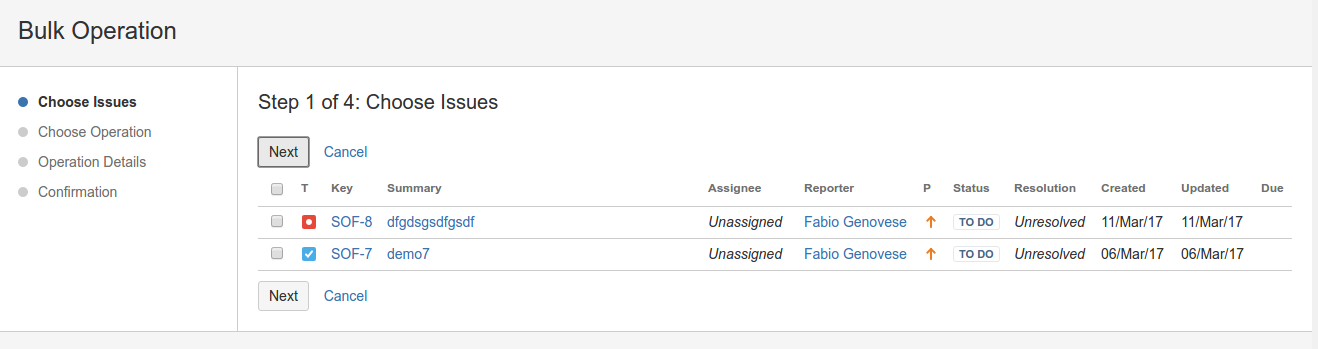
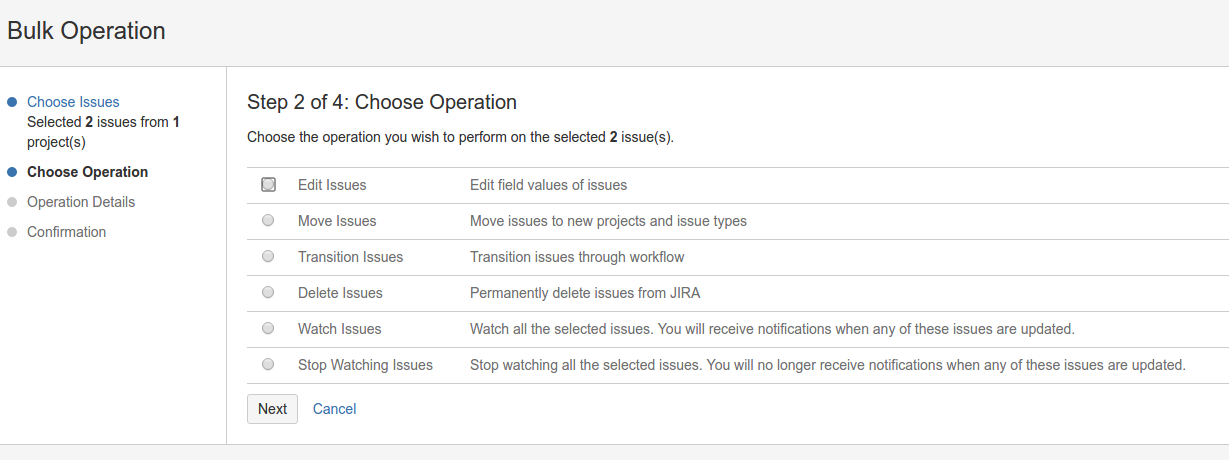
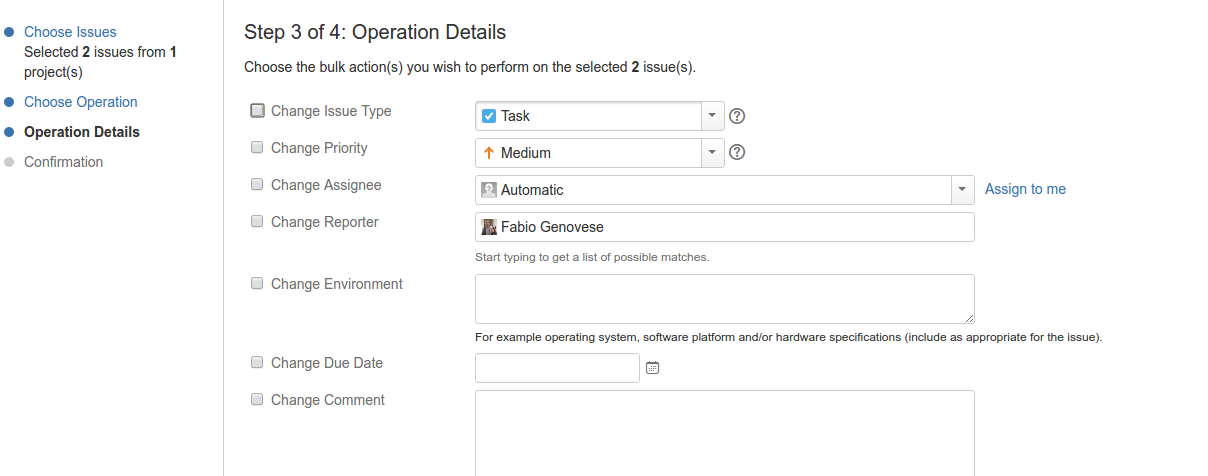
EasyBI – proviamolo
In questo post andremo ad testare questo addon particolarmente interessante. Approfitto per segnalare che a fine maggio si terranno gli EazyBI Days, dove saranno presentate le ultime novità di questo prodotto :-). Ho avuto il piacere di confrontarmi con loro durante il Summit Atlassian di Barcellona, di inizio maggio, ed è stata una occasione unica per confrontarsi e capire che cosa sia possibile fare con questi strumenti meravigliosi.


Installazione
Partiamo come sempre dalla installazione. In questo caso ci concentriamo sulla installazione per la versione Cloud che, come già sappiamo, presenta delle piccole differenze, ma non è affatto difficile da eseguire.
