Breve panoramica sulle tabelle di JIRA
JIRA e le sue tabelle
In questo post, proseguiamo quanto iniziato su questo post, dove abbiamo fatto una breve panoramica delle tabelle di Confluence.
In questo caso, proviamo ad eseguire la stessa operazione presentata nel post precedente, ma facendo riferimento alle tabelle di JIRA. La seguente immagine riassume alcune delle tabelle di JIRA. Si rimanda alla sezione Reference per tutte le indicazioni sul caso.

Precauzioni
Si ribadiscono le stesse identiche precauzioni che sono state indicate nel precedente post. Fate sempre un backup dei dati, prima di procedere con qualsiasi operazione. In questo modo potete essere sicuri di poter operare in tutta sicurezza.
Iniziamo 🙂
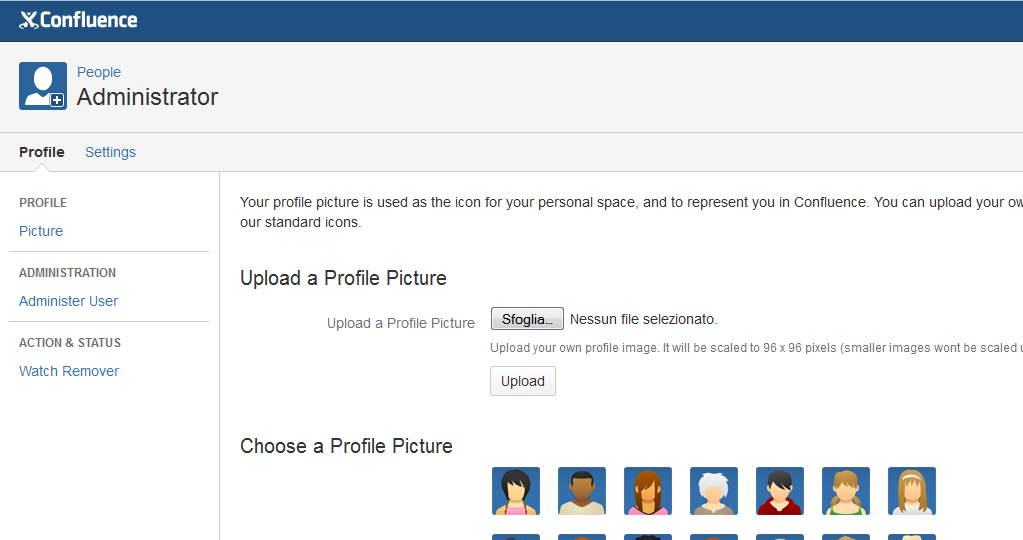
Cerchiamo di impostare un avatar di default differente da quello preimpostato. Partiamo da questa situazione:
Le tabelle che andiamo a referenziate sono le seguenti:
- cwd_user – Tabella contenente le informazioni degli utenti
- avatar – contenente gli avatar standard
- propertyentry – contenente le associazioni da utente ed avatar utilizzato
- propertynumber – contenente l’associazione con l’avatar collegato all’utente
Procediamo con la modifica
Aggiungiamo il nuovo avatar. Il file va caricato nella directory:
<Install-Dir>Atlassian-JiraWEBINFClassesAvatar
Supponiamo di utilizzare sempre l’icona del pinguino 🙂
![]()
Punto di attenzione. A differenza di Confluence, JIRA ha la necessità di avere anche una seconda icona, dimensione 24×24, la metà rispetto alla dimensione dell’avatar che si inserisce, ovvero 48×48, che viene referenziato e mostrato in alto a destra. Predisporre quindi un secondo avatar, nome pari a small_<nome_del_file_nuovo_avatar>.png e memorizzarlo nella stessa directory.
Quindi aggiungiamo un nuovo record, alla tabella avatar, con le indicazioni dell’icona nuova
![]()
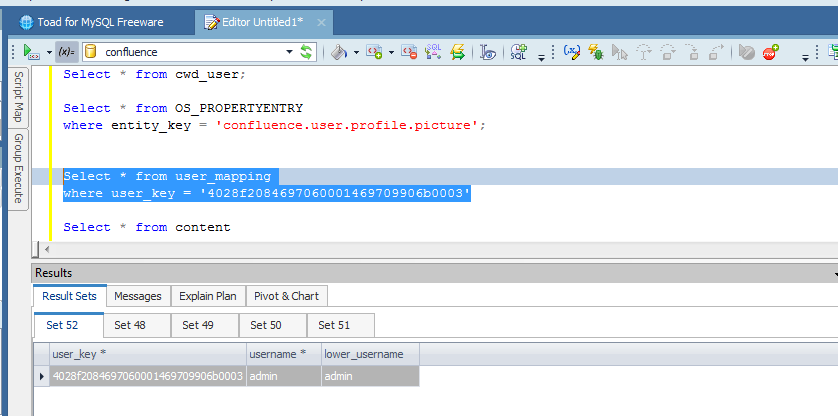
Dalla tabella cwd_user, identifichiamo l’utente in questione:
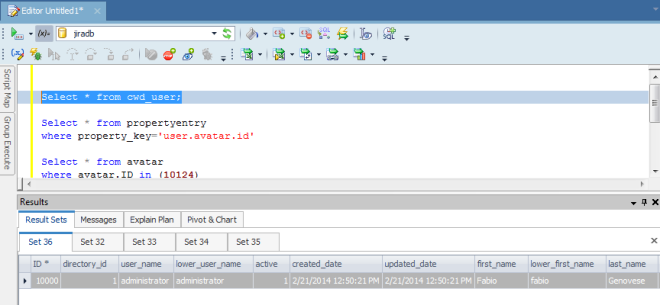
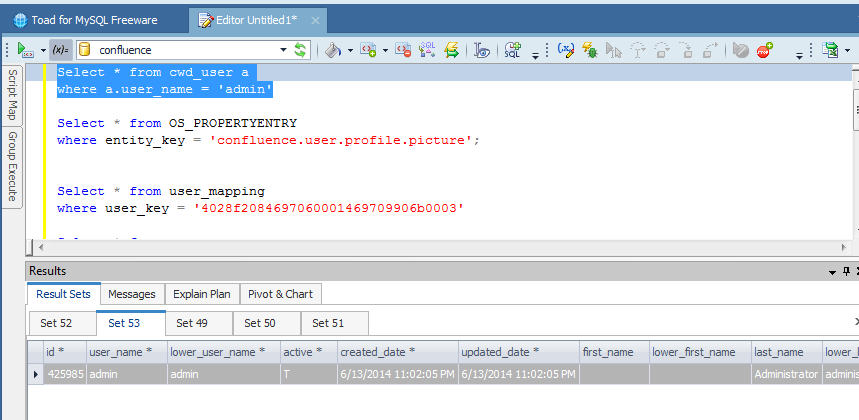
Dalla propertyentry ci ricaviamo l’ID per determinare la proprietà da andare a modificare, cercando per ENTITY_ID = ID USER e PROPERTY_KEY = ‘user.avatar.id’:
![]()
Quindi dalla propertynumber, ci ricaviamo l’ID dell’avatar utilizzato.
![]()
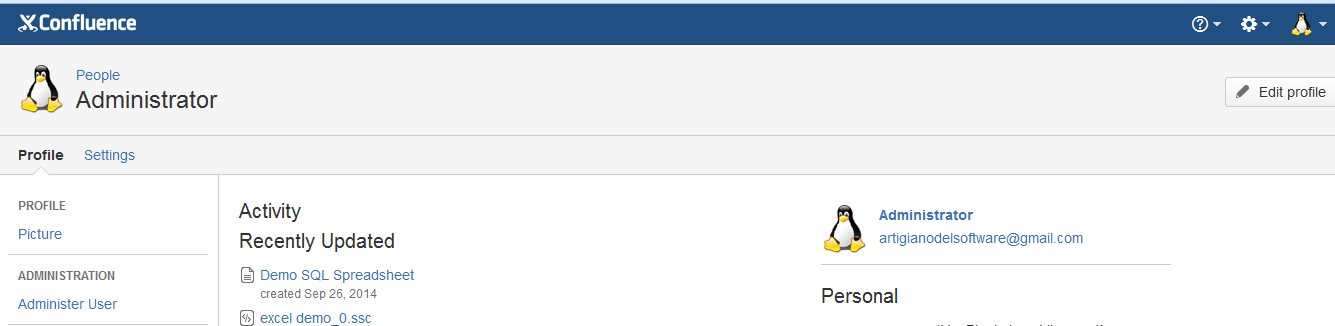
Inseriamo, nel campo propertyvalue, l’ID del nuovo avatar di default, e questo è il risultato:
Conclusioni
Con questo sistema riusciamo ad impostare il nuovo avatar di default in maniera semplice. Questo ci consente di poter eseguire una semplice modifica alla installazione, sostituendo gli avatar in modo semplice.
Se si vuole aggiungere un avatar non di default?
Fattibile, ma occorre agire da tutt’altra parte. In questo caso si dovrebbe memorizzare il file del nuovo avatar in altra directory, ovvero:
<JIRA-Home-dir>dataavatars
e si memorizzano in vari formati, principalmente il formato 48×48 ed il formato 24×24, che servono principalmente per tutte le funzionalità. La configurazione delle tabelle è la medesima. Il nome del file, come per il precedente esempio, deve essere preceduto dal nuovo ID assegnato alla tabella Avatar. Nei prossimi post vedremo altre informazioni sulle tabelle di JIRA.