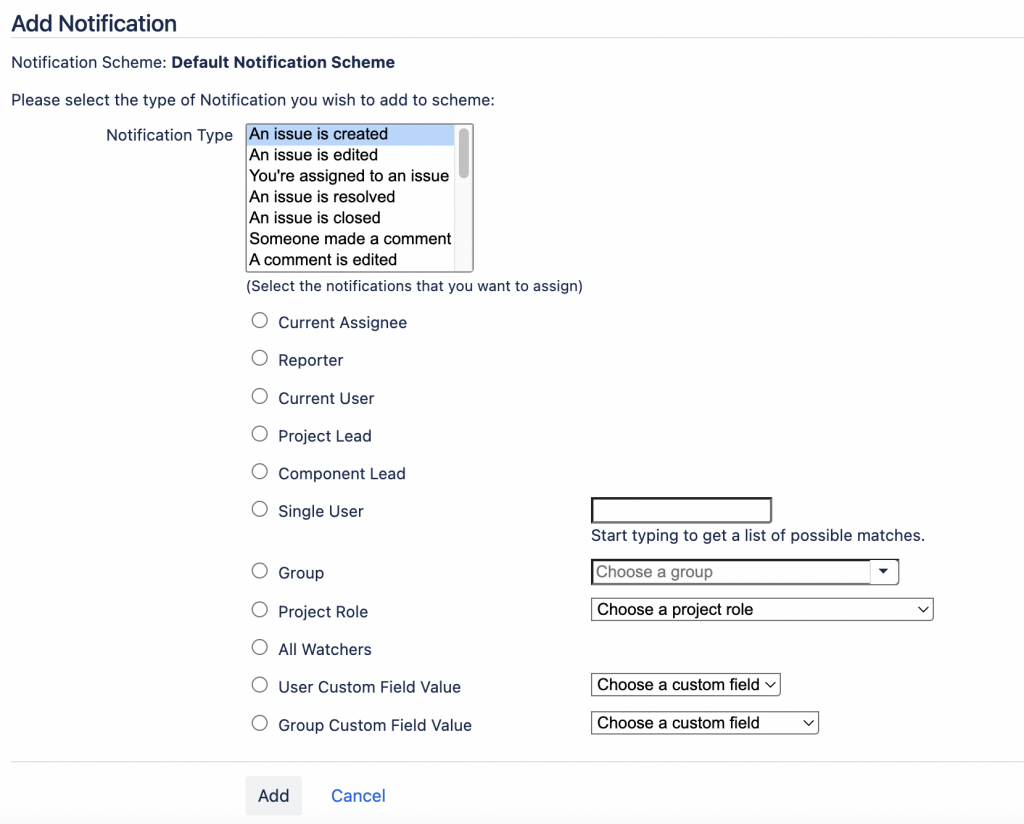
Il nuovo campo non e integrabile con il notification scheme. Questo significa che le notifiche devono essere gestite in maniera differente: mentions o regole di automation. Questo è più scomodo perché non si innesta nel flusso STANDARD.
La pagina che Jira mette a disposizione quando aggiorniamo una notifica. Le possibili scelte non sono cambiate
Come vediamo non abbiamo alcuna possibilità di scelta del team. Quindi non riusciamo in alcun modo (almeno per il momento) a reindirizzare le notifiche attraverso i canali standard.
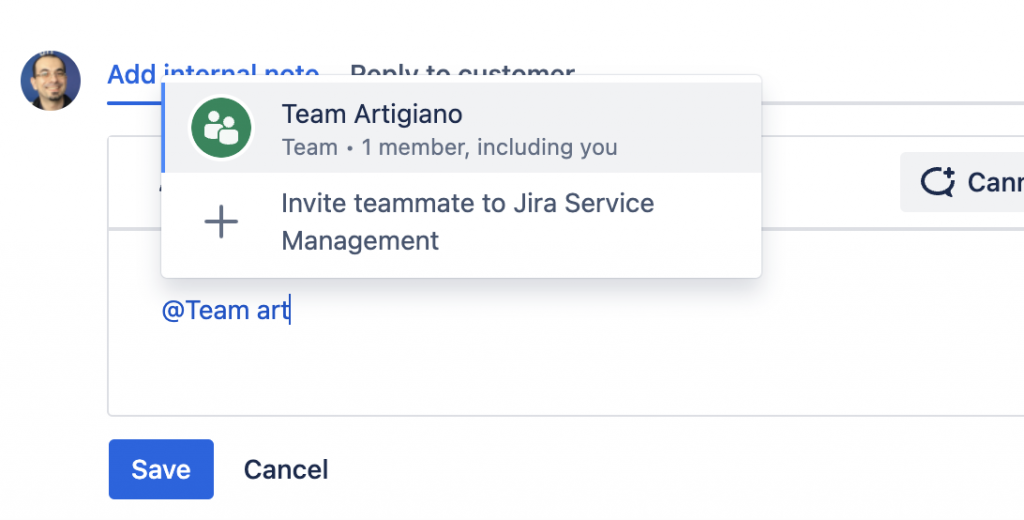
L’unico sistema rimane le mentions. Infatti se definiamo un Team
In questo caso mi sono creato il mio team ufficiale
il risultato che otteniamo è:
Cosa vediamo nelle mentions
Conclusioni
Abbiamo una funzionalità interessante, che introduce alcuni concetti che prima non erano presenti in Jira. Questo è sicuramente importante ma, secondo il mio modesto parare, occorre ancora aggiungere delle componenti e delle funzioni ai Team. Siamo agli inizi e sono sicuro che Atlassian non ci deluderà in questo.
In questo post andremo ad esaminare un addon che ci mette a disposizione una funzione interessante. Vediamo in dettaglio addon e funzione.
Esplorazione alchemica
Le presentazioni
L’addon che vogliamo descrivere
Questo addon ci permette di poter eseguire delle operazioni interessanti, ovvero:
Permette di definire un template di issue
Possiamo precompilare titolo e descrizione della issue
A questo punto abbiamo una cosa molto interessante
Fonte Marketplace
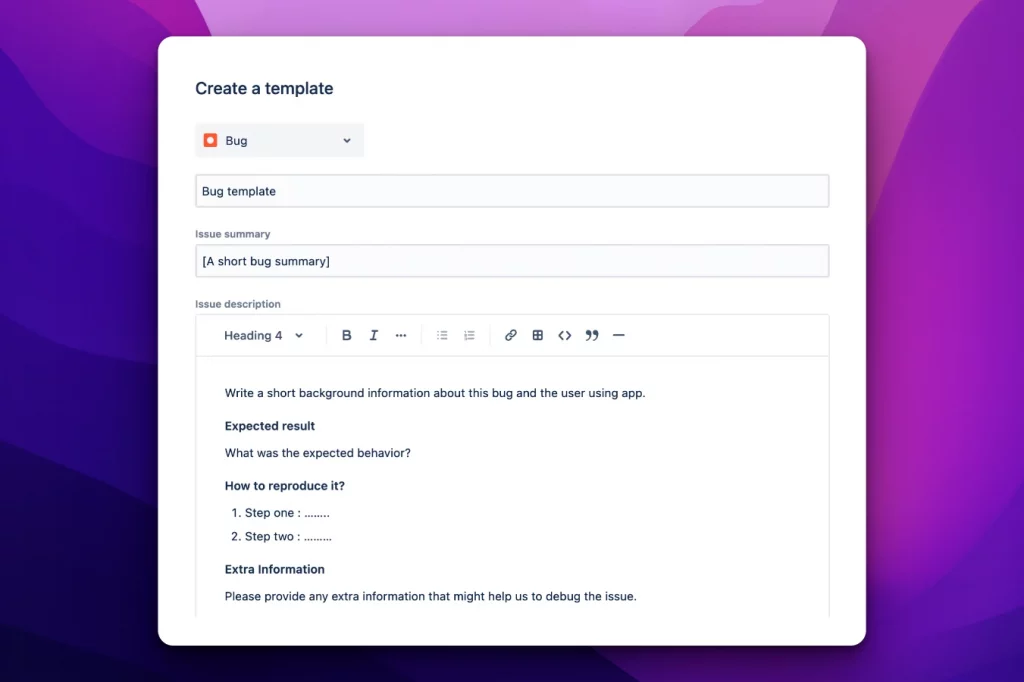
Dalla precedente immagine possiamo vedere come l’addon permette di definire un template. Ci avete fatto caso? abbiamo lo stesso sistema che abbiamo per creare una issue. Questo significa che non dobbiamo imparare nulla di particolare.
Fonte Marketplace
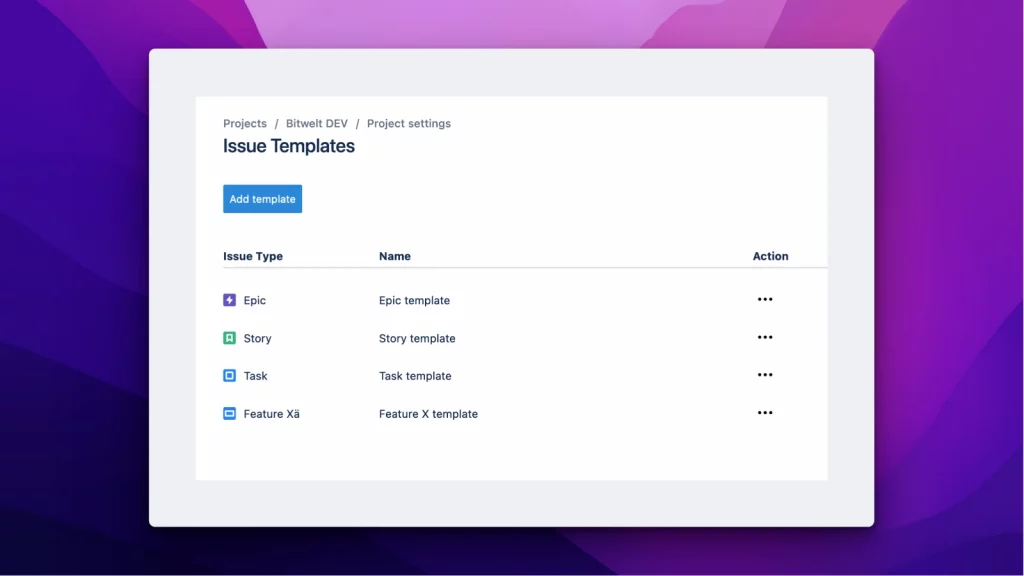
Possiamo definire, nell’ambito dello stesso progetto, una template per issue type. Lo vediamo dalla precedente immagine
Interessante, lo provo subito
Partiamo subito dalla prima operazione. Installiamo l’addon nella nostra istanza. Come sempre vediamo come procedere.
Configurazione Generale
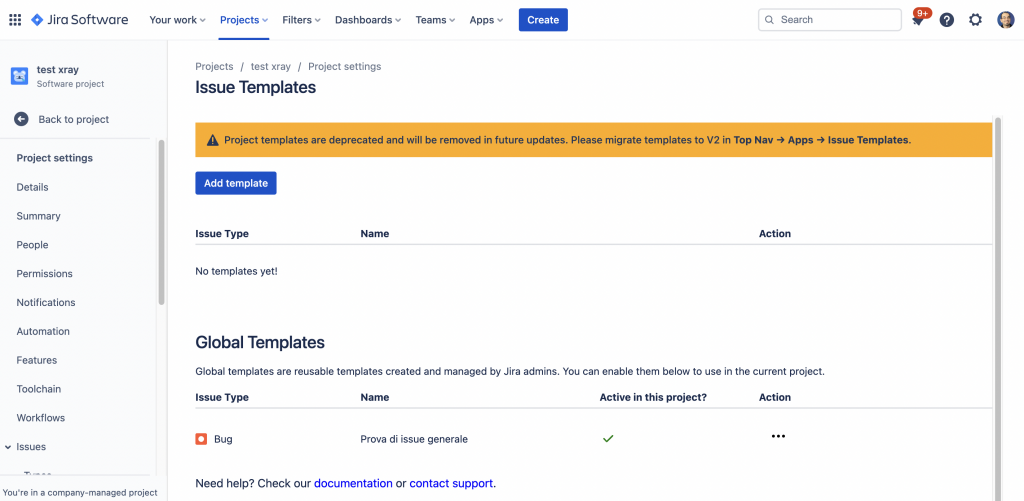
Proseguiamo con la configurazione generale che l’addon. Ci accediamo dal menù principale Apps.
Le funzioni che sono presenti nella sezione
Da li possiamo referenziare i vari template che abbiamo definito. Possiamo anche accedere dalla sezioen Apps presente nelle Project Settings. Faccio una annotazione. Potrebbe darsi, per chi ha installato l’addon quando ancora era gratuito, potreste trovare una immagine come la seguente
Quello che si può vedere nella installazione che ho usato per i miei test
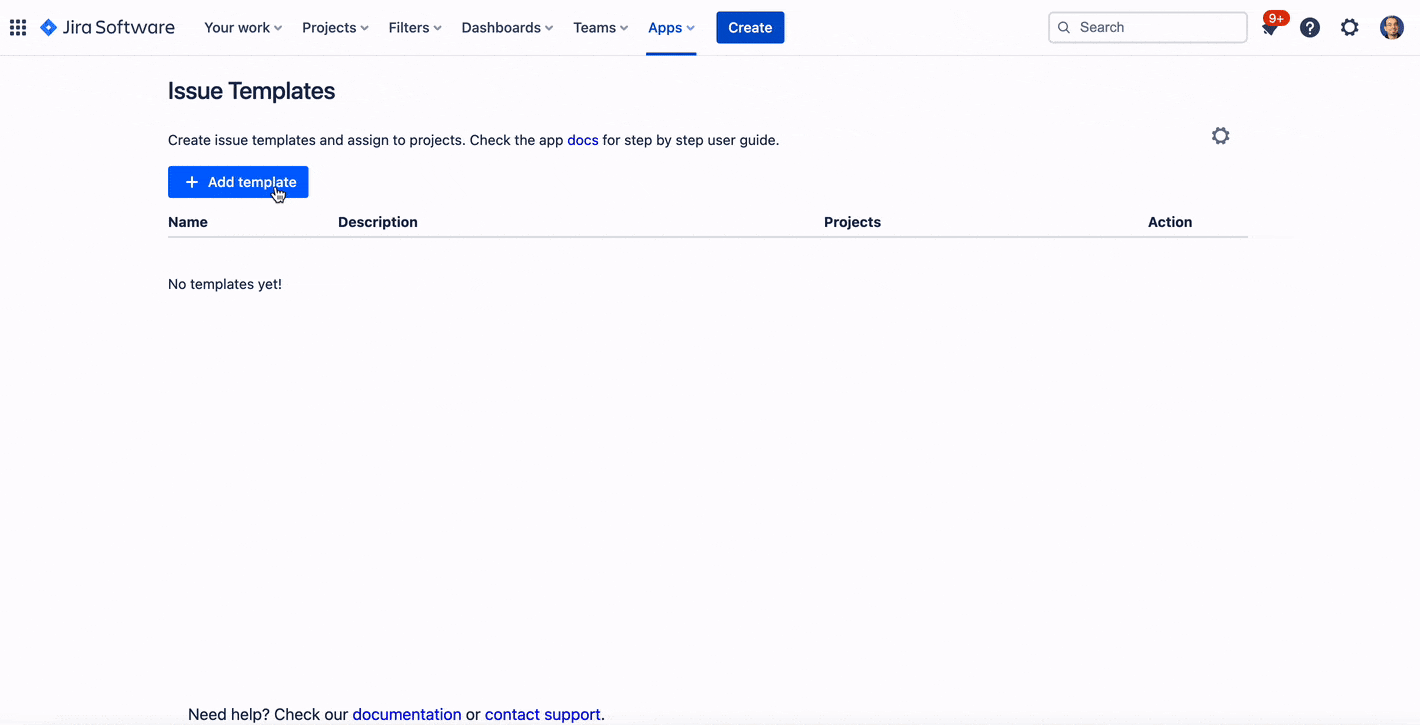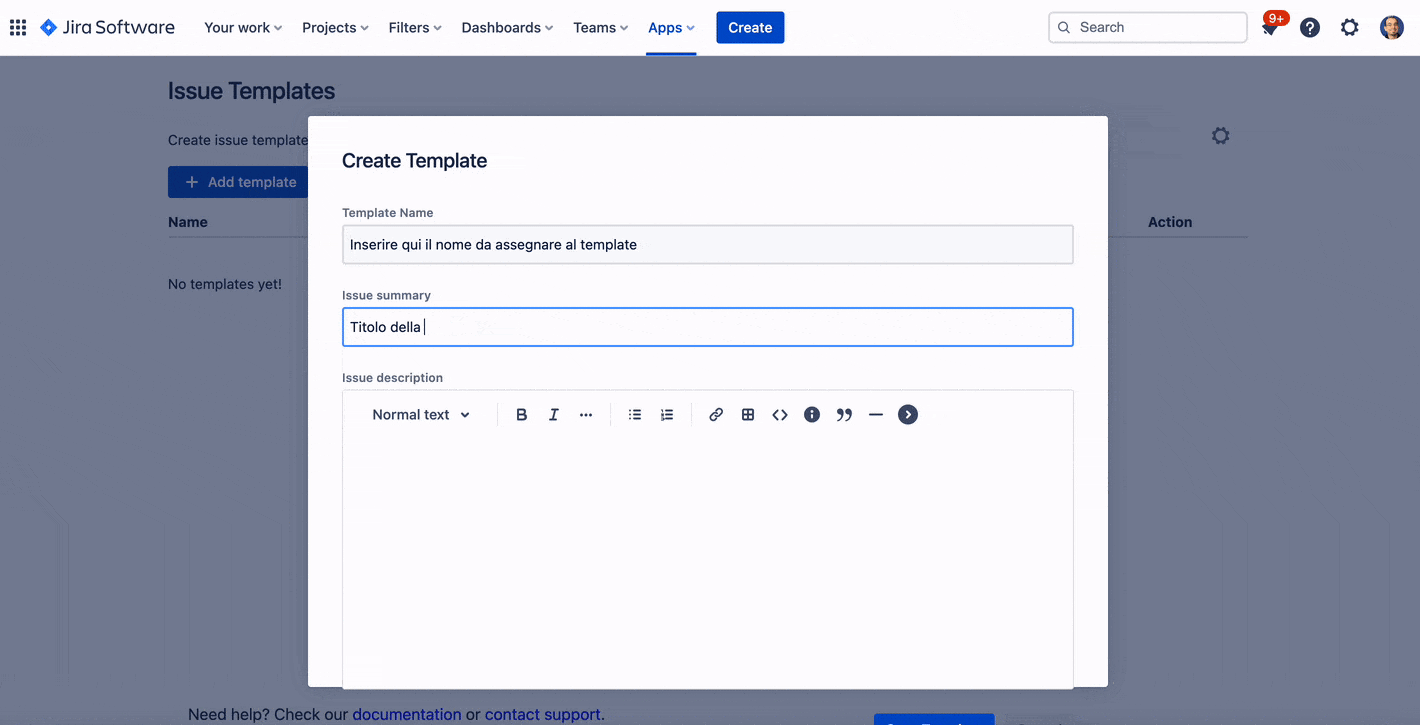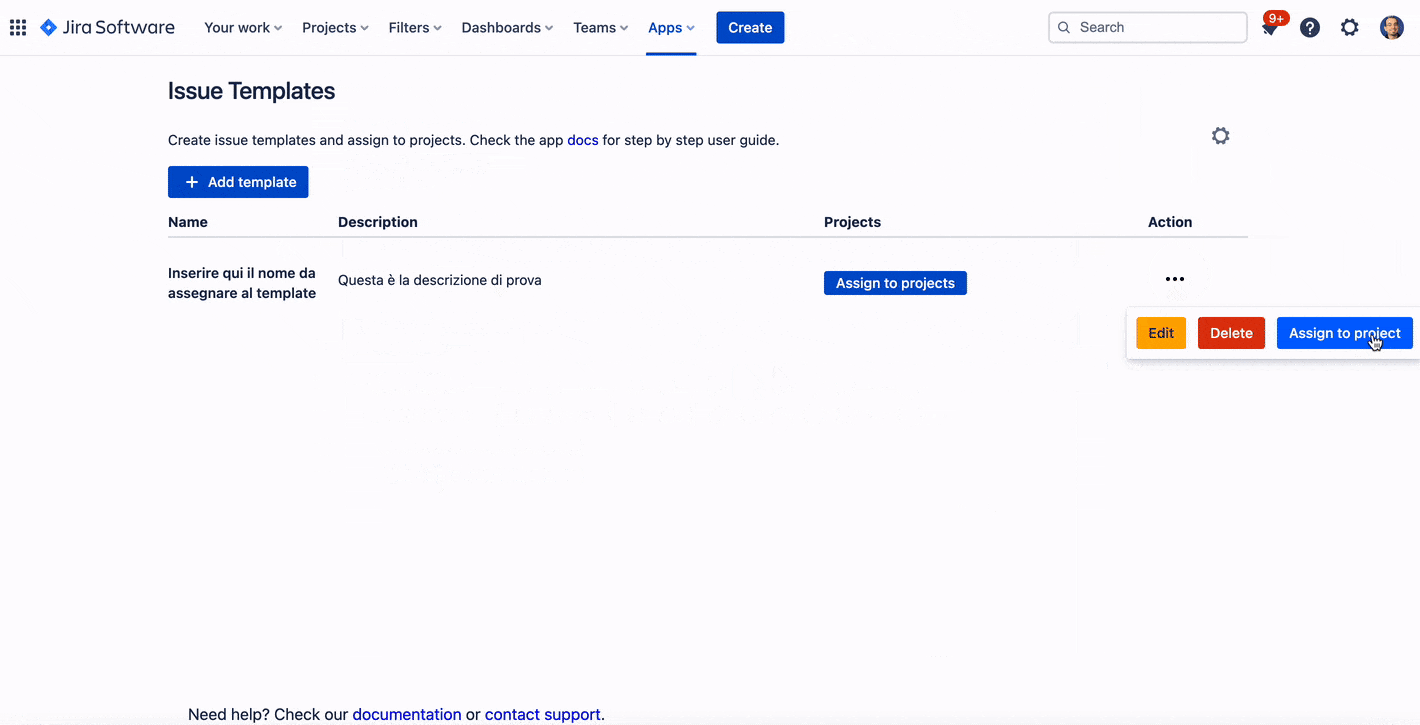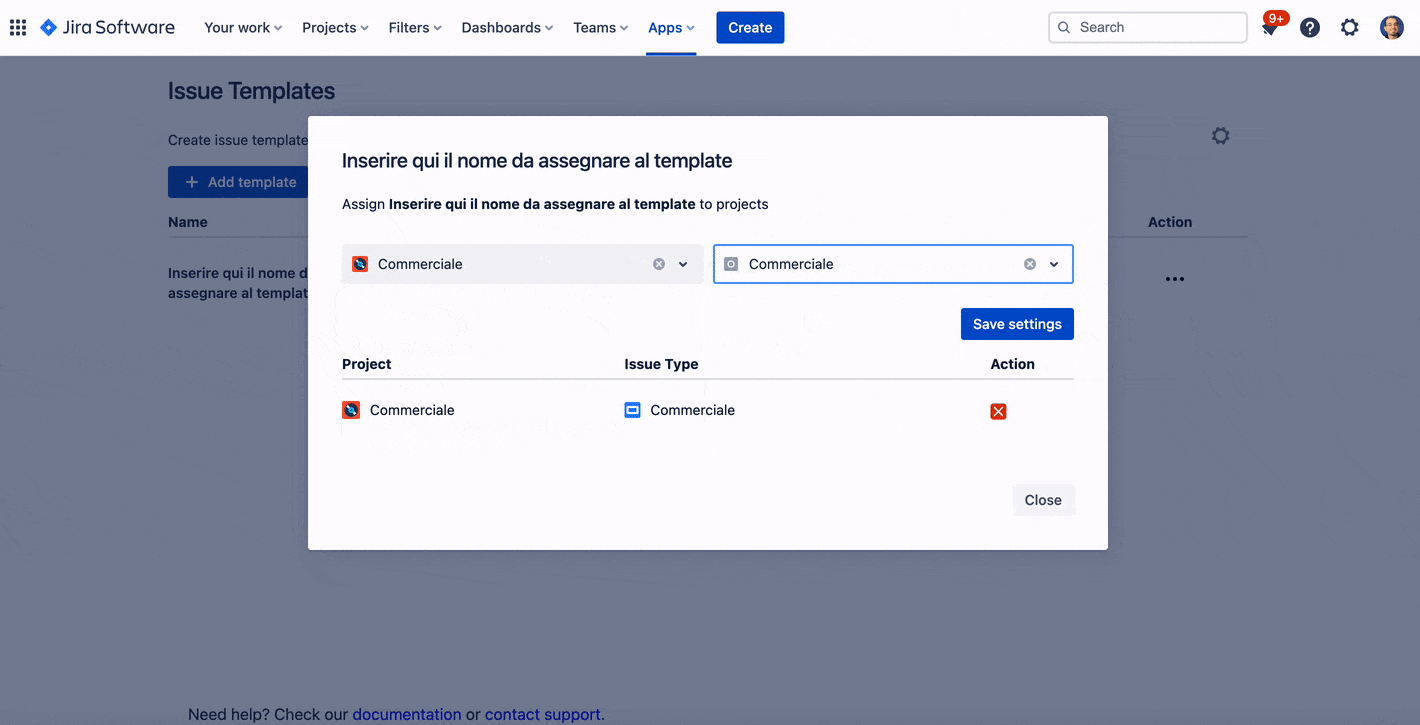
Da li andiamo a definrie il template che andremo ad usare. Vediamo come si configura un template
La GIF ci mostra come eseguire la configurazione da zero del template e l’assegnazione ad un progetto
Come possiamo osservare, la creazione di un template non richieste alcuna complessità: Sembra quasi che creiamo una nuova issue. L’assegnazione non è altro che una semplice opzione che andiamo a selezionare.
Proviamo quanto abbiamo configurato
Adesso proviamo il tutto e verifichiamo il risultato.
Un semplice esempio di utilizzo.
dalla Gif sopra riportata, vediamo che l’utilizzo è molto semplice e ci permette di poter generare le issue direttamente compilate come abbiamo definito.
Conclusioni
Abbiamo un addon che ci permette di poter generare delle issue pre-compilate come ci servono con pochissima configurazione. Questo addon non risulta molto difficile da usare e permette di poter risolvere alcuni casi di uso che mi sono stati richiesti nel corso della mia vita lavorativa. La prova è stata eseguita con la versione free dell’addon. Nel momento in cui scrivo è disponibile una versione a pagamento che sicuramente presenta delle ulteriori funzionalità.
Credo che sia sempre ottimo precisare e dare ulteriori indicazioni sulle Automation, che sono un mondo molto vasto ed interessante. Cerchiamo di fare una piccola precisazione che sicuramente sarà molto utile.
Procediamo senza indugio
Nel dettaglio
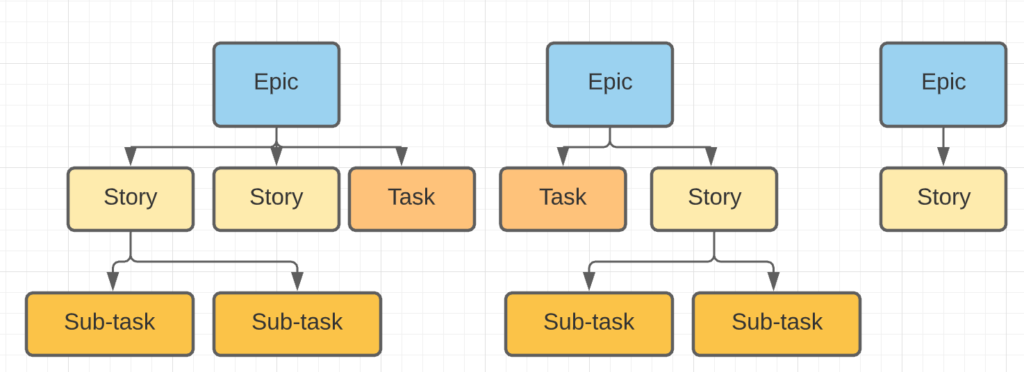
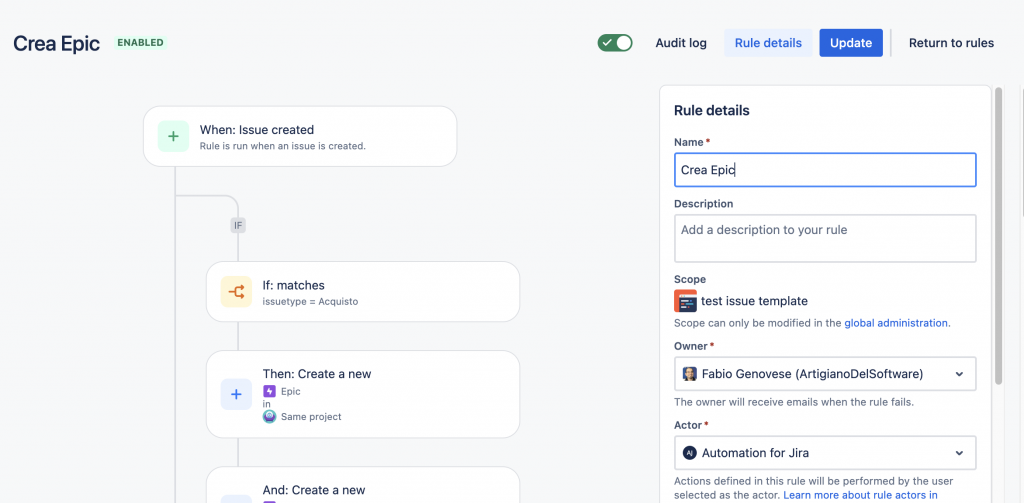
Quello che abbiamo a trattare riguarda il come generare un task affinché sia collegato ad una Epic. Come sappiamo la Epic è un caso eccezionale tra tutte le issue presenti su Jira. Si tratta dell’unica issue type che permette di poter avere delle Issue figlie. I motivi li abbiamo trattati in altri post precedenti ma credo che a breve li andremo a riprendere. 😉
Un esempio ben dettagliato di questa gerarchia
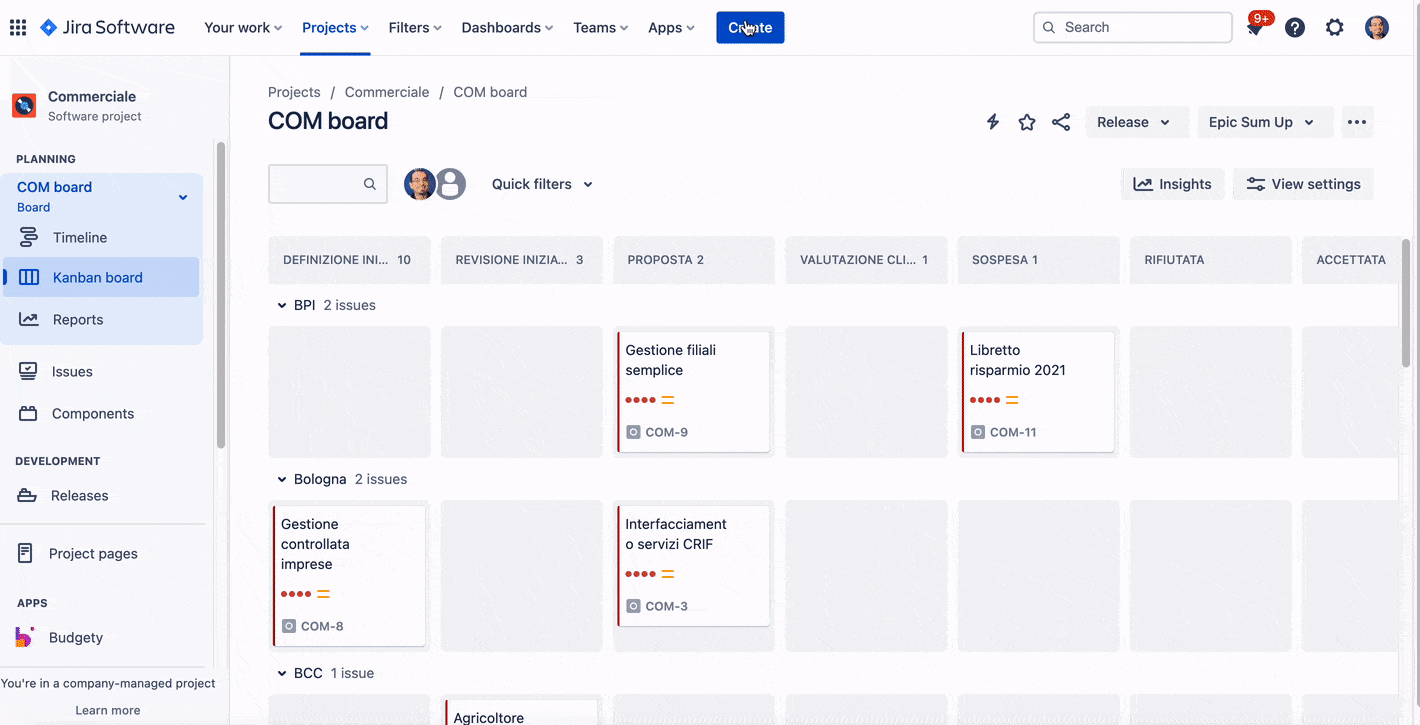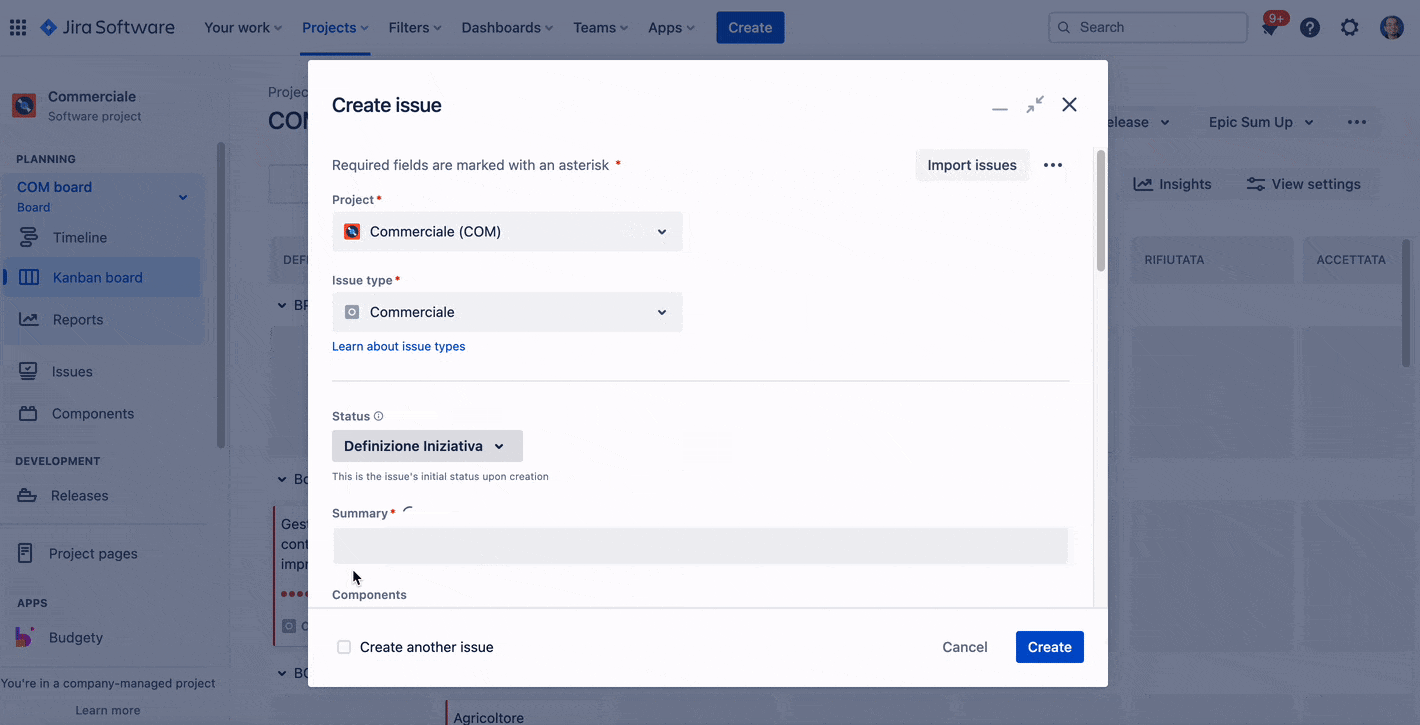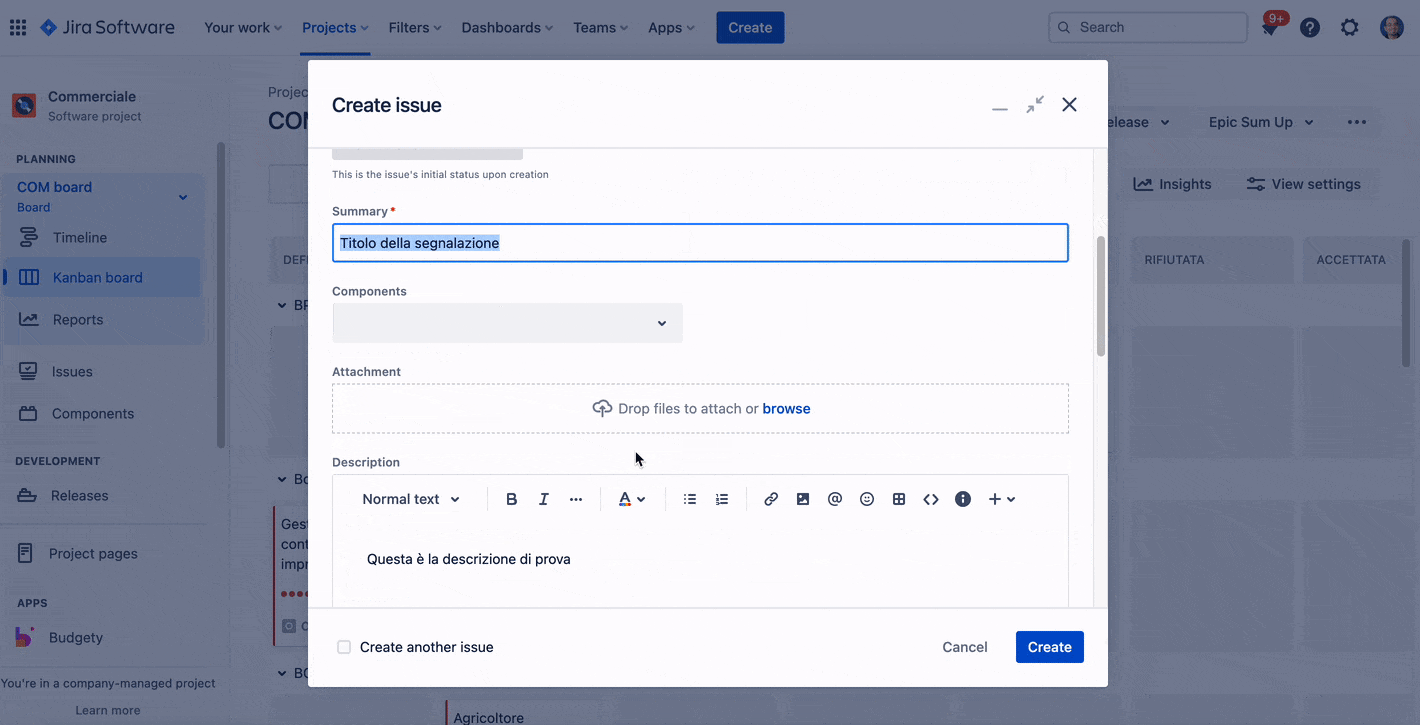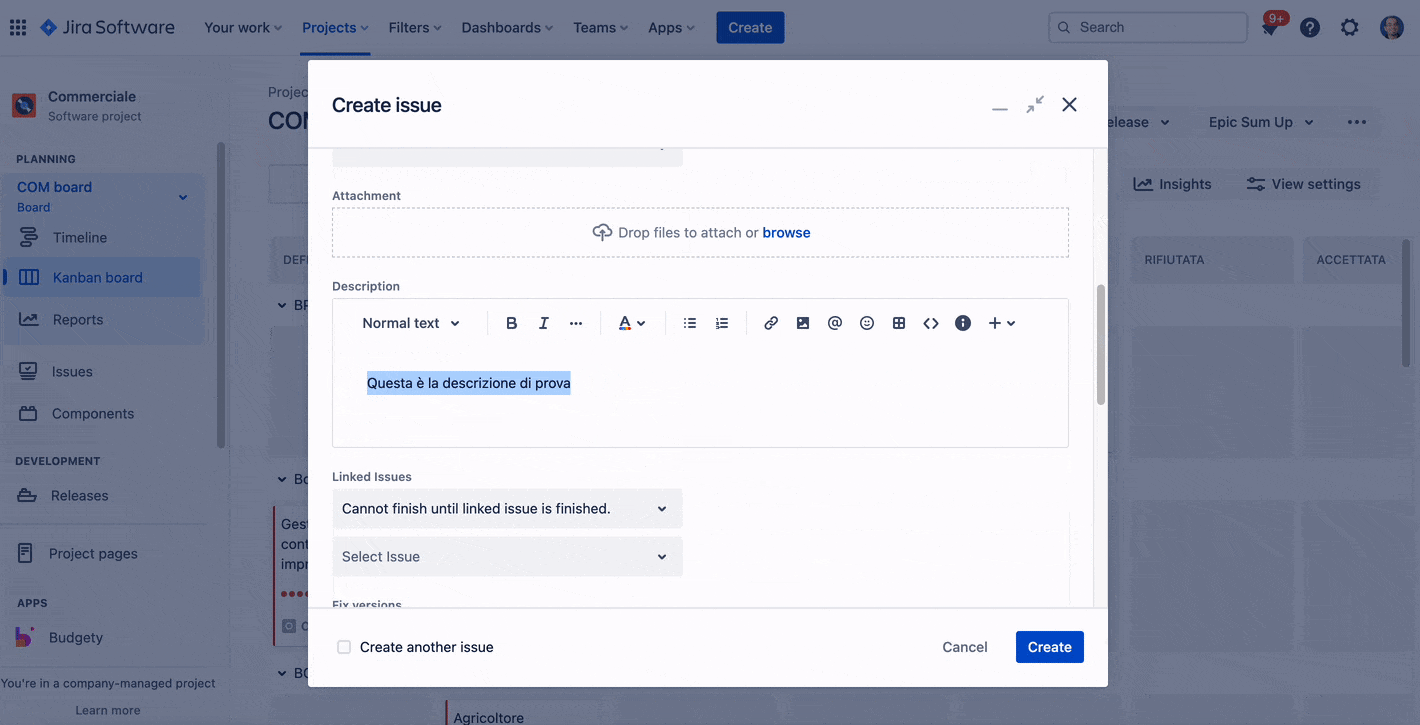
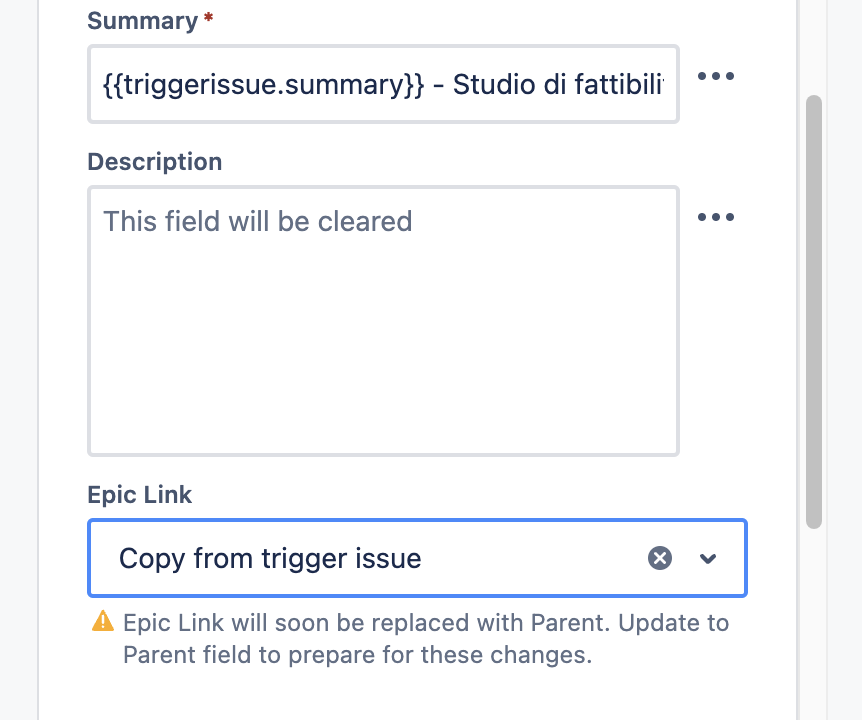
Se vogliamo introdurre questa informazione quando usiamo le regole di automation ci accorgiamo di una cosa: Usando l’azione di Edit Issue, quando selezioniamo il campo Epic Link, non riusciamo a passare il valore. Qualcosa non funziona.
Un dettaglio della azione
Il risultato non è quello sperato. Sembra quasi che l’azione non si esegua. Quindi?
Ragioniamo e verifichiamo
Nozioni di Storia di Jira
Dobbiamo sapere (da storico dilettante non posso esimermi) che originariamente non esisteva la gestione Agile su Jira. E’ stata aggiunta da un addon (greenhopper) che ha introdotto questo aspetto. Atlassian si è buttata a pesce ed ha acquisito l’addon. Adesso sembra tutto integrato, ma….. in realtà credo ci sia una separazione ancora netta. Credo che sotto sotto sia rimasto un addon separato e di conseguenza anche il campo sia gestito in maniera separata.
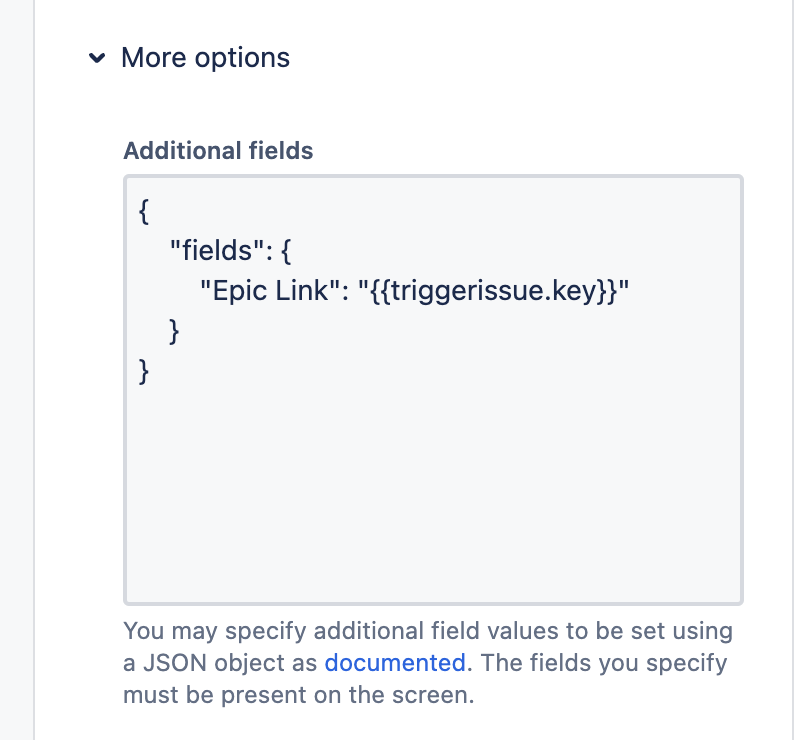
Ho scartabellato e verificato ed il risultato è questo articolo del Community: Il campo va gestito esattamente come un qualsiasi campo custom. Passiamo al Json:
Uno schema del JSON da usare
Se usiamo questa indicazione, riusciamo ad arrivare all’obiettivo.
Conclusione
Un ringraziamento a tutti coloro che hanno partecipato a questa discussione che ha permesso la redazione di questo articolo in Italica Lingua.
Grazie.
Un ultimo appunto:
Mentre componevo questo articolo, ho notato una cosa molto carina. Atlassian sta rivedendo l’interfaccia grafica della sezione delle regole di Automation. Infatti:
URCAAAAAA
promette bene. Vedremo nei prossimi mesi che cosa succederà.
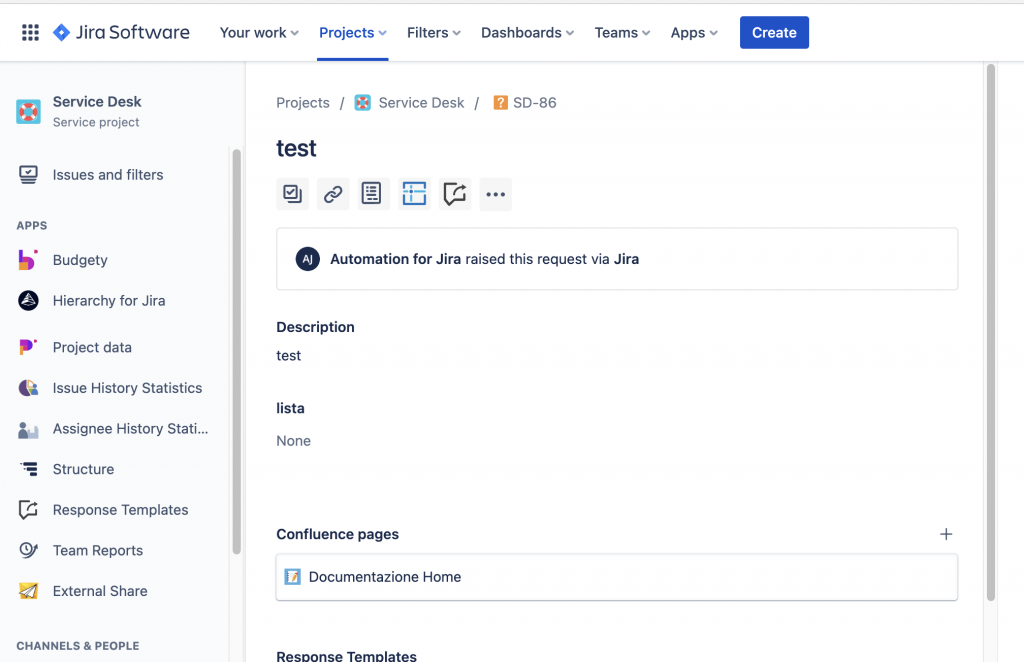
Creiamo un link ad una pagina di Confluence su Jira
In questo post affrontiamo un argomento interessante, inerente le Regole di Automazione. Già recentemente abbiamo parlato, in questo post, di come la gestione dei limiti di queste regole cambiano dal prossimo primo novembre. Vediamo in questo caso come sopperire ad una necessità, ovvero come possiamo aggiungere un link ad una Pagina di Confluence ad una issue, direttamente da Regola di automazione.
Come moderni Bandeirantes, andiamo in esplorazione
Andiamo con ordine
Vogliamo associare ad una issue, quella che ha causato l’esecuzione della nostra regola, una pagina di Confluence ben precisa. Una cosa che notiamo subito è che non abbiamo a disposizione una azione specifica attraverso le Automazioni. DI conseguenza siamo leggermente frustrati. La domanda sorge spontanea. Come possiamo fare??
Stiamo calmi
Abbiamo una soluzione
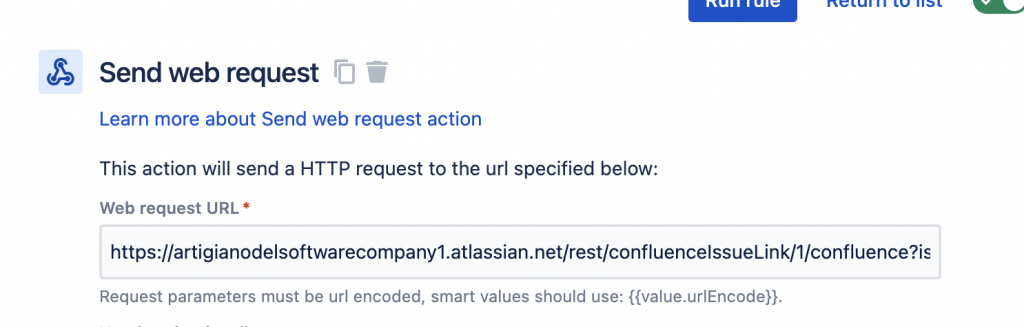
Ebbene si. Possiamo sfruttare una delle azioni che meglio si adegua per poter agganciare una pagina ad una issue. In particolare possiamo sfruttare questa azione:
Send Web Request è quello che ci serve
Da questa azione possiamo fare ua cosa molto semplice: Chiamare una API di Atlassian e agganciare la pagina alla issue. ma vediamo quale è la API che andiamo a richiamare.
Quello che occorre fare è impostare i parametri che ci servono e successivamente applicarli tramite la regola.
Il risultato è il seguente:
Un esempio che ho impostato su di un mio ambiente di prova
Conclusione
Questo è molto interessante. Possiamo agganciare una pagina Confluence alla nostre issue in maniera veramente semplice. Ci sono degli accorgimenti da tenere presente quando si utilizzano delle API, ma ne parleremo in maniera più approfondita in separata sede. Si tratta di una sorpresa. Rimaniamo in contatto.
Reference
Un ringraziamento a tutti i partecipanti a questa discussione della Atlassian Community, dove è stato chiarito questo punto e che ha permesso di poter scrivere questo articolo in Italica Lingua.
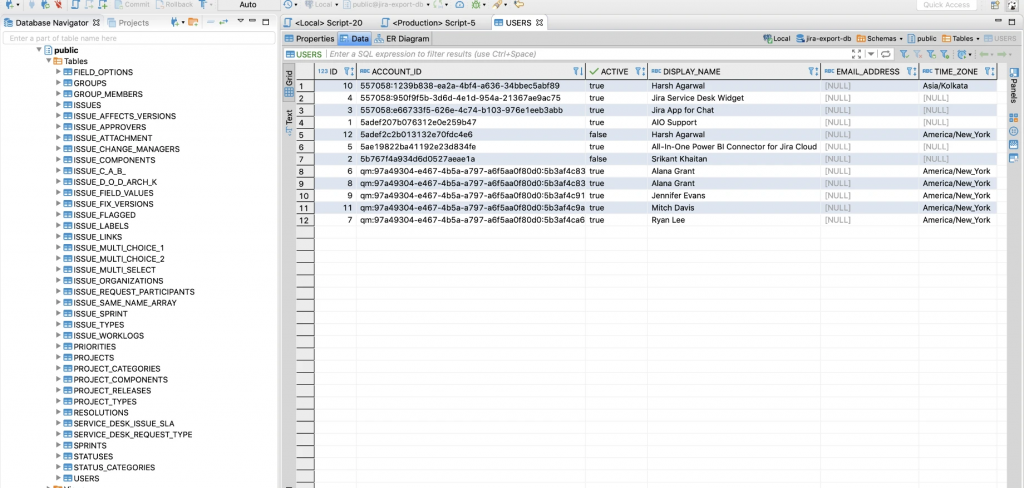
Database exporter – Come ti estraggo i dati dal Cloud
In questo post andremo ad esaminare un addon che ci permette di poter estrarre i dati dal Cloud in modo da permetterci di poter eseguire delle interrogazioni mirate.
Esplorazione alchemica in corso
Una premessa importante
Chi lavora con il Cloud sa perfettamente che quando vogliamo eseguire delle interrogazioni sui dati, la risposta è sempre una. Il seguente memo ce lo spiega
Vediamo di chiarire il punto
Sul Cloud non abbiamo alcuna possibilità: Ci è precluso l’accesso al database interno. Di conseguenza non possiamo fare nulla per lanciare query… almeno fino ad ora.
Abbiamo una soluzione
Inventato da Bob Swift ma adesso sotto il controllo della Appfire, abbiamo un addon che ci aiuta in tal senso, fornendoci la possibilità di costruire un simil-database su cui poter eseguire le nostre interrogazioni.
L’addon di cui parleremo oggi.
Questo addon è nato con l’obiettivo di ricostruire un database simile, rispetto a quello che avevamo a disposizione con la versione onPremise, e permettere agli utenti cloud di riuscire a ricostruire delle query ed interrogazioni.
Fonte Marketplace
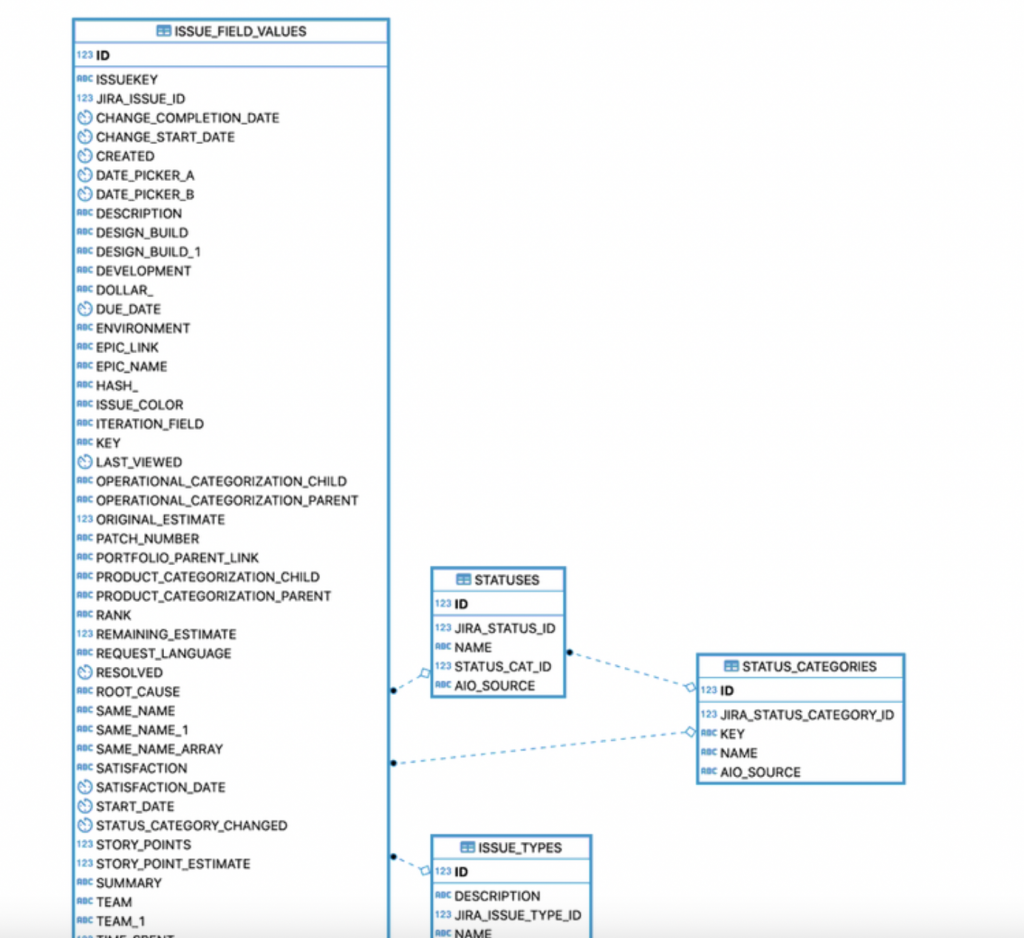
Come possiamo vedere dalla precedente immagine, riusciamo a ricostruire sia i dati della parte standard, compresi i campi custom. Dalla documentazione dell’addon abbiamo a disposizione anche uno schema dati che ci spiega come ricostruire le relazioni tra le varie tabelle:
Fonte: Documentazione dell’addon
Possiamo, attraverso questo addon, ricostruire un simil-database (non è proprio il database effettivo: Teniamolo sempre a mente).
L’addon al momento permette di poter estrarre i dati direttamente su di un database Postgresql. Questo ci limita un pò i movimenti, ma non più di tanto. Se in azienda abbiamo uno standard che ci impone l’utilizzo di altre tipologie di Database (ad esempio: In azienda si usano database MS SQL Server). Tuttavia, usando dei server Linux, il problema viene risolto.
Punti di attenzione
Dobbiamo però tenere sempre a mente alcuni punti di attenzione. Ricordiamoci sempre che il nostro Cloud Atlassian è prevalentemente una macchina virtuale localizzata su Internet e di conseguenza abbiamo:
Il nostro cloud deve poter accedere al database e di conseguenza questo deve essere raggiungibile da internet
Essendo raggiungibile da internet, occorre che questo database sia gestito in maniera opportuna.
Non possiamo esporre direttamente i nostri database verso internet
Il database da usare deve essere un database che viene immediatamente blindato o svuotato non appena viene compilato
Come si può vedere non si tratta di semplici raccomandazioni, ma di punti di attenzione molto importanti. Se non li rispettiamo abbiamo dei problemi abbastanza seri.
Se perdiamo i dati questa sarà la nostra espressione.
Di conseguenza abbiamo molto da considerare.
La mia esperienza
Ho avuto modo di collaudare questo addon direttamente presso un mio cliente e posso dire che l’addon lavora in maniera egregia. Nel senso che i dati estratti sono effettivamente il clone dei dati. Ma vorrei fare alcune ulteriori considerazioni.
Abbiamo principalmente i dati dello standard
Non ci facciamo illusioni. Non riusciamo a disporre di tutti i dati come nel caso delle nostre installazioni onPremise. Infatti quando possibile, si accedeva anche ai dati degli addon semplicemente andando a leggere le tabelle con prefisso AO%, come riportato in questa documentazione ufficiale Atlassian.
In questo caso l’addon ricostruisce, con buona approssimazione, le informazioni standard e attraverso opportune query, riusciamo a leggere le informazioni che ci servono.
Solo alcuni addon sono disponibili
L’addon riesce a leggere i dati di alcuni addon, come TEMPO TIMESHEET, ma una cosa che ho notato è che le informazioni che sono scaricate sono sotto forma di un JSON che deve essere ‘lavorate’ per poter estrarre i dati che servono.
Possibile eseguire backup totali ed incrementali
E’ possibile eseguire entrambe le modalità. Nel mio caso, potrebbe essere utile eseguire un primo backup generale e poi tutti i backup incrementali. Questo aiuterebbe notevolmente
Conclusioni
Abbiamo un addon interessante ma che deve essere usato con tutti i crismi del caso. Possiamo estrarre i dati che ci interessano e fare le statistiche personalizzate del caso, anche se in ultima istanza suggerisco di appoggiarsi ad appositi tools che permettono di poter portare le informazioni di Jira su PowerBI o QLIK e consentono di gestire le statistiche molto meglio che con un semplice database da rimettere in piedi.
Come sempre riporto le mie indicazioni perché, questo sicuramente lo avrete compreso leggendo i miei post, che è sempre meglio avere più possibilità che solo una possibilità. La libertà di scelta è una arma molto potente che intendo sempre sfruttare e mettere a disposizione, anche quando eseguo le mie consulenze.
In questo post andremo ad analizzare come possiamo rendere le pagine di Confluence più belle e cercheremo di costruire alcuni esempi per mostrare come possiamo gestire al meglio queste soluzioni.
L’idea è di comporre la nostra soluzione per realizzare un SuperConfluence
Confluence, non ha bisogno di presentazioni
Conosciamo tutti il valore di Confluence, anche se non sempre riusciamo a valorizzarlo al meglio. Quasi sempre lo utilizziamo come un contenitore delle nostre informazioni, ma spesso e volentieri ci offre tantissimo di più.
Ho speso molte parole in vari articoli in cui ho indicato le potenzialità di Confluence come ECM (Enterprise Content Management), dove ho indicato le possibilità che Confluence offre per poter gestire al meglio i contenuti.
Un esempio di come possiamo organizzare i contenuti su di una pagina di Confluence (Fonte: Atlassian)
Adesso ci proponiamo l’obiettivo di portarci un gradino più avanti, cercando di capire come possiamo aggiungere elementi di grafica e come poterli sfruttare al meglio
Cosa abbiamo a disposizione?
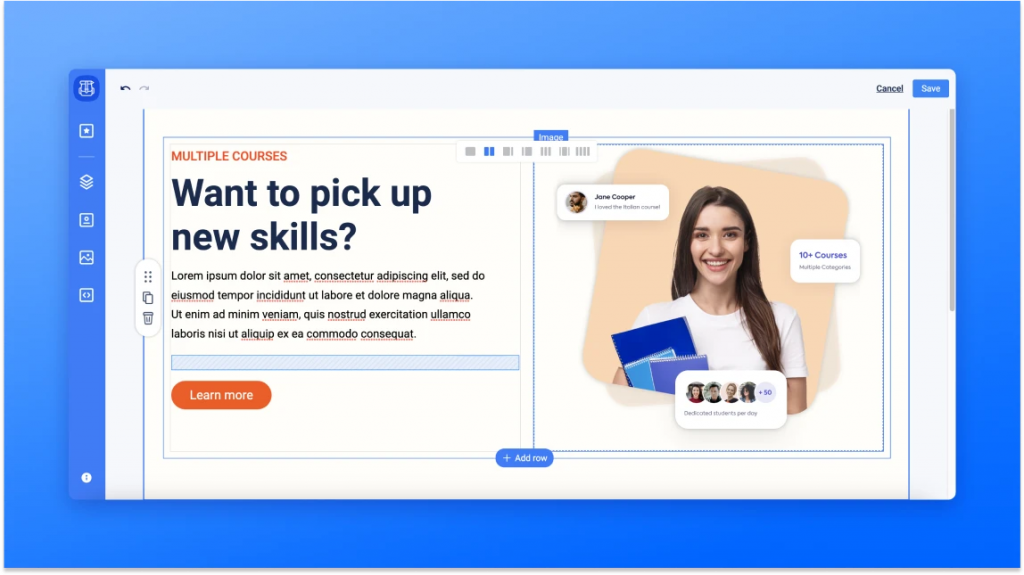
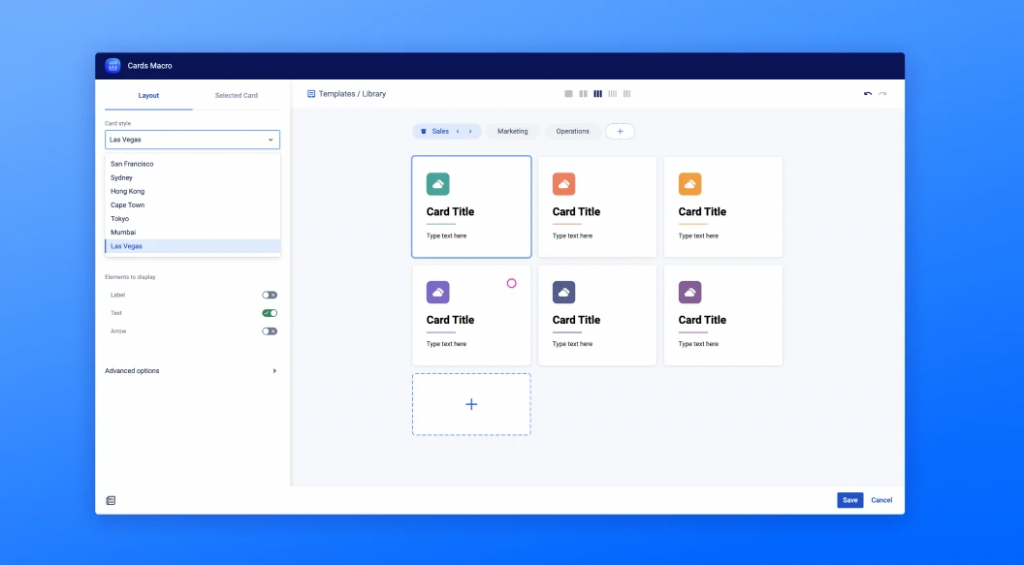
Abbiamo esplorato e collaudato un addon che ci permette di aggiungere elementi grafici e componenti che ci permettono di renderlo molto carino e interessante. Sto parlando di Macrosuite della Caelor.
Fonte: Atlassian Marketplace
Questo addon ci permette di inserire degli elementi grafici alle nostre pagine e non solo:
Fonte: Atlassian Marketplace
Osserviamo che possiamo inserire degli elementi che ci permettono di trasformare le nostre pagine e renderle molto più belle ed interessanti. Questo ci permette di scatenare la nostra fantasia
Fonte: Atlassian Marketplace
Abbiamo a disposizione delle procedure che ci aiutano nella modifica ed impostazione delle pagine, anche se non siamo dei grafici. Questo ci aiuta notevolmente nella gestione di queste pagine, semplificandoci il lavoro.
Fonte: Atlassian Marketplace
Interessante, ma è l’unico?
No. Non è l’unico e nei prossimi post andremo anche ad esaminare altri addon che offrono funzioni simili. Il nostro obiettivo non è quello di proporre LA soluzione unica (non serve a niente). Non esiste. Mettiamolo bene in conto. Ci serve sempre capire la soluzione che meglio si adegua alla situazione che stiamo esaminando. Solo così riusciamo a risolvere le necessità dei clienti.
Conclusioni
Abbiamo un addon molto interessante che ci aiuterebbe nella gestione delle pagine. Ho in mente un test molto interessante per saggiarne le potenzialità. Nel prossimo articolo proverò vedere come si comporta.
Reference
Maggiori informazioni sono reperibili nella pagina del Marketplace.
Manteniamo sincronizzati i nostri Space di Confluence
In questo post andremo ad esaminare come possiamo gestire una sincronizzazione di Space, sia nella stessa istanza, che su istanze differenti. Andiamo in modalità esplorativa
Vestiamo i panni del moderno alchimista
Introduzione dello scenario
Lo scenario che mi piacerebbe implementare serve nel caso di problemi che si possono presentare nella istanza di produzione. Se abbiamo a disposizione una istanza, minore con un numero inferiore di utenti, possiamo avere un backup sempre pronto all’uso che ci permette di poter ripristinare in tempi brevi l’operatività, permettendoci poi di ripristinare tutti gli aggiornamenti nel caso di riattivazione dell’ambiente di produzione.
Questo articolo rientra in un insieme di studi che sono nati dopo che ho pubblicato questo articolo, visto che sono stato uno dei fortunati a ricevere questa situazione. Per questo motivo voglio avere delle alternative da poter ottenere un esempio di Disaster Recovery anche per le nostre istanze Atlassian Cloud.
Vediamo in questo articolo come riuscire a creare un ambiente di Disaster Recovery
Come possiamo eseguire questa operazione?
Analizzando il Marketplace, operazione che eseguiamo quotidianamente, identifichiamo il seguente addon che ci permette di eseguire la sincronizzazione di due space relativi a due istanze Cloud differenti.
In questo caso abbiamo un addon che ci può aiutare.
Andiamo ad esaminarlo.
Che cosa offre l’addon
L’addon permette di eseguire una sincronizzazione da uno Space all’altro, nell’ambito di una stessa istanza, ma anche su istanze differenti. Questa funzionalità ci permette di poter creare degli scenari non indifferenti, permettendo di creare degli ambienti di Disaster Recovery, ma non solo. possiamo anche sfruttare questa funzionalità anche in scenari in cui dobbiamo gestire l’approvazione dei contenuti. Le idee scorrono potenti 🙂
Questa volta ci vuole 😛
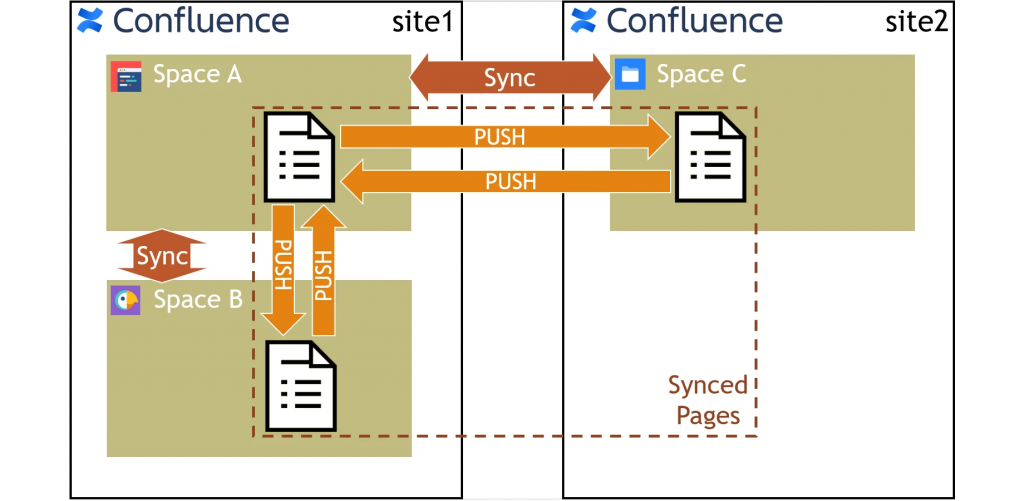
Il seguente schema riassume il funzionamento e ci permette di capire come ragiona l’addon
Fonte: Marketplace Atlassian
Osserviamo che la sincronizzazione, una volta impostata, è bidirezionale, di conseguenza qualsiasi operazione eseguita in uno degli Space viene immediatamente riverberata sugli altri. Non solo. Oltre alla sincronizzazione completa dello Space, abbiamo anche la sincronizzazione della singola pagina, come vediamo dalla seguente figura:
Fonte: Marketplace Atlassian
dove vediamo tutti i collegamenti impostati e abbiamo la possibilità di poter sincronizzare anche le singole pagine. La stessa interfaccia ci permette di capire se abbiamo eseguito l’aggiornamento della pagina o meno.
Fonte: Marketplace Atlassian
La configurazione non risulta impossibile, sempre guardando le schermate che sono presenti sul Marketplace. Viene fatto uso di Token per rendere sicura la sincronizzazione.
Convinto subito: Lo provo.
Iniziamo quindi a Installare l’addon. Come sempre ci serviamo di una GIF animata per vedere come eseguire l’installazione dell’addon.
Nota Bene – Lo installo ovviamente su due istanze per poi anche provare la sincronizzazione tra due istanze cloud differenti.
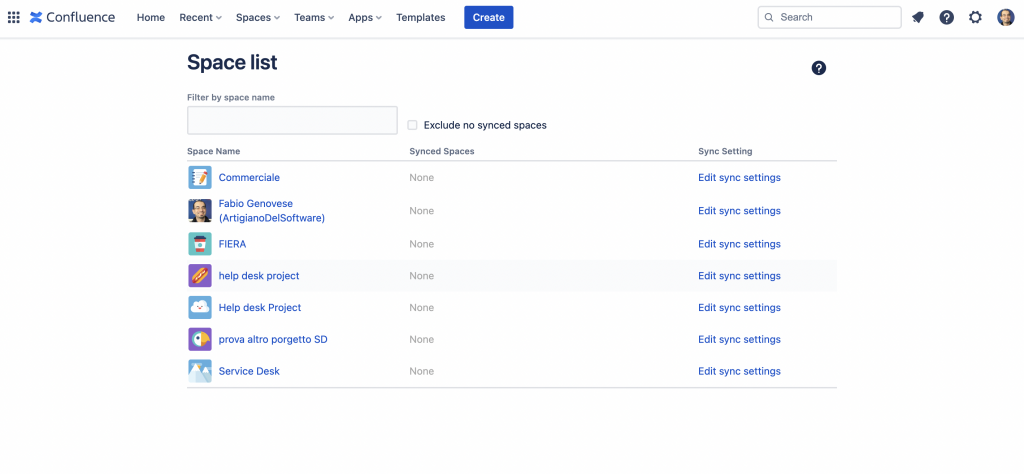
Andiamo ad analizzare subito la configurazione generale, cui accediamo dal menù Apps
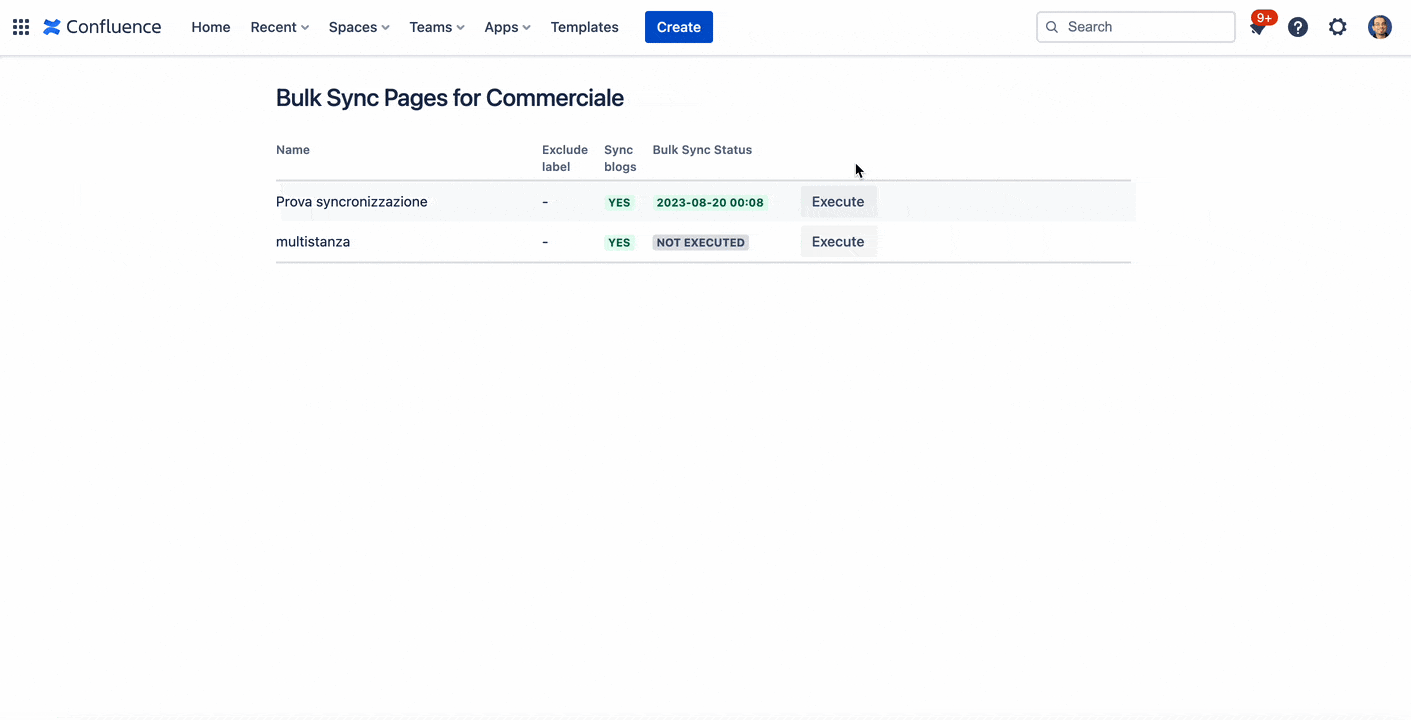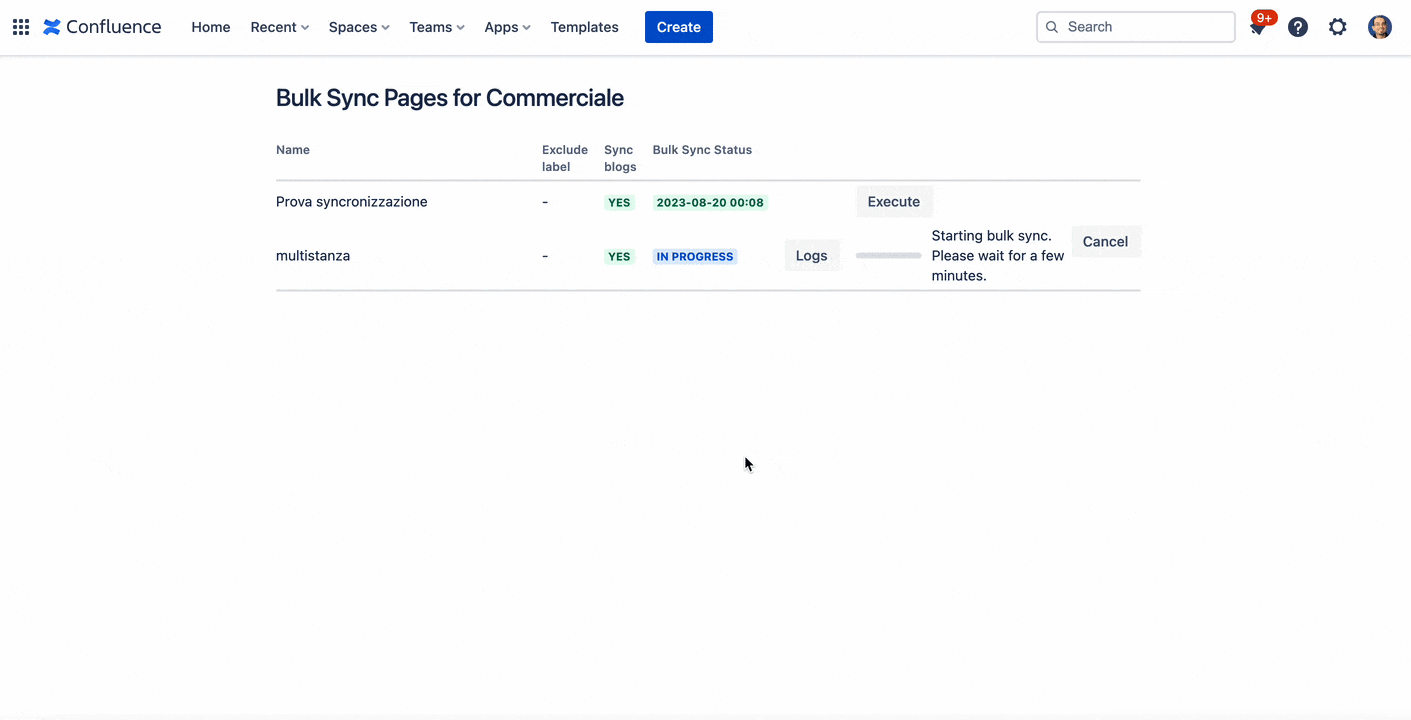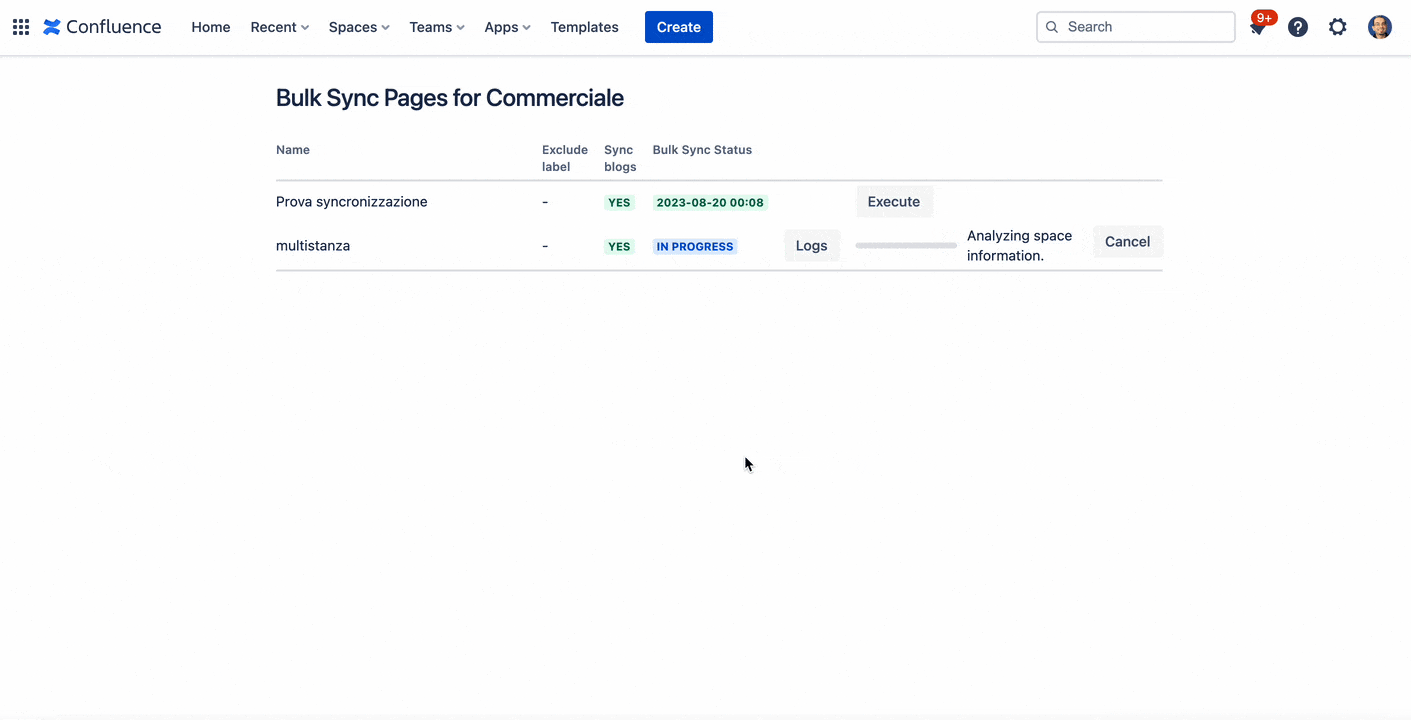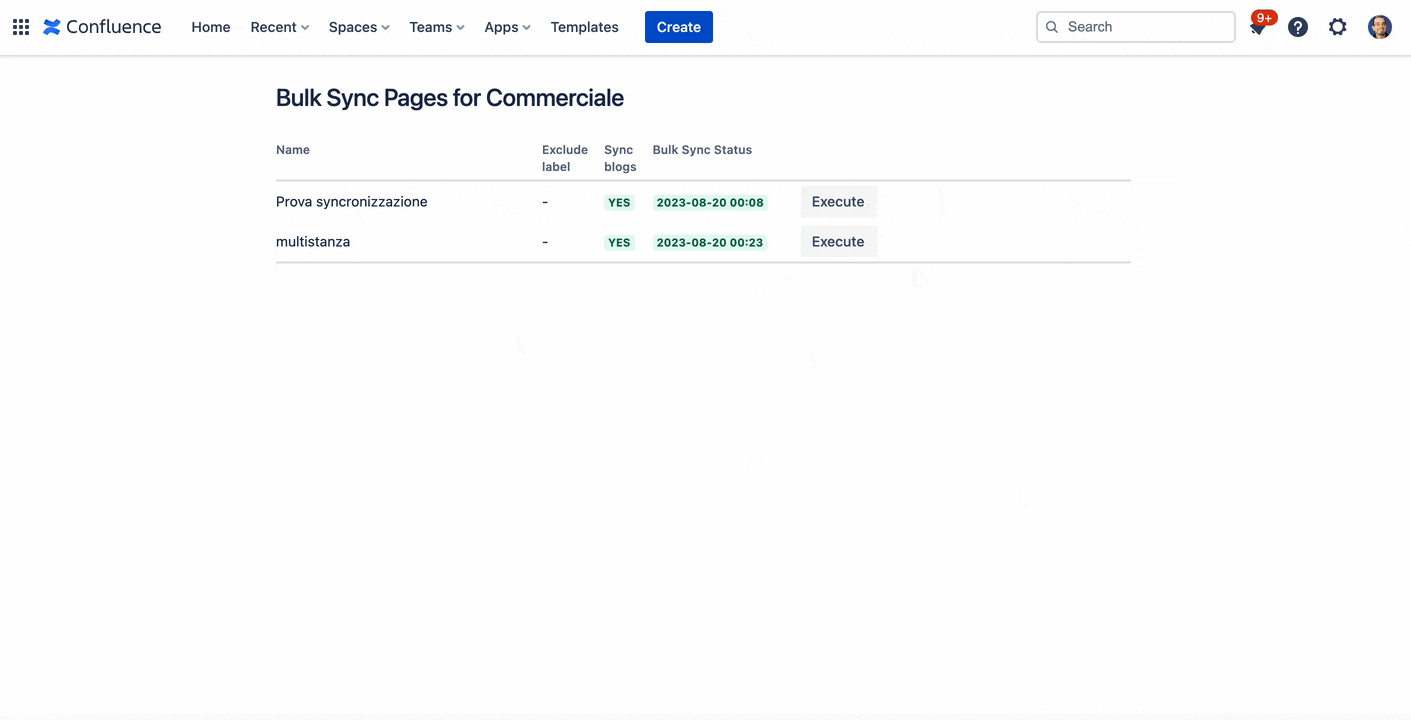
Che ci mostra l’elenco degli space disponibili e ci fornisce il link diretto alla configurazione, che ci permette di poter accedere alla configurazione diretta dell’addon che è presente nelle configurazioni dei singoli Space
Se selezioniamo Edit sync settings veniamo reindirizzati alla pagina di configurazione vera e propria.
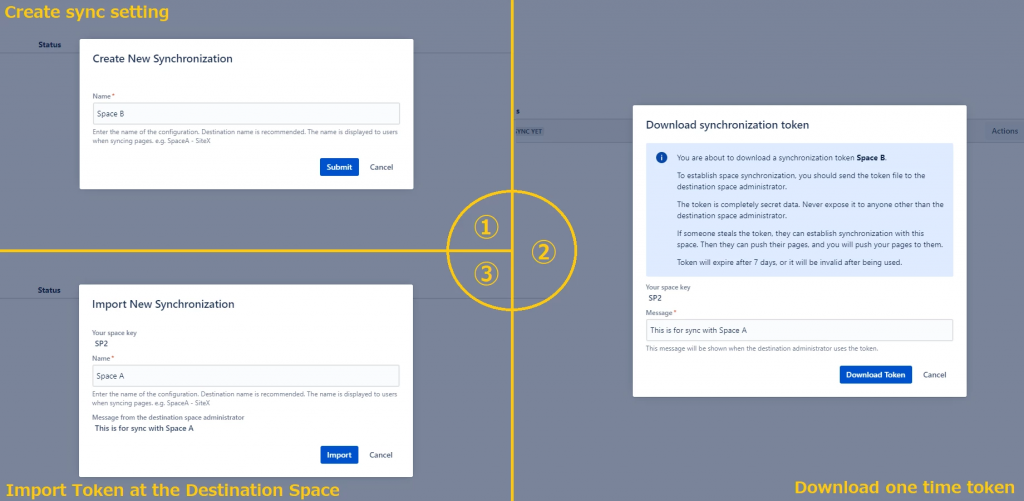
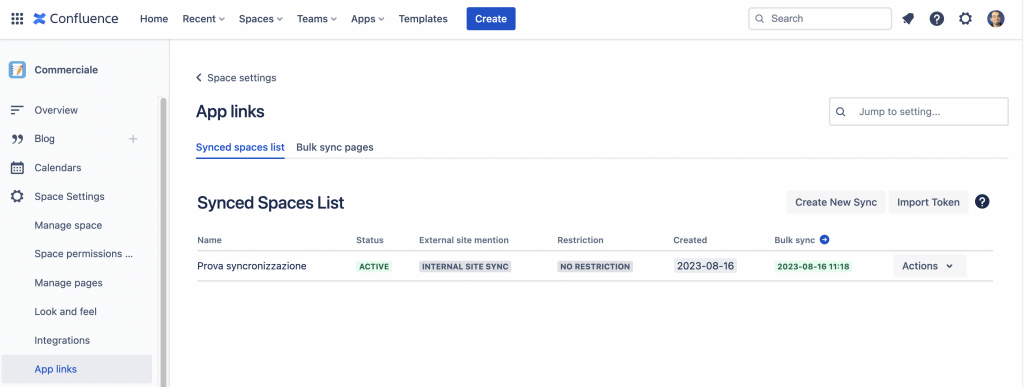
La configurazione di una sincronizzazione non richiede tantissimo. Semplicemente definiamo una sincronizzazione in quello che è lo Space sorgente. Da questo andiamo a scaricare il Token (è un file JMT), che andremo a caricare nella configurazione dello Space Destinazione.
A questo punto ho creato prima una sincronizzazione tra due Space di una stessa istanza e successivamente una sincronizzazione tra due istanze. A tale scopo ho due istanze Cloud dedicate allo scopo che ho preparato per un test che è diventato questo Case Study. Mi sono quindi limitato a configurare e a verificare
Ho scelto questi Space perché presentavano delle informazioni differenti ed ho verificato come si comportavano.
Un esempio di esecuzione negli ambienti di test Cloud
Come possiamo vedere dalla GIF animata, l’esecuzione è molto semplice e non abbiamo molti output. Lo stesso LOG non ha dato alcun risultato e non abbiamo nulla da vedere dopo. Questo è un punto importante.
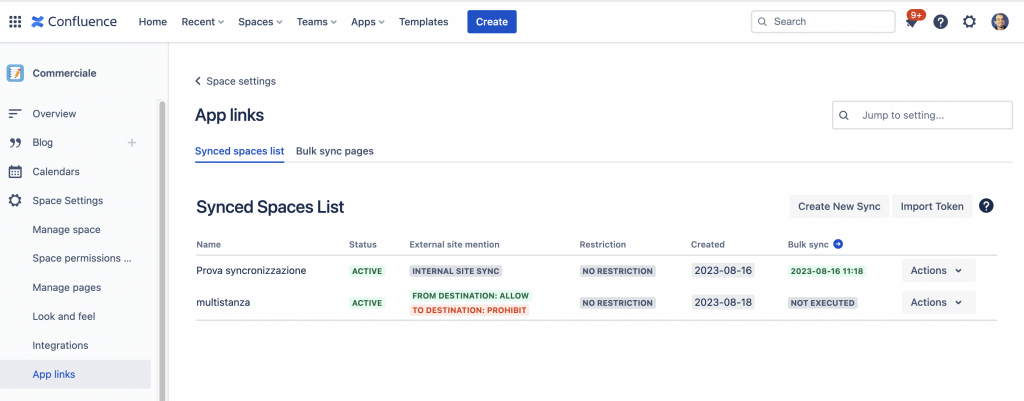
Anche l’esecuzione della parte multiistanza non presenta molti problemi:
Esecuzione sincronizzazione della multiistanza
Vediamo che il risultato mostrato è il medesimo.
Andando ad analizzare il tutto, vediamo che le operazioni hanno sincronizzato le pagine, ma ho notato una cosa: La Homepage degli Space non viene sincronizzata.
Infatti Il mio space ‘sorgente’ ha questa homepage
Lo Space ‘Commerciale’Lo space privato del mio utente, usato come Space destinazione
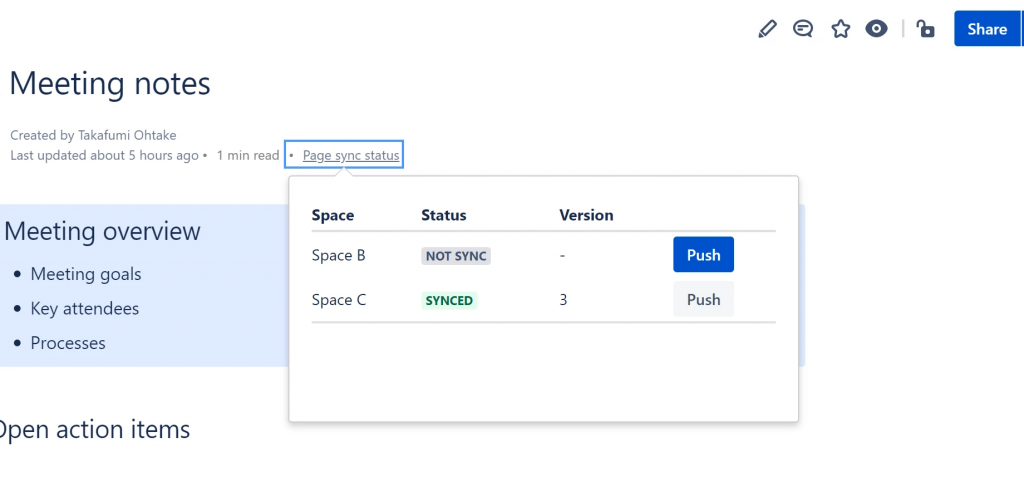
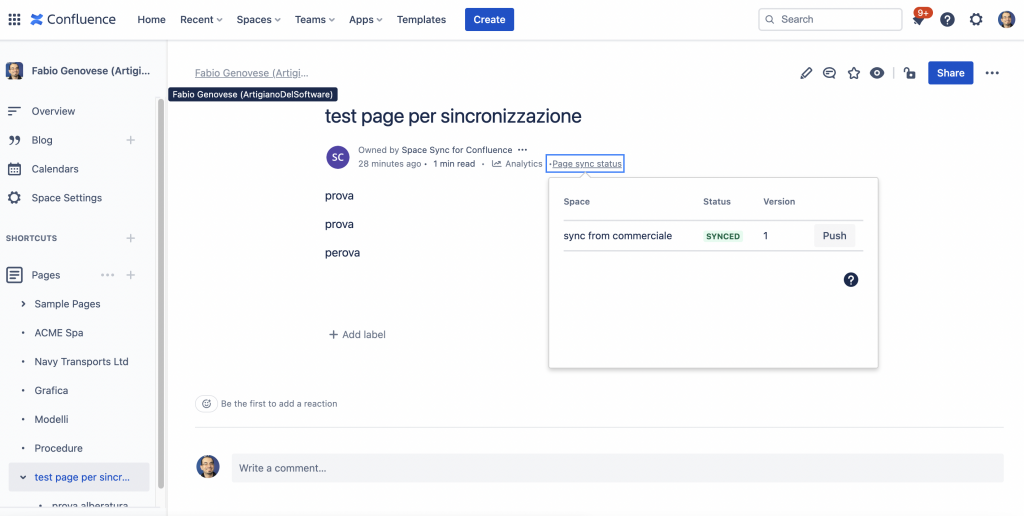
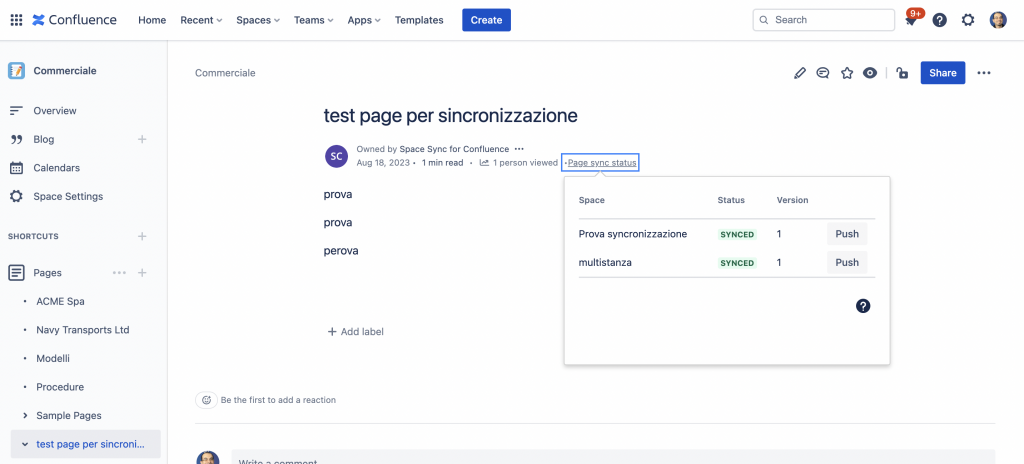
Osserviamo che per la Homepage non abbiamo a disposizione alcun menù che ci mostra lo stato della sincronizzazione. Mentre per le altre pagine abbiamo tale funzione disponibile.
La pagina con la dialog box indicante lo stato della sincronizzazione
La pagina con la Dialog box indicante lo stato della sincronizzazione
Vediamo la stessa pagina con la Dialog box sui due spazi distinti. Lo stesso risultato lo abbiamo anche quando usiamo la sincronizzazione su multistanza.
Risultato del test
Il risultato è sicuramente positivo ma ho notato alcune cose. Sono abbastanza sicuro del perché ci sia il comportamento che ho notato, ma voglio esserne sicuro e quindi lo evidenzio qui. Sono sicuro che gli autori dell’addon mi confermeranno le ipotesi.
La Home page dello Space non risulta inclusa nella sincronizzazione.
La sincronizzazione avviene copiando dallo Space origine verso lo Space destinazione
Non vedo i log delle operazioni, sia quando sono in esecuzione sia quando sono concluse le operazioni di sincronizzazione
La Homepage non viene sincronizzata ma ho il dubbio che, per come è organizzato Confluence, l’addon non riesca ancora ad eseguire questa operazione.
Eseguire la sincronizzazione in una direzione piuttosto che in entrambe le direzioni non lo vedo come un problema. Nello scenario che ci siamo posti come obiettivo, non è affatto un problema in quanto prima di usa una delle due istanze come Disaster Recovery e di conseguenza la sincronizzazione è in una direzione. Solo dopo può essere necessario sincronizzare nella direzione inversa in quanto, nel caso in cui la produzione non risponde, allora serve la sincronizzazione per ripristinare la produzione.
Cosa più importante sono i LOG. Il fatto che non riesca a vederli durante l’esecuzione e poi a sincronizzazione eseguita, lo vedo come un problema. Nel caso di malfunzionamento, occorre sempre capire la causa e i LOG sono fondamentali. Di conseguenza questo punto deve essere visto dai produttori dell’addon in modo da renderlo disponibile sempre e anche facilmente consultabile.
Conclusione
Il mio giudizio è sempre positivo: abbiamo un addon molto interessante, anche se non riusciamo in pieno ad implementare la soluzione del Disaster recovery. Il fatto di non riuscire a copiare per intero la pagina iniziale dello Space, non è proprio il massimo, ma non ci scoraggiamo. Abbiamo uno strumento in più da poter usare per i nostri obiettivi. Non abbiamo uno strumento che esegue perfettamente la sincronizzazione come ci aspettiamo, ma riusciamo comunque ad avere un risultato che ci si avvicina. In aggiunta ci vedo un altro possibile utilizzo: quando gestiamo una documentazione e abbiamo un processo abbastanza complesso di approvazione delle modifiche, quello che possiamo fare è usare 2 space: uno per la documentazione ufficiale e uno per redigere le modifiche. Quando la modifica viene approvata, questa viene sincronizzata con lo Space ufficiale. Quindi, questo ci deve insegnare a non abbandonare un addon se non esegue proprio quello che ci interessa, ma semplicemente lo andiamo ad applicare ad altre situazioni
Scrivo questo articolo quasi di getto e per rispondere alle ultime novità sul mondo delle Automazioni. Principalmente sulla parte Cloud di Jira. L’obiettivo è di fornire un quadro situazione per mostrare il funzionamento delle ultime novità e per indicare anche come poterle gestire correttamente. A tale proposito ho predisposto una regola di tipo didattico per descrivere meglio il funzionamento, ma andiamo con ordine.
Marzo 2023
Verso la fine del mese di marzo 2023 succedeva una cosa leggermente strana. Mi segnalavano che nelle istanze Cloud l’addon delle Automation risultava in TRIAL e sopratutto era ben staccato. Di conseguenza molti miei clienti si sono preoccupati (ma non solo loro).
Da un rapido controllo era emerso che Atlassian stava semplicemente integrando l’addon trasformandolo da addon esterno a addon di Sistema.
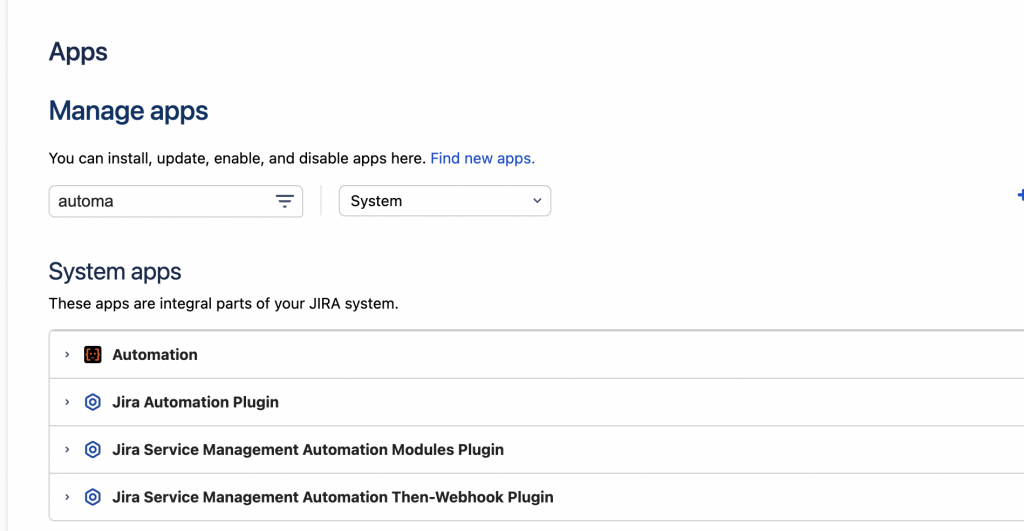
Infatti se andate a controllare, oggi lo troviamo come addon di sistema.
Quello che viene mostrato dalla sezione degli Addons-Apps
Fino a questo non ci sarebbe molto altro da dire… tuttavia abbiamo anche delle altre sorprese. L’integrazione si è portata dietro anche delle novità. Vediamole nel dettaglio:
Automation manuali
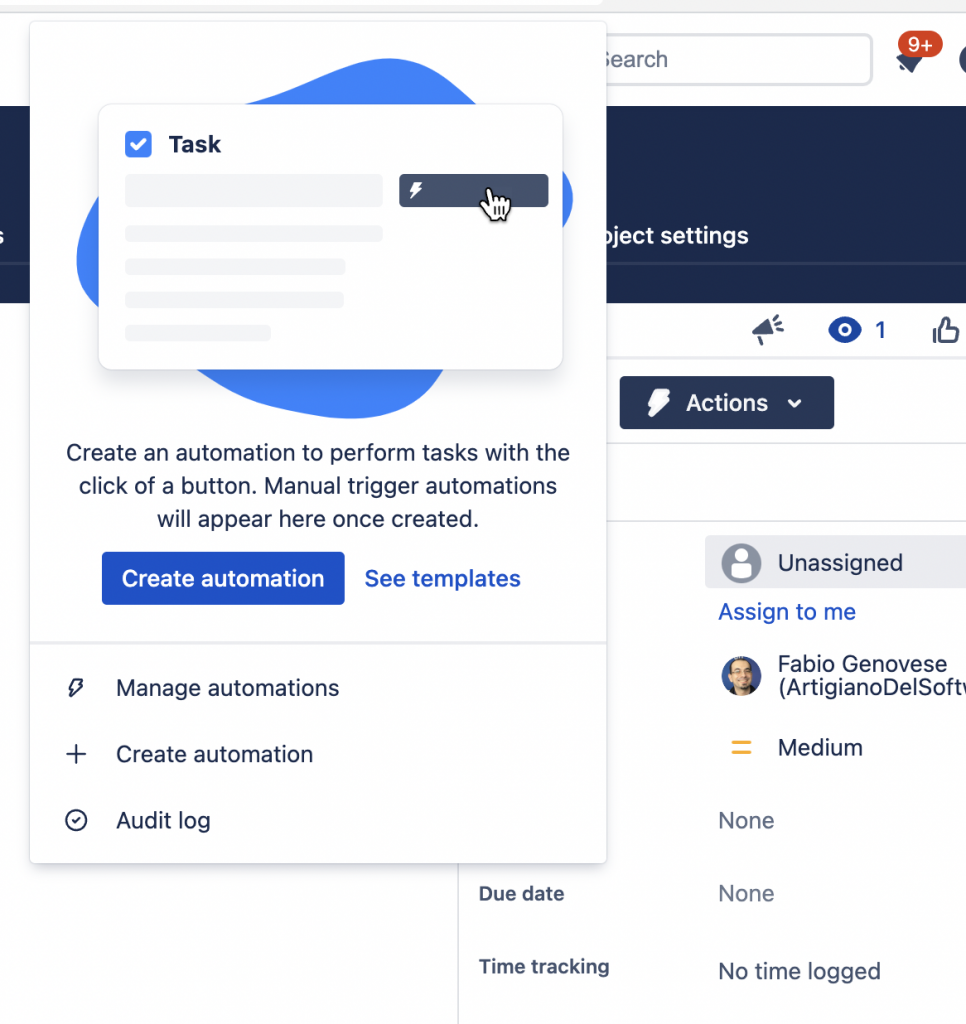
Una delle novità riguarda l’introduzione delle Automation manuali, ovvero richiamabili su richiesta dall’utente
Nuova funzionalità… ma…. 😮
Notiamo tuttavia una cosa molto molto … preoccupante. La combo che permette di richiamare questa nuova funzione è vicinissima alla combo del passaggio di stato. Molti mi hanno fatto notare (e sono perfettamente d’accordo) che la probabilità di selezionare la combo sbagliata è altissima. Devo riconoscere che la Atlassian ha introdotto una funzione importante, ma tempo che nella foga del momento non abbia ben calcolato dove inserire tale funzione, scegliendo una posizione infelice. Il mio suggerimento è di trattarla come le funzioni degli addon. Esiste la sezione dedicata alle Automation. Credo che sia meglio inserirla li
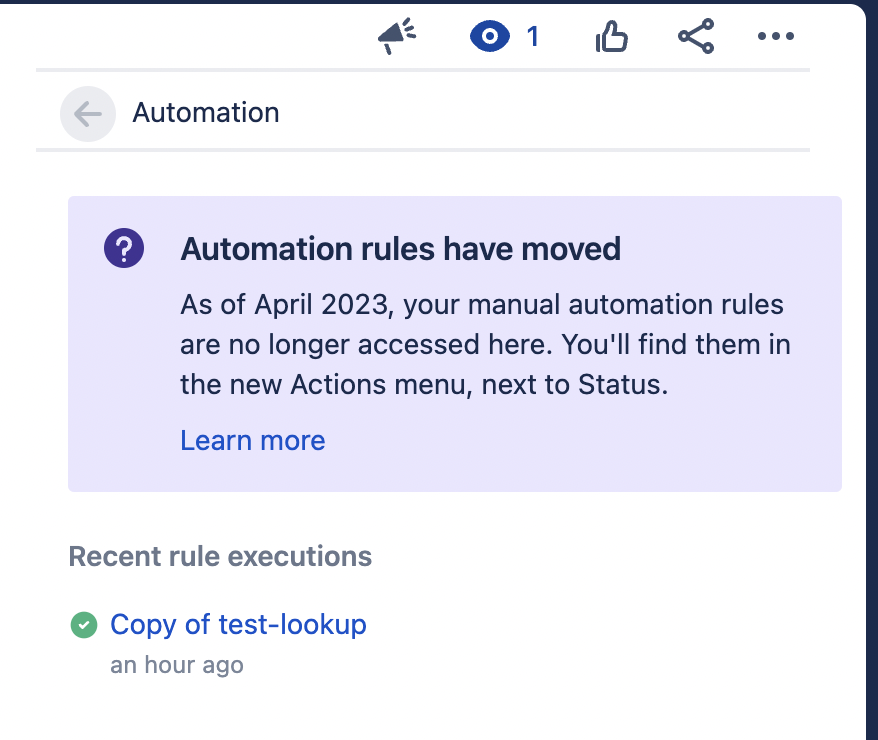
Notiamo che il messaggio ci da la ferale notizia
Non sono d’accordo con il messaggio. A mio giudizio questa sezione è quella ideale per gestire tale funzionalità.
Che altro?
Ci sono anche delle altre novità. Abbiamo a disposizione, sempre lato Automazioni, delle nuove funzionalità interne che ci permettono di poter gestire meglio delle …….. TABELLE DI LOOKUP
INTERESSANTE
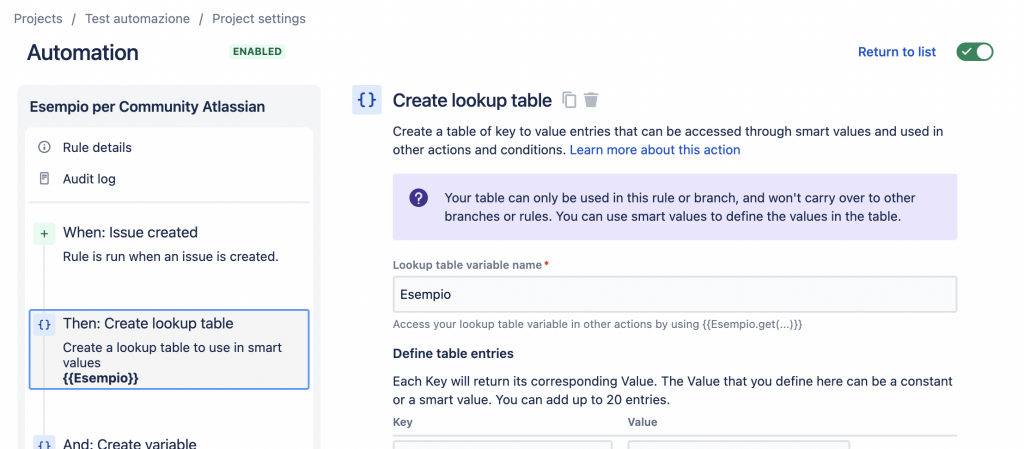
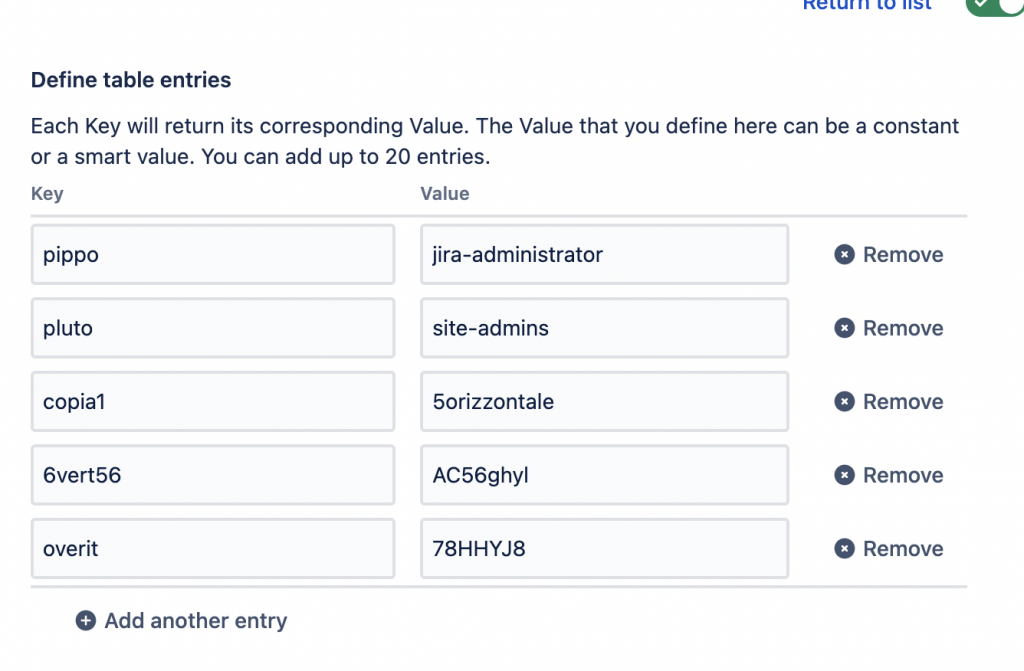
Vedo che ho catturato la vostra attenzione. Andiamo subito al sodo. Se infatti ricerchiamo tra le possibili azioni, abbiamo la possibilità di poter creare questa tabella:
Siamo ancora alle prime armi, ma possiamo subito vedere che il potenziale ci sta tutto. Anche se limitato a 20 entry massimo, possiamo impostare una serie di corrispondenze che possiamo sfruttare a nostro vantaggio.
Per richiamare le corrispondenze abbiamo a disposizione un semplice metodo. Infatti questa tabella si definisce come uno Smart Value. Basta semplicemente usare:
{{Esempio.get(issue.summary)}}
per richiamare la corrispondenza. In questo esempio abbiamo la possibilità di poter sfruttare anche degli altri Smart Value. Cosa molto importante.
Finalmente non avremo dei cicli IF THEN ELSE infinitiiiiiiii
Risultato, Conclusioni?
Semplice: Abbiamo la possibilità di poter gestire queste regole in maniera molto più semplice, ci liberiamo dalla schiavitù di blocchi IF-THEN-ELSE potenzialmente infiniti e abbastanza difficili da gestire. Ci permette di dare un ordine non indifferente e, come vediamo, anche di gestire al meglio queste situazioni. Ripeto. Siamo alle prime armi. Le novità non sono sempre cattive, ma hanno sempre del potenziale. Dobbiamo sempre vedere il potenziale, senza mai perdere di vista i punti di attenzione.