Configurazione
Proseguiamo la nostra esplorazione andando a vedere la configurazione dell’addon. Iniziamo dicendo che l’addon mette a disposizione una sezione dedicata che permette di configurare e definire tutto ciò che serve per le nostre analisi dei dati.
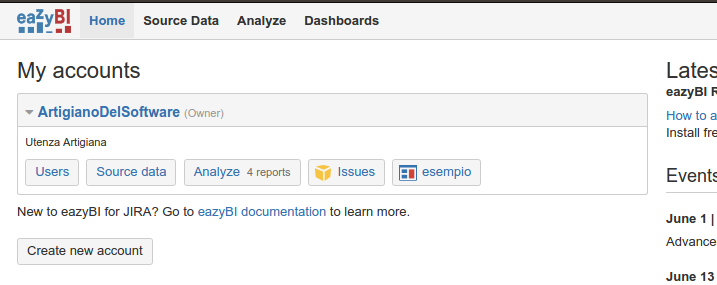
(questo ovviamente è l’esempio del mio account 🙂 )
Da li abbiamo le opzioni per poter:
- Definire le nostre sorgenti dati (Source Data)
- Impostare le nostre query (Analyze)
- Creare le nostre Dashboard, per condividere le informazioni 🙂
Andiamo ad esaminare ogni singola opzione 🙂
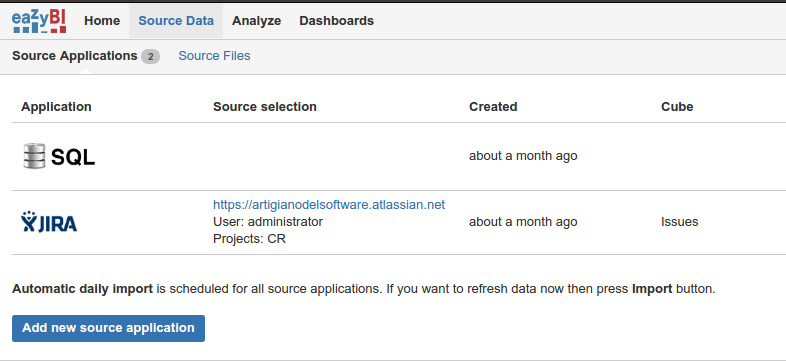
Possiamo definire tutte le sorgenti dati, a partire dai nostri progetti JIRA, come possiamo vedere dalla immagine precedente, alle sorgenti dati vere e proprie come database.
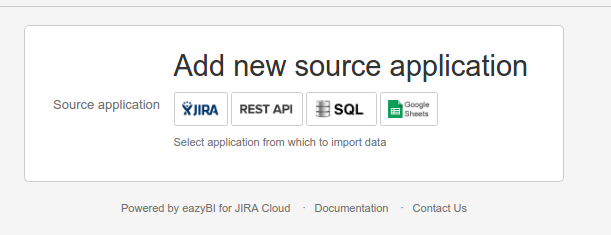
Vediamo, come mostrato in figura, che la versione cloud permette di connettersi a diverse fonti, tra le quali anche database. Se lo scegliamo, possiamo scegliere le seguenti fonti:
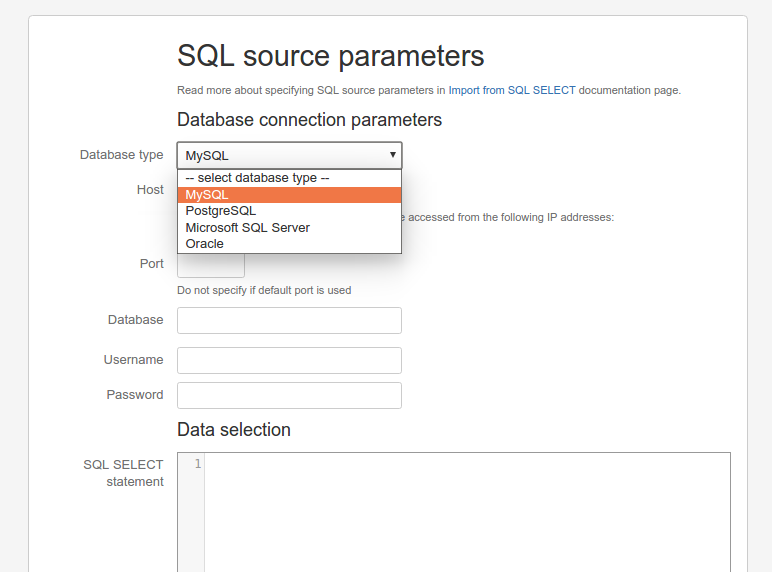
Questo non è affatto male 😉
Una volta definite le fonti dati, possiamo creare le nostre interrogazioni, il tutto in maniera totalmente visuale 🙂
Da questo punto in avanti andiamo a testare il tutto 🙂
Test
Una volta definite le nostre interrogazioni, possiamo usarle sia nella dashboard di JIRA, da dove possiamo visionare direttamente i nostri dati, come possiamo vedere facilmente.
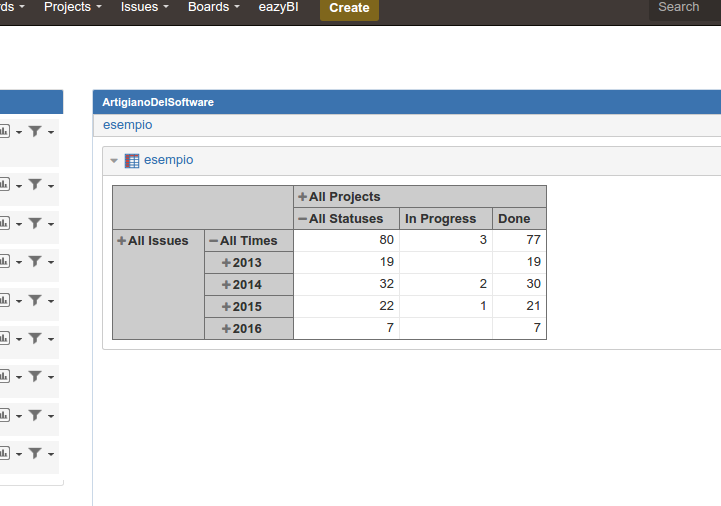
Una delle possibilità offerte da questi prodotti è quella di pubblicare questi report anche su Confluence, in maniera abbastanza semplice e diretta. Utilizzando un apposito Addon per l’ambiente cloud, è possibile arrivare a pubblicare i report nelle pagine.
L’aggiunta viene eseguita in maniera semplicissima, come mostrato in figura:
 Aggiungendo l’addon Dashboard o Report, ed impostando quale report andare a visualizzare:
Aggiungendo l’addon Dashboard o Report, ed impostando quale report andare a visualizzare:

otteniamo il risultato atteso. Nel nostro caso, abbiamo installato l’addon (in maniera simile a quanto descritto in precedenza) ed il risultato è stato il seguente:
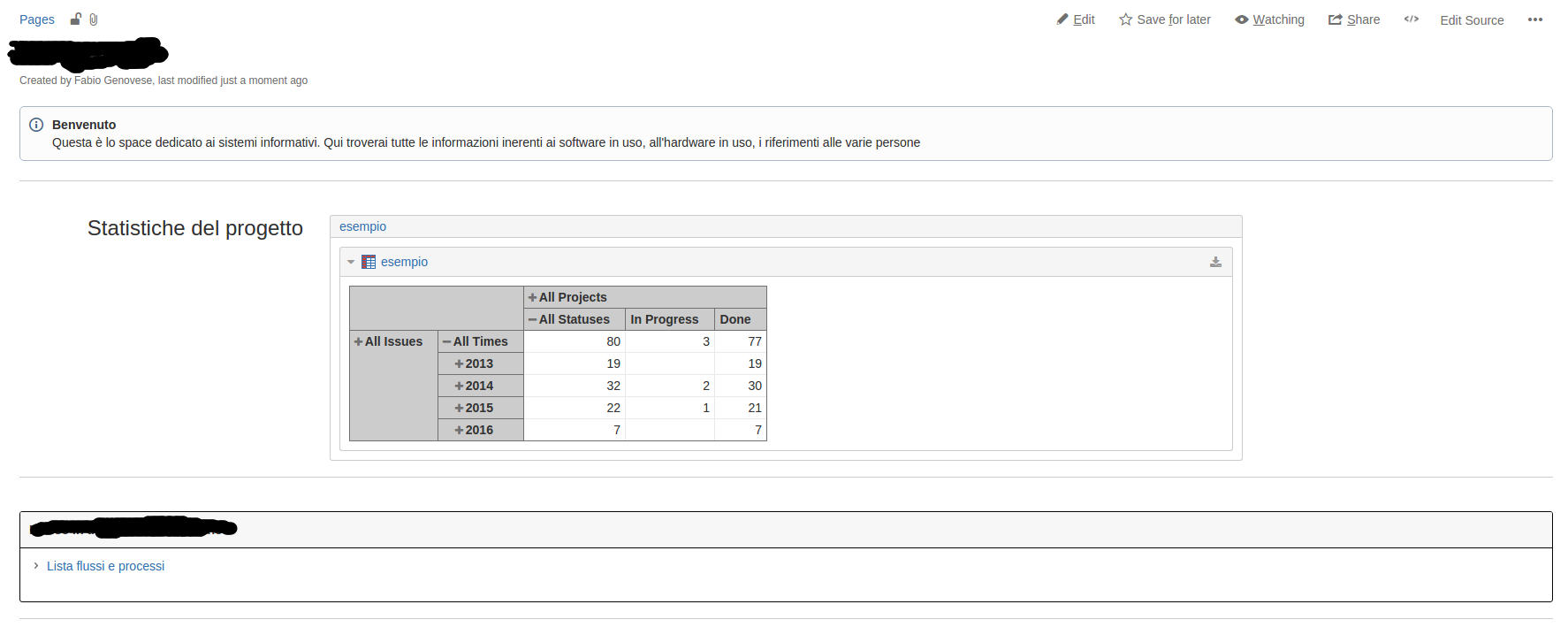
Quindi con pochissimo sforzo abbiamo pubblicato le nostre statistiche direttamente su Confluence molto semplicemente.
Conclusioni
Statistiche, dati, BI tutto all’interno di JIRA e dei prodotti Atlassian. Questo addon è una sorpresa dietro l’altra. bbiamo a disposizione tutto ciò che ci serve per poter arrivare a gestire i nostri dati direttamente dove serve.
Reference
Maggiori dettagli sono reperibili alla pagina del marketplace.