Database exporter – Come ti estraggo i dati dal Cloud
In questo post andremo ad esaminare un addon che ci permette di poter estrarre i dati dal Cloud in modo da permetterci di poter eseguire delle interrogazioni mirate.

Una premessa importante
Chi lavora con il Cloud sa perfettamente che quando vogliamo eseguire delle interrogazioni sui dati, la risposta è sempre una. Il seguente memo ce lo spiega

Sul Cloud non abbiamo alcuna possibilità: Ci è precluso l’accesso al database interno. Di conseguenza non possiamo fare nulla per lanciare query… almeno fino ad ora.
Abbiamo una soluzione
Inventato da Bob Swift ma adesso sotto il controllo della Appfire, abbiamo un addon che ci aiuta in tal senso, fornendoci la possibilità di costruire un simil-database su cui poter eseguire le nostre interrogazioni.
Questo addon è nato con l’obiettivo di ricostruire un database simile, rispetto a quello che avevamo a disposizione con la versione onPremise, e permettere agli utenti cloud di riuscire a ricostruire delle query ed interrogazioni.
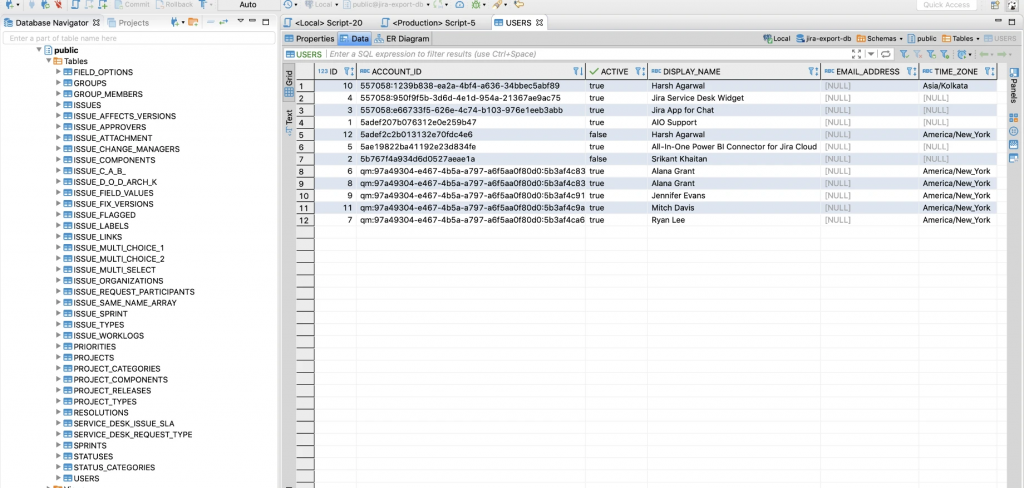
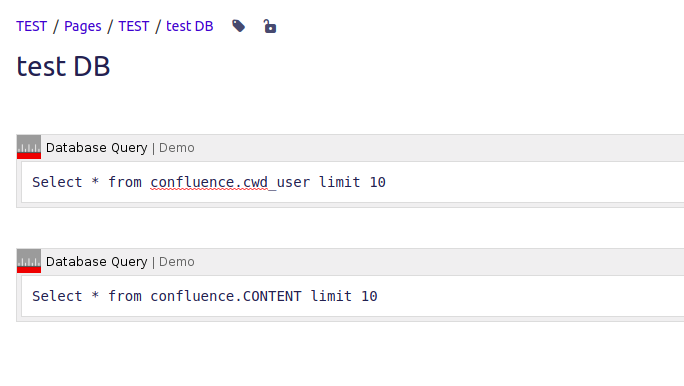
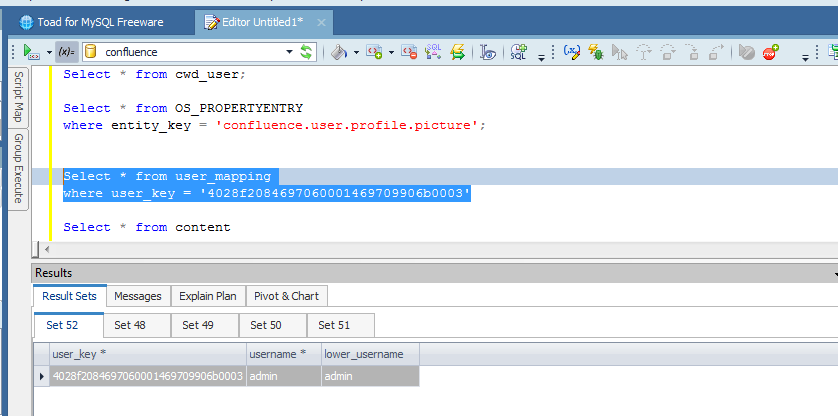
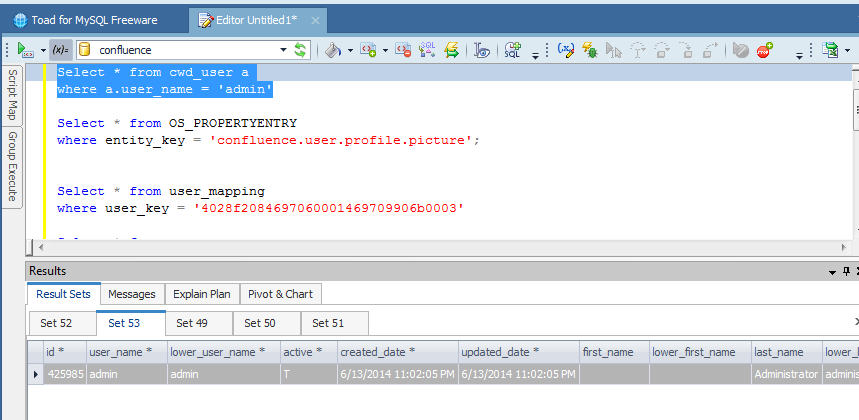
Come possiamo vedere dalla precedente immagine, riusciamo a ricostruire sia i dati della parte standard, compresi i campi custom. Dalla documentazione dell’addon abbiamo a disposizione anche uno schema dati che ci spiega come ricostruire le relazioni tra le varie tabelle:
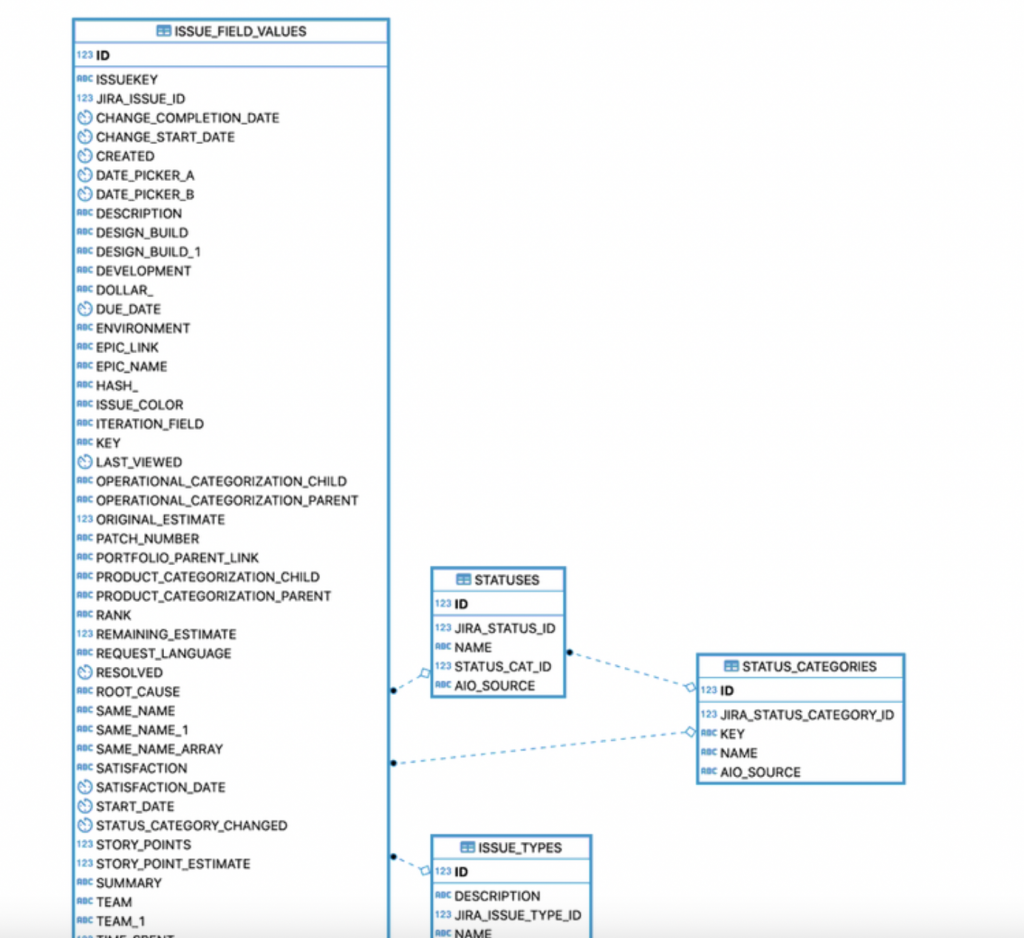
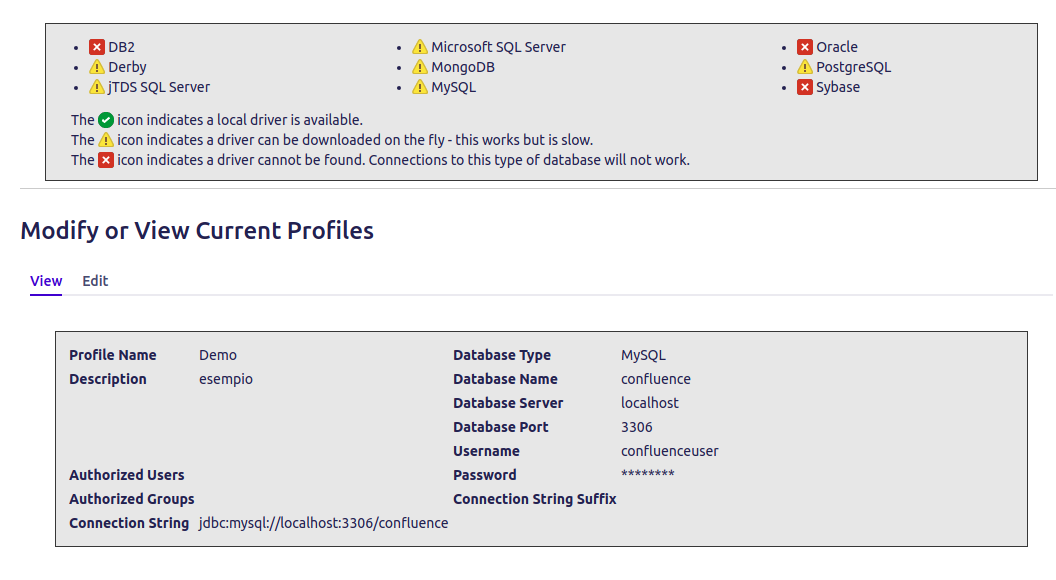
Possiamo, attraverso questo addon, ricostruire un simil-database (non è proprio il database effettivo: Teniamolo sempre a mente).
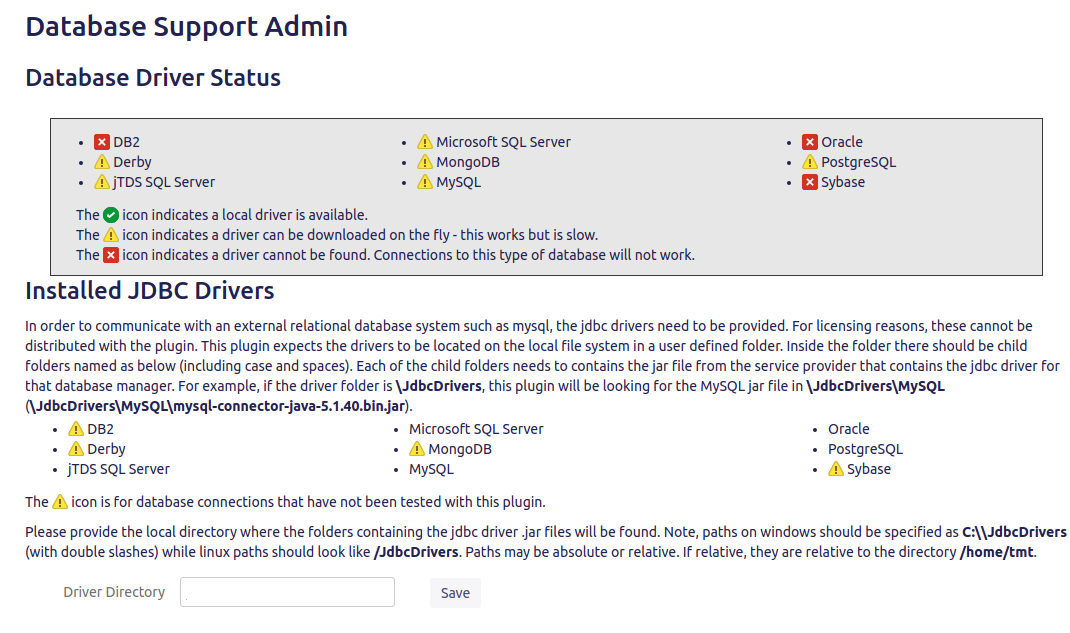
L’addon al momento permette di poter estrarre i dati direttamente su di un database Postgresql. Questo ci limita un pò i movimenti, ma non più di tanto. Se in azienda abbiamo uno standard che ci impone l’utilizzo di altre tipologie di Database (ad esempio: In azienda si usano database MS SQL Server). Tuttavia, usando dei server Linux, il problema viene risolto.
Punti di attenzione
Dobbiamo però tenere sempre a mente alcuni punti di attenzione. Ricordiamoci sempre che il nostro Cloud Atlassian è prevalentemente una macchina virtuale localizzata su Internet e di conseguenza abbiamo:
- Il nostro cloud deve poter accedere al database e di conseguenza questo deve essere raggiungibile da internet
- Essendo raggiungibile da internet, occorre che questo database sia gestito in maniera opportuna.
- Non possiamo esporre direttamente i nostri database verso internet
- Il database da usare deve essere un database che viene immediatamente blindato o svuotato non appena viene compilato
Come si può vedere non si tratta di semplici raccomandazioni, ma di punti di attenzione molto importanti. Se non li rispettiamo abbiamo dei problemi abbastanza seri.

Di conseguenza abbiamo molto da considerare.
La mia esperienza
Ho avuto modo di collaudare questo addon direttamente presso un mio cliente e posso dire che l’addon lavora in maniera egregia. Nel senso che i dati estratti sono effettivamente il clone dei dati. Ma vorrei fare alcune ulteriori considerazioni.
Abbiamo principalmente i dati dello standard
Non ci facciamo illusioni. Non riusciamo a disporre di tutti i dati come nel caso delle nostre installazioni onPremise. Infatti quando possibile, si accedeva anche ai dati degli addon semplicemente andando a leggere le tabelle con prefisso AO%, come riportato in questa documentazione ufficiale Atlassian.
In questo caso l’addon ricostruisce, con buona approssimazione, le informazioni standard e attraverso opportune query, riusciamo a leggere le informazioni che ci servono.
Solo alcuni addon sono disponibili
L’addon riesce a leggere i dati di alcuni addon, come TEMPO TIMESHEET, ma una cosa che ho notato è che le informazioni che sono scaricate sono sotto forma di un JSON che deve essere ‘lavorate’ per poter estrarre i dati che servono.
Possibile eseguire backup totali ed incrementali
E’ possibile eseguire entrambe le modalità. Nel mio caso, potrebbe essere utile eseguire un primo backup generale e poi tutti i backup incrementali. Questo aiuterebbe notevolmente
Conclusioni
Abbiamo un addon interessante ma che deve essere usato con tutti i crismi del caso. Possiamo estrarre i dati che ci interessano e fare le statistiche personalizzate del caso, anche se in ultima istanza suggerisco di appoggiarsi ad appositi tools che permettono di poter portare le informazioni di Jira su PowerBI o QLIK e consentono di gestire le statistiche molto meglio che con un semplice database da rimettere in piedi.
Come sempre riporto le mie indicazioni perché, questo sicuramente lo avrete compreso leggendo i miei post, che è sempre meglio avere più possibilità che solo una possibilità. La libertà di scelta è una arma molto potente che intendo sempre sfruttare e mettere a disposizione, anche quando eseguo le mie consulenze.
Reference
Maggiori informazioni sono reperibili alla pagina del Marketplace